

- 与基于预先存在的轨迹完整数据集进行评估相比,更容易上手
- 从初始查询到成功或失败解决的端到端覆盖
- 能够检测应用在多次迭代中的重复行为或上下文丢失
openevals 包来模拟多轮交互并进行评估,该包包含预构建的评估器和其他用于评估AI应用的便捷资源。它还将使用OpenAI模型,尽管您也可以使用其他提供商。
设置
首先,确保您已安装所需的依赖项:pip install -U langsmith openevals
npm install langsmith openevals
如果您使用
yarn 作为包管理器,您还需要手动安装 @langchain/core 作为 openevals 的对等依赖项。对于一般的LangSmith评估,这不是必需的。export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="<Your LangSmith API key>"
export OPENAI_API_KEY="<Your OpenAI API key>"
运行模拟
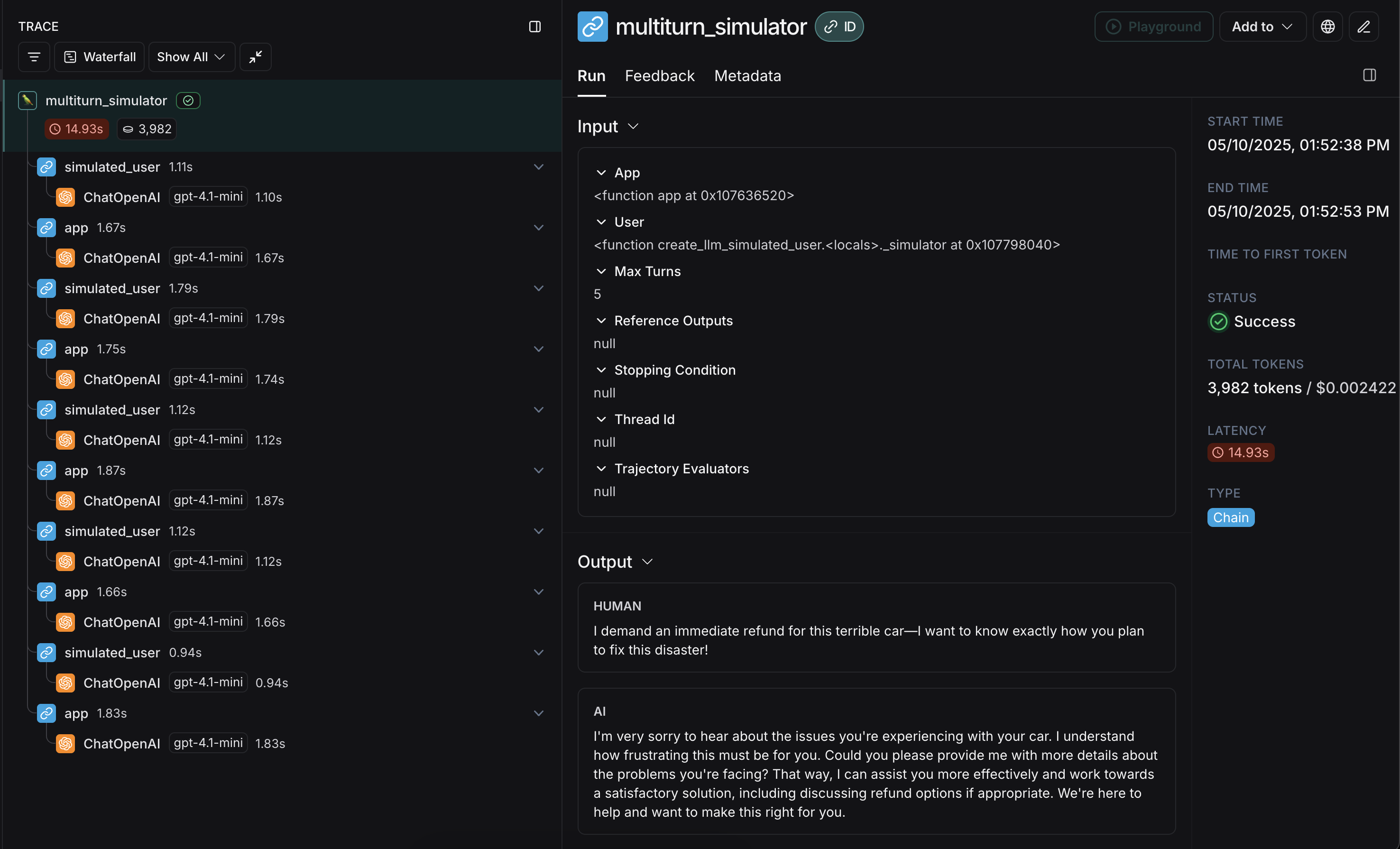
要开始,您需要两个主要组件:app:您的应用程序,或一个包装它的函数。必须接受单个聊天消息(包含 “role” 和 “content” 键的字典)作为输入参数,以及一个thread_id作为关键字参数。应接受其他关键字参数,因为未来版本可能会添加更多。返回一个至少包含 role 和 content 键的聊天消息作为输出。user:模拟用户。在本指南中,我们将使用一个导入的预构建函数create_llm_simulated_user,它使用LLM生成用户响应,但您也可以创建自己的模拟用户。
openevals 中的模拟器在每一轮中将单个聊天消息从 user 传递给您的 app。因此,如果需要,您应该根据 thread_id 在内部有状态地跟踪当前历史记录。
以下是一个模拟多轮客户支持交互的示例。本指南使用一个简单的聊天应用,该应用包装了对OpenAI聊天补全API的单次调用,但在这里您将调用您的应用程序或代理。在此示例中,我们的模拟用户扮演一个特别具有攻击性的客户角色:
from openevals.simulators import run_multiturn_simulation, create_llm_simulated_user
from openevals.types import ChatCompletionMessage
from langsmith.wrappers import wrap_openai
from openai import OpenAI
# Wrap OpenAI client for tracing
client = wrap_openai(OpenAI())
history = {}
# Your application logic
def app(inputs: ChatCompletionMessage, *, thread_id: str, **kwargs):
if thread_id not in history:
history[thread_id] = []
history[thread_id].append(inputs)
# inputs is a message object with role and content
res = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[
{
"role": "system",
"content": "You are a patient and understanding customer service agent.",
},
] + history[thread_id],
)
response_message = res.choices[0].message
history[thread_id].append(response_message)
return response_message
user = create_llm_simulated_user(
system="You are an aggressive and hostile customer who wants a refund for their car.",
model="openai:gpt-5.4-mini",
)
# Run the simulation directly with the new function
simulator_result = run_multiturn_simulation(
app=app,
user=user,
max_turns=5,
)
print(simulator_result)
import { OpenAI } from "openai";
import { wrapOpenAI } from "langsmith/wrappers/openai";
import {
createLLMSimulatedUser,
runMultiturnSimulation,
type ChatCompletionMessage,
} from "openevals";
// Wrap OpenAI client for tracing
const client = wrapOpenAI(new OpenAI());
const history = {};
// Your application logic
const app = async ({ inputs, threadId }: { inputs: ChatCompletionMessage, threadId: string }) => {
if (history[threadId] === undefined) {
history[threadId] = [];
}
history[threadId].push(inputs);
const res = await client.chat.completions.create({
model: "gpt-5.4-mini",
messages: [
{
role: "system",
content:
"You are a patient and understanding customer service agent.",
},
inputs,
],
});
const responseMessage = res.choices[0].message;
history[threadId].push(responseMessage);
return res.choices[0].message;
};
const user = createLLMSimulatedUser({
system: "You are an aggressive and hostile customer who wants a refund for their car.",
model: "openai:gpt-5.4-mini",
});
const result = await runMultiturnSimulation({
app,
user,
maxTurns: 5,
});
console.log(result);
{
"trajectory": [
{
"role": "user",
"content": "This piece of junk car is a complete disaster! I demand a full refund immediately. How dare you sell me such a worthless vehicle!",
"id": "chatcmpl-BUpXa07LaM7wXbyaNnng1Gtn5Dsbh"
},
{
"role": "assistant",
"content": "I'm really sorry to hear about your experience and understand how frustrating this must be. I'd like to help resolve this issue as smoothly as possible. Could you please provide some details about the problem with the vehicle? Once I have more information, I'll do my best to assist you with a solution, whether it's a refund or other options. Thank you for your patience.",
"refusal": null,
"annotations": [],
"id": "d7520f6a-7cf8-46f8-abe4-7df04f134482"
},
"...",
{
"role": "assistant",
"content": "I truly understand your frustration and sincerely apologize for the inconvenience you've experienced.\n\nPlease allow me a moment to review your case, and I will do everything I can to expedite your refund. Your patience is greatly appreciated, and I am committed to resolving this matter to your satisfaction.",
"refusal": null,
"annotations": [],
"id": "a0536d4f-9353-4cfa-84df-51c8d29e076d"
}
]
}
user 生成一个初始查询,然后来回传递响应聊天消息,直到达到 max_turns(或者,您可以传递一个 stopping_condition,它接受当前轨迹并返回 True 或 False - 更多信息请参见 OpenEvals README)。返回值是构成对话轨迹的最终聊天消息列表。
有多种方法可以配置模拟用户,例如让它在模拟的前几轮返回固定响应,以及整个模拟的配置。有关完整详情,请查看 OpenEvals README。
app 和 user 的响应交错出现:
在LangSmith实验中运行
您可以将多轮模拟的结果作为LangSmith实验的一部分,以跟踪随时间变化的性能和进展。对于这些部分,熟悉LangSmith的pytest(仅限Python)、Vitest/Jest(仅限JS)或 evaluate 运行器中的至少一个会很有帮助。
使用 pytest 或 Vitest/Jest
请参阅以下指南,了解如何使用LangSmith与测试框架的集成来设置评估:
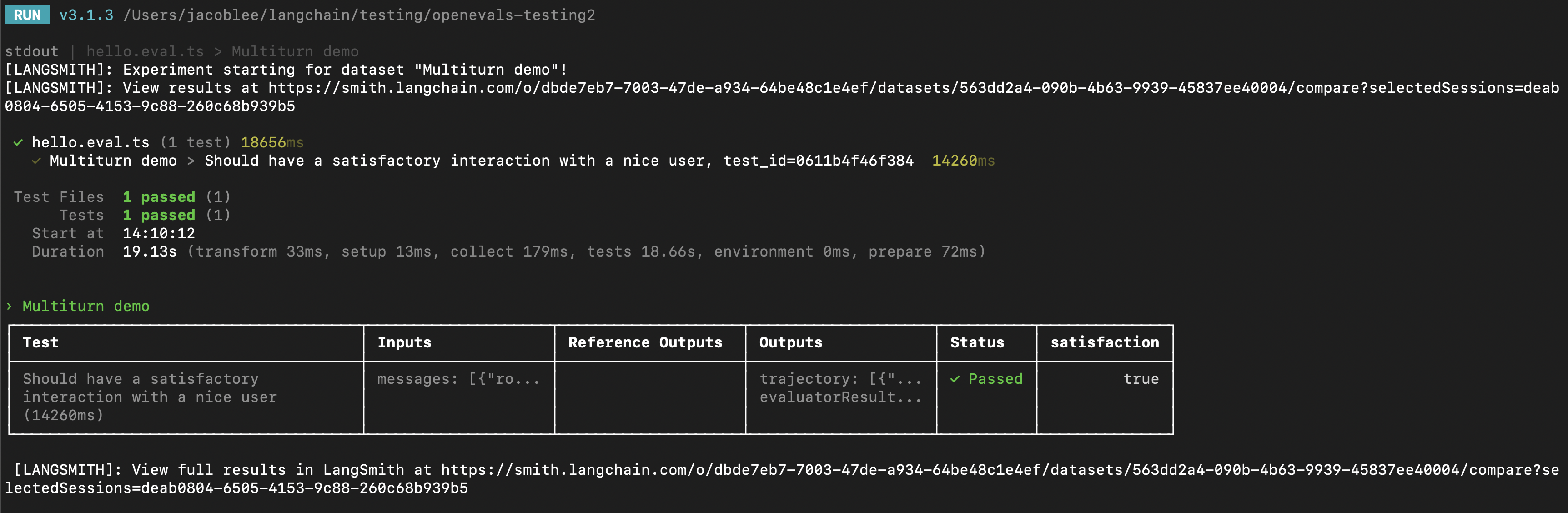
trajectory_evaluators 参数传入。这些评估器将在模拟结束时运行,接受最终的聊天消息列表作为 outputs 关键字参数。因此,您传递的 trajectory_evaluator 必须接受此关键字参数。
from openevals.simulators import run_multiturn_simulation, create_llm_simulated_user
from openevals.llm import create_llm_as_judge
from openevals.types import ChatCompletionMessage
from langsmith import testing as t
from langsmith.wrappers import wrap_openai
from openai import OpenAI
import pytest
@pytest.mark.langsmith
def test_multiturn_message_with_openai():
inputs = {"role": "user", "content": "I want a refund for my car!"}
t.log_inputs(inputs)
# Wrap OpenAI client for tracing
client = wrap_openai(OpenAI())
history = {}
def app(inputs: ChatCompletionMessage, *, thread_id: str):
if thread_id not in history:
history[thread_id] = []
history[thread_id] = history[thread_id] + [inputs]
res = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{
"role": "system",
"content": "You are a patient and understanding customer service agent.",
}
]
+ history[thread_id],
)
response = res.choices[0].message
history[thread_id].append(response)
return response
user = create_llm_simulated_user(
system="You are a nice customer who wants a refund for their car.",
model="openai:gpt-5.4-nano",
fixed_responses=[
inputs,
],
)
trajectory_evaluator = create_llm_as_judge(
model="openai:o3-mini",
prompt="Based on the below conversation, was the user satisfied?\n{outputs}",
feedback_key="satisfaction",
)
res = run_multiturn_simulation(
app=app,
user=user,
trajectory_evaluators=[trajectory_evaluator],
max_turns=5,
)
t.log_outputs(res)
# Optionally, assert that the evaluator scored the interaction as satisfactory.
# This will cause the overall test case to fail if "score" is False.
assert res["evaluator_results"][0]["score"]
import { OpenAI } from "openai";
import { wrapOpenAI } from "langsmith/wrappers/openai";
import * as ls from "langsmith/vitest";
import { expect } from "vitest";
// import * as ls from "langsmith/jest";
// import { expect } from "@jest/globals";
import {
createLLMSimulatedUser,
runMultiturnSimulation,
createLLMAsJudge,
type ChatCompletionMessage,
} from "openevals";
const client = wrapOpenAI(new OpenAI());
ls.describe("Multiturn demo", () => {
ls.test(
"Should have a satisfactory interaction with a nice user",
{
inputs: {
messages: [{ role: "user" as const, content: "I want a refund for my car!" }],
},
},
async ({ inputs }) => {
const history = {};
// Create a custom app function
const app = async (
{ inputs, threadId }: { inputs: ChatCompletionMessage, threadId: string }
) => {
if (history[threadId] === undefined) {
history[threadId] = [];
}
history[threadId].push(inputs);
const res = await client.chat.completions.create({
model: "gpt-5.4-nano",
messages: [
{
role: "system",
content:
"You are a patient and understanding customer service agent",
},
inputs,
],
});
const responseMessage = res.choices[0].message;
history[threadId].push(responseMessage);
return responseMessage;
};
const user = createLLMSimulatedUser({
system:
"You are a nice customer who wants a refund for their car.",
model: "openai:gpt-5.4-nano",
fixedResponses: inputs.messages,
});
const trajectoryEvaluator = createLLMAsJudge({
model: "openai:o3-mini",
prompt:
"Based on the below conversation, was the user satisfied?\n{outputs}",
feedbackKey: "satisfaction",
});
const result = await runMultiturnSimulation({
app,
user,
trajectoryEvaluators: [trajectoryEvaluator],
maxTurns: 5,
});
ls.logOutputs(result);
// Optionally, assert that the evaluator scored the interaction as satisfactory.
// This will cause the overall test case to fail if "score" is false.
expect(result.evaluatorResults[0].score).toBe(true);
}
);
});
trajectory_evaluators 返回的反馈,并将其添加到实验中。另请注意,测试用例在模拟用户上使用了 fixed_responses 参数,以特定输入开始对话,您可以记录此输入并将其作为存储数据集的一部分。
您可能还会发现,将模拟用户的系统提示作为记录数据集的一部分会很方便。
使用 evaluate
您也可以使用 evaluate 运行器来评估模拟的多轮交互。这与 pytest/Vitest/Jest 示例在以下方面会有所不同:
- 模拟应作为您
target函数的一部分,并且您的目标函数应返回最终轨迹。- 这将使轨迹成为LangSmith将传递给评估器的
outputs。
- 这将使轨迹成为LangSmith将传递给评估器的
- 您不应使用
trajectory_evaluators参数,而应将评估器作为参数传递给evaluate()方法。 - 您需要一个现有的输入和(可选的)参考轨迹数据集。
from openevals.simulators import run_multiturn_simulation, create_llm_simulated_user
from openevals.llm import create_llm_as_judge
from openevals.types import ChatCompletionMessage
from langsmith.wrappers import wrap_openai
from langsmith import Client
from openai import OpenAI
ls_client = Client()
examples = [
{
"inputs": {
"messages": [{ "role": "user", "content": "I want a refund for my car!" }]
},
},
]
dataset = ls_client.create_dataset(dataset_name="multiturn-starter")
ls_client.create_examples(
dataset_id=dataset.id,
examples=examples,
)
trajectory_evaluator = create_llm_as_judge(
model="openai:o3-mini",
prompt="Based on the below conversation, was the user satisfied?\n{outputs}",
feedback_key="satisfaction",
)
def target(inputs: dict):
# Wrap OpenAI client for tracing
client = wrap_openai(OpenAI())
history = {}
def app(next_message: ChatCompletionMessage, *, thread_id: str):
if thread_id not in history:
history[thread_id] = []
history[thread_id] = history[thread_id] + [next_message]
res = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{
"role": "system",
"content": "You are a patient and understanding customer service agent.",
}
]
+ history[thread_id],
)
response = res.choices[0].message
history[thread_id].append(response)
return response
user = create_llm_simulated_user(
system="You are a nice customer who wants a refund for their car.",
model="openai:gpt-5.4-nano",
fixed_responses=inputs["messages"],
)
res = run_multiturn_simulation(
app=app,
user=user,
max_turns=5,
)
return res["trajectory"]
results = ls_client.evaluate(
target,
data=dataset.name,
evaluators=[trajectory_evaluator],
)
import { OpenAI } from "openai";
import { Client } from "langsmith";
import { wrapOpenAI } from "langsmith/wrappers/openai";
import { evaluate } from "langsmith/evaluation";
import {
createLLMSimulatedUser,
runMultiturnSimulation,
createLLMAsJudge,
type ChatCompletionMessage,
} from "openevals";
const lsClient = new Client();
const inputs = {
messages: [
{
role: "user",
content: "I want a refund for my car!",
},
],
};
const datasetName = "Multiturn";
const dataset = await lsClient.createDataset(datasetName);
await lsClient.createExamples([{ inputs, dataset_id: dataset.id }]);
const trajectoryEvaluator = createLLMAsJudge({
model: "openai:o3-mini",
prompt:
"Based on the below conversation, was the user satisfied?\n{outputs}",
feedbackKey: "satisfaction",
});
const client = wrapOpenAI(new OpenAI());
const target = async (inputs: { messages: ChatCompletionMessage[]}) => {
const history = {};
// Create a custom app function
const app = async (
{ inputs: nextMessage, threadId }: { inputs: ChatCompletionMessage, threadId: string }
) => {
if (history[threadId] === undefined) {
history[threadId] = [];
}
history[threadId].push(nextMessage);
const res = await client.chat.completions.create({
model: "gpt-5.4-nano",
messages: [
{
role: "system",
content:
"You are a patient and understanding customer service agent",
},
nextMessage,
],
});
const responseMessage = res.choices[0].message;
history[threadId].push(responseMessage);
return responseMessage;
};
const user = createLLMSimulatedUser({
system:
"You are a nice customer who wants a refund for their car.",
model: "openai:gpt-5.4-nano",
fixedResponses: inputs.messages,
});
const result = await runMultiturnSimulation({
app,
user,
maxTurns: 5,
});
return result.trajectory;
};
await evaluate(target, {
data: datasetName,
evaluators: [trajectoryEvaluator],
});
修改模拟用户角色
上述示例对所有输入示例使用相同的模拟用户角色,该角色由传递给create_llm_simulated_user 的 system 参数定义。如果您希望为数据集中的特定项目使用不同的角色,您可以更新数据集示例,使其也包含一个带有所需 system 提示的额外字段,然后在创建模拟用户时传递该字段,如下所示:
from openevals.simulators import run_multiturn_simulation, create_llm_simulated_user
from openevals.llm import create_llm_as_judge
from openevals.types import ChatCompletionMessage
from langsmith.wrappers import wrap_openai
from langsmith import Client
from openai import OpenAI
ls_client = Client()
examples = [
{
"inputs": {
"messages": [{ "role": "user", "content": "I want a refund for my car!" }],
"simulated_user_prompt": "You are an angry and belligerent customer who wants a refund for their car."
},
},
{
"inputs": {
"messages": [{ "role": "user", "content": "Please give me a refund for my car." }],
"simulated_user_prompt": "You are a nice customer who wants a refund for their car.",
},
}
]
dataset = ls_client.create_dataset(dataset_name="multiturn-with-personas")
ls_client.create_examples(
dataset_id=dataset.id,
examples=examples,
)
trajectory_evaluator = create_llm_as_judge(
model="openai:o3-mini",
prompt="Based on the below conversation, was the user satisfied?\n{outputs}",
feedback_key="satisfaction",
)
def target(inputs: dict):
# Wrap OpenAI client for tracing
client = wrap_openai(OpenAI())
history = {}
def app(next_message: ChatCompletionMessage, *, thread_id: str):
if thread_id not in history:
history[thread_id] = []
history[thread_id] = history[thread_id] + [next_message]
res = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{
"role": "system",
"content": "You are a patient and understanding customer service agent.",
}
]
+ history[thread_id],
)
response = res.choices[0].message
history[thread_id].append(response)
return response
user = create_llm_simulated_user(
system=inputs["simulated_user_prompt"],
model="openai:gpt-5.4-nano",
fixed_responses=inputs["messages"],
)
res = run_multiturn_simulation(
app=app,
user=user,
max_turns=5,
)
return res["trajectory"]
results = ls_client.evaluate(
target,
data=dataset.name,
evaluators=[trajectory_evaluator],
)
import { OpenAI } from "openai";
import { Client } from "langsmith";
import { wrapOpenAI } from "langsmith/wrappers/openai";
import { evaluate } from "langsmith/evaluation";
import {
createLLMSimulatedUser,
runMultiturnSimulation,
createLLMAsJudge,
type ChatCompletionMessage,
} from "openevals";
const lsClient = new Client();
const datasetName = "Multiturn with personas";
const dataset = await lsClient.createDataset(datasetName);
const examples = [{
inputs: {
messages: [
{
role: "user",
content: "I want a refund for my car!",
},
],
simulated_user_prompt: "You are an angry and belligerent customer who wants a refund for their car.",
},
dataset_id: dataset.id,
}, {
inputs: {
messages: [
{
role: "user",
content: "Please give me a refund for my car."
}
],
simulated_user_prompt: "You are a nice customer who wants a refund for their car.",
},
dataset_id: dataset.id,
}];
await lsClient.createExamples(examples);
const trajectoryEvaluator = createLLMAsJudge({
model: "openai:o3-mini",
prompt:
"Based on the below conversation, was the user satisfied?\n{outputs}",
feedbackKey: "satisfaction",
});
const client = wrapOpenAI(new OpenAI());
const target = async (inputs: {
messages: ChatCompletionMessage[],
simulated_user_prompt: string,
}) => {
const history = {};
// Create a custom app function
const app = async (
{ inputs: nextMessage, threadId }: { inputs: ChatCompletionMessage, threadId: string }
) => {
if (history[threadId] === undefined) {
history[threadId] = [];
}
history[threadId].push(nextMessage);
const res = await client.chat.completions.create({
model: "gpt-5.4-nano",
messages: [
{
role: "system",
content:
"You are a patient and understanding customer service agent",
},
nextMessage,
],
});
const responseMessage = res.choices[0].message;
history[threadId].push(responseMessage);
return responseMessage;
};
const user = createLLMSimulatedUser({
system: inputs.simulated_user_prompt,
model: "openai:gpt-5.4-nano",
fixedResponses: inputs.messages,
});
const result = await runMultiturnSimulation({
app,
user,
maxTurns: 5,
});
return result.trajectory;
};
await evaluate(target, {
data: datasetName,
evaluators: [trajectoryEvaluator],
});
后续步骤
您刚刚了解了一些模拟多轮交互并在LangSmith评估中运行它们的技术。 以下是一些您可能想要接下来探索的主题: 您也可以探索 OpenEvals readme 以获取更多关于预构建评估器的信息。将这些文档通过MCP连接到Claude、VSCode等,以获取实时答案。