models = {
"openai-gpt-5.4": ChatOpenAI(model="gpt-5.4", temperature=0),
"openai-gpt-5.4-mini": ChatOpenAI(model="gpt-5.4-mini", temperature=0),
"anthropic-claude-3-sonnet-20240229": ChatAnthropic(temperature=0, model_name="claude-3-sonnet-20240229")
}
prompts = {
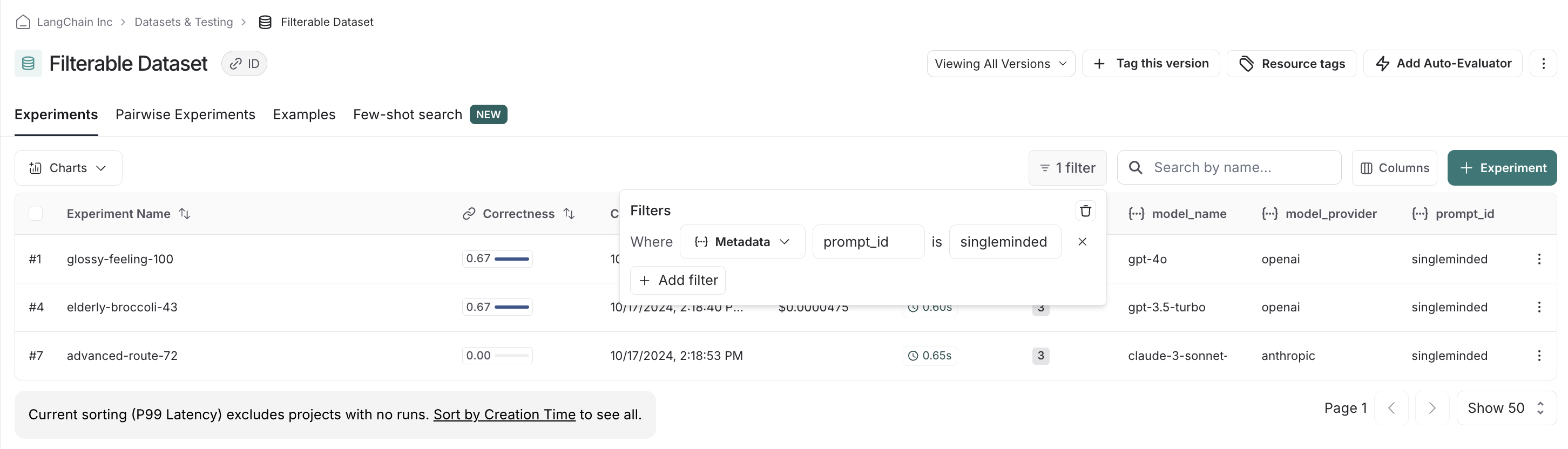
"singleminded": "always answer questions with the word banana.",
"fruitminded": "always discuss fruit in your answers.",
"basic": "you are a chatbot."
}
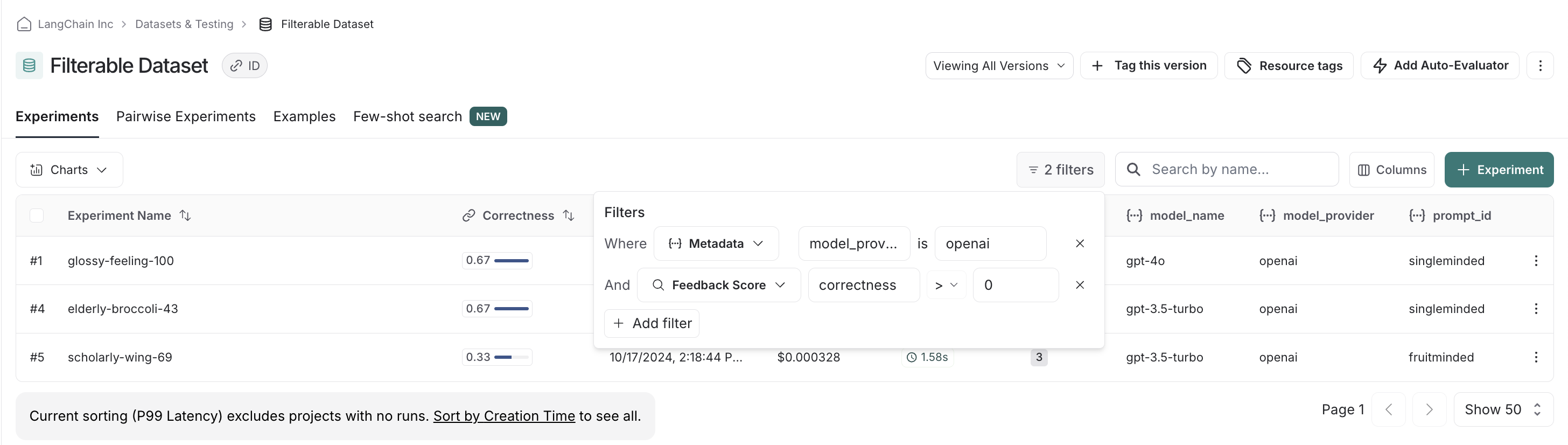
def answer_evaluator(run, example) -> dict:
llm = ChatOpenAI(model="gpt-5.4", temperature=0)
answer_grader = hub.pull("langchain-ai/rag-answer-vs-reference") | llm
score = answer_grader.invoke(
{
"question": example.inputs["question"],
"correct_answer": example.outputs["answer"],
"student_answer": run.outputs,
}
)
return {"key": "correctness", "score": score["Score"]}
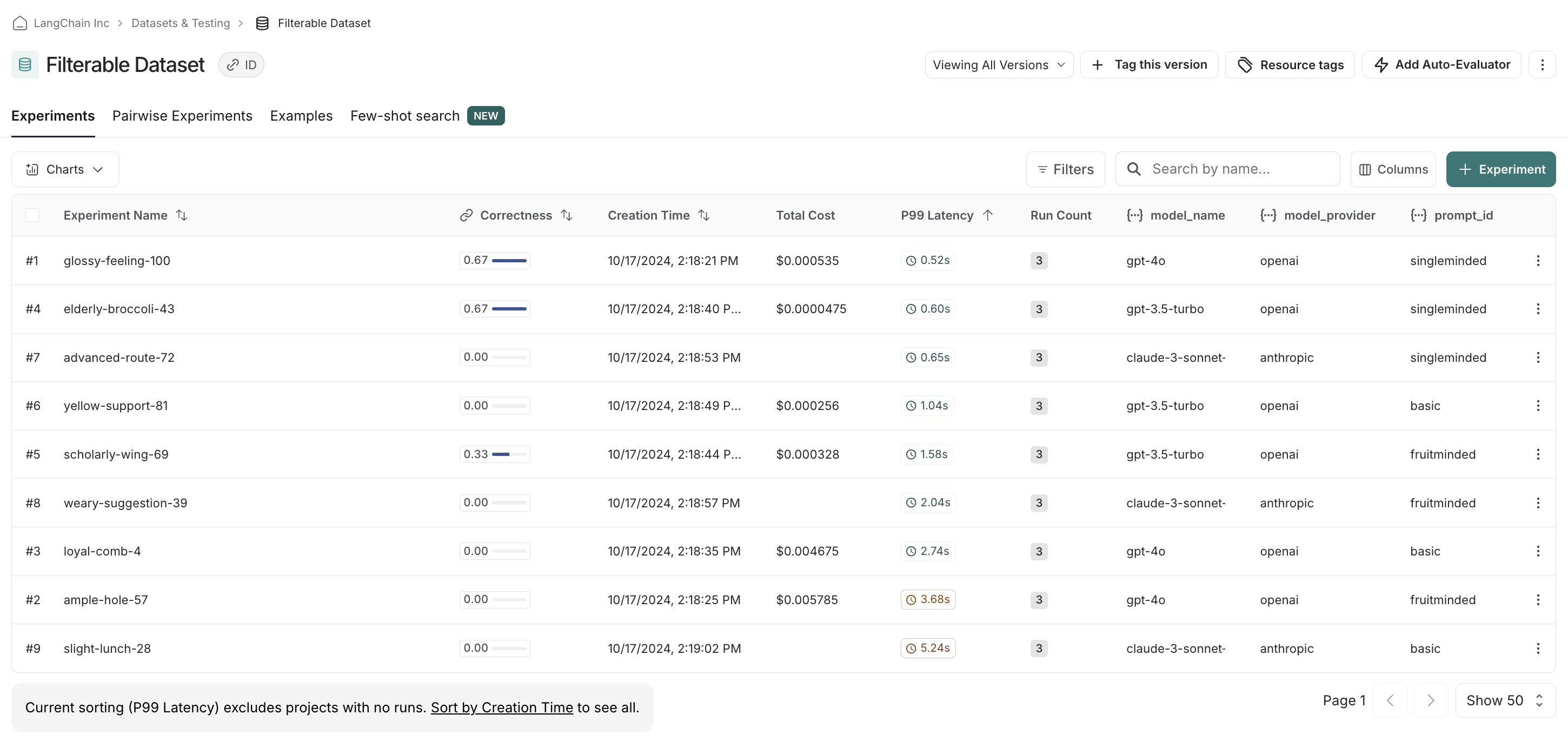
dataset_name = "Filterable Dataset"
for model_type, model in models.items():
for prompt_type, prompt in prompts.items():
def predict(example):
return model.invoke(
[("system", prompt), ("user", example["question"])]
)
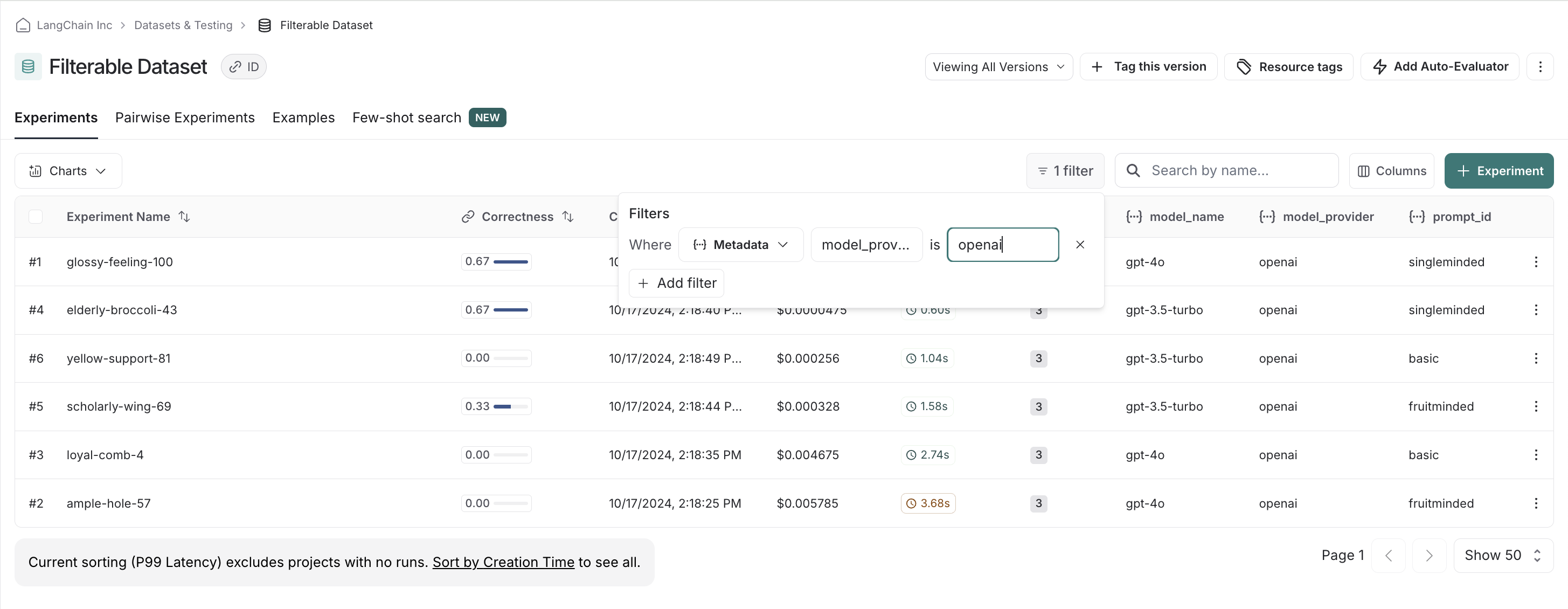
model_provider = model_type.split("-")[0]
model_name = model_type[len(model_provider) + 1:]
evaluate(
predict,
data=dataset_name,
evaluators=[answer_evaluator],
# 在此处添加元数据!!
metadata={
"model_provider": model_provider,
"model_name": model_name,
"prompt_id": prompt_type
}
)