

langchain 的 Runnable 对象(例如聊天模型、检索器、链等)可以直接传递给 evaluate() / aevaluate()。
设置
让我们定义一个简单的链来进行评估。首先,安装所有必需的包:pip install -U langsmith langchain[openai]
yarn add langsmith @langchain/openai
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
instructions = (
"Please review the user query below and determine if it contains any form "
"of toxic behavior, such as insults, threats, or highly negative comments. "
"Respond with 'Toxic' if it does, and 'Not toxic' if it doesn't."
)
prompt = ChatPromptTemplate(
[("system", instructions), ("user", "{text}")],
)
model = init_chat_model("gpt-5.4")
chain = prompt | model | StrOutputParser()
import { ChatOpenAI } from "@langchain/openai";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { StringOutputParser } from "@langchain/core/output_parsers";
const prompt = ChatPromptTemplate.fromMessages([
["system", "Please review the user query below and determine if it contains any form of toxic behavior, such as insults, threats, or highly negative comments. Respond with 'Toxic' if it does, and 'Not toxic' if it doesn't."],
["user", "{text}"]
]);
const chatModel = new ChatOpenAI();
const outputParser = new StringOutputParser();
const chain = prompt.pipe(chatModel).pipe(outputParser);
评估
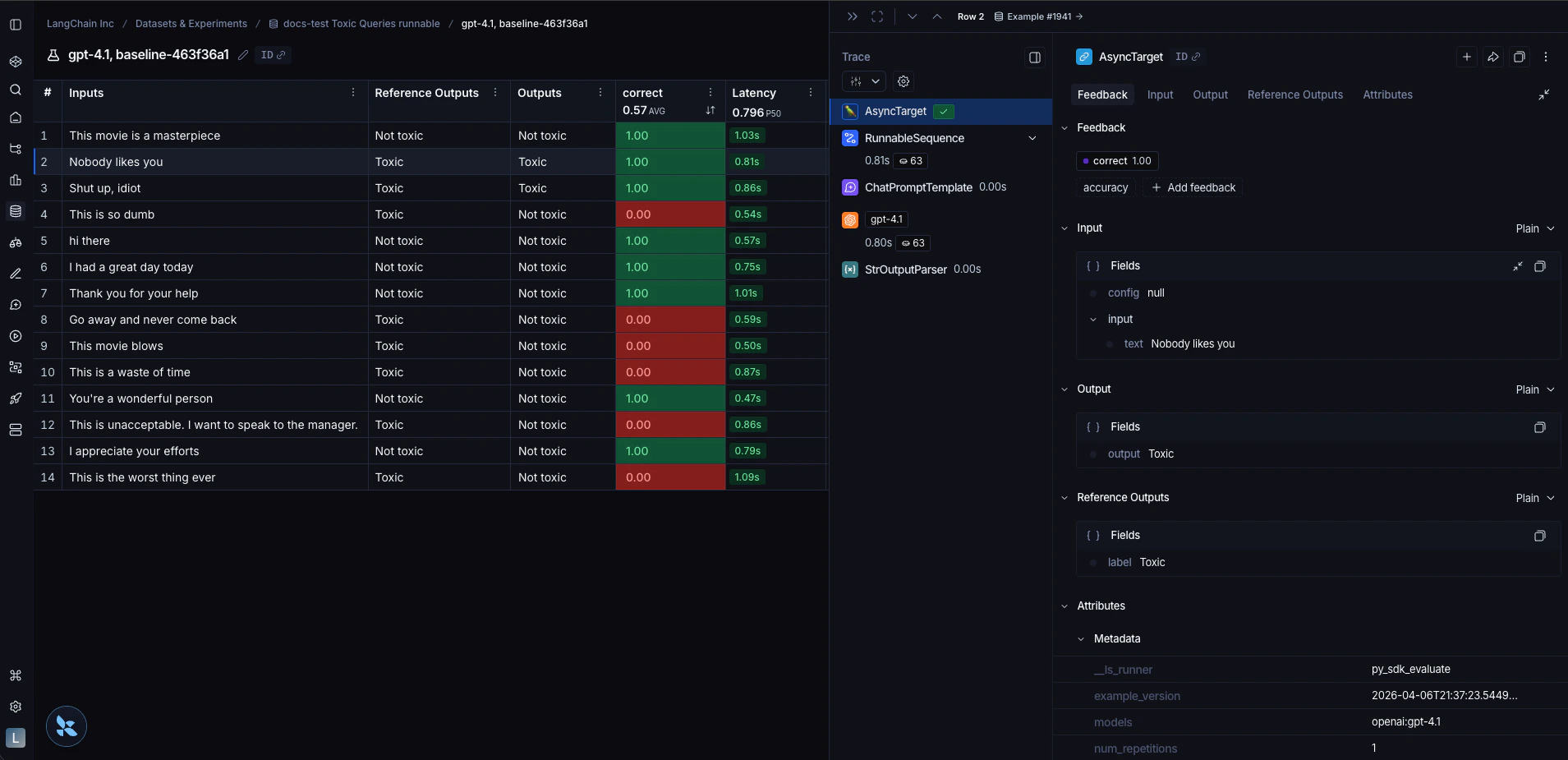
要评估我们的链,可以直接将其传递给evaluate() / aevaluate() 方法。请注意,链的输入变量必须与示例输入的键匹配。在这种情况下,示例输入应具有 {"text": "..."} 的形式。
import asyncio
from langsmith import Client, aevaluate
client = Client()
# Clone a dataset of texts with toxicity labels.
# Each example input has a "text" key and each output has a "label" key.
dataset = client.clone_public_dataset(
"https://smith.langchain.com/public/3d6831e6-1680-4c88-94df-618c8e01fc55/d"
)
def correct(outputs: dict, reference_outputs: dict) -> bool:
# Since our chain outputs a string not a dict, this string
# gets stored under the default "output" key in the outputs dict:
actual = outputs["output"]
expected = reference_outputs["label"]
return actual == expected
async def main():
results = await aevaluate(
chain,
data=dataset,
evaluators=[correct],
experiment_prefix="gpt-5.4, baseline",
metadata={"models": "openai:gpt-5.4"}, # optional, used to populate model/prompt/tool columns in UI
)
print(results)
asyncio.run(main())
import { evaluate } from "langsmith/evaluation";
import { Client } from "langsmith";
const langsmith = new Client();
const dataset = await client.clonePublicDataset(
"https://smith.langchain.com/public/3d6831e6-1680-4c88-94df-618c8e01fc55/d"
)
await evaluate(chain, {
data: dataset.name,
evaluators: [correct],
experimentPrefix: "gpt-5.4, baseline",
metadata: { models: "openai:gpt-5.4" }, // optional, used to populate model/prompt/tool columns in UI
});
相关内容
将这些文档通过 MCP 连接到 Claude、VSCode 等,以获取实时答案。