

- 对数据集进行版本控制以跟踪随时间的变化。
- 筛选和拆分数据集以进行评估。
- 公开共享数据集。
- 导出数据集为各种格式。
对数据集进行版本控制
在 LangSmith 中,数据集是版本化的。这意味着每次您在数据集中添加、更新或删除示例时,都会创建一个新版本的数据集。创建数据集的新版本
每当您在数据集中添加、更新或删除示例时,都会创建一个数据集的新版本。这使您能够跟踪数据集随时间的变化,并了解数据集是如何演变的。 默认情况下,版本由更改的时间戳定义。当您在 Examples 选项卡中单击数据集的特定版本(按时间戳)时,您将看到该时间点的数据集状态。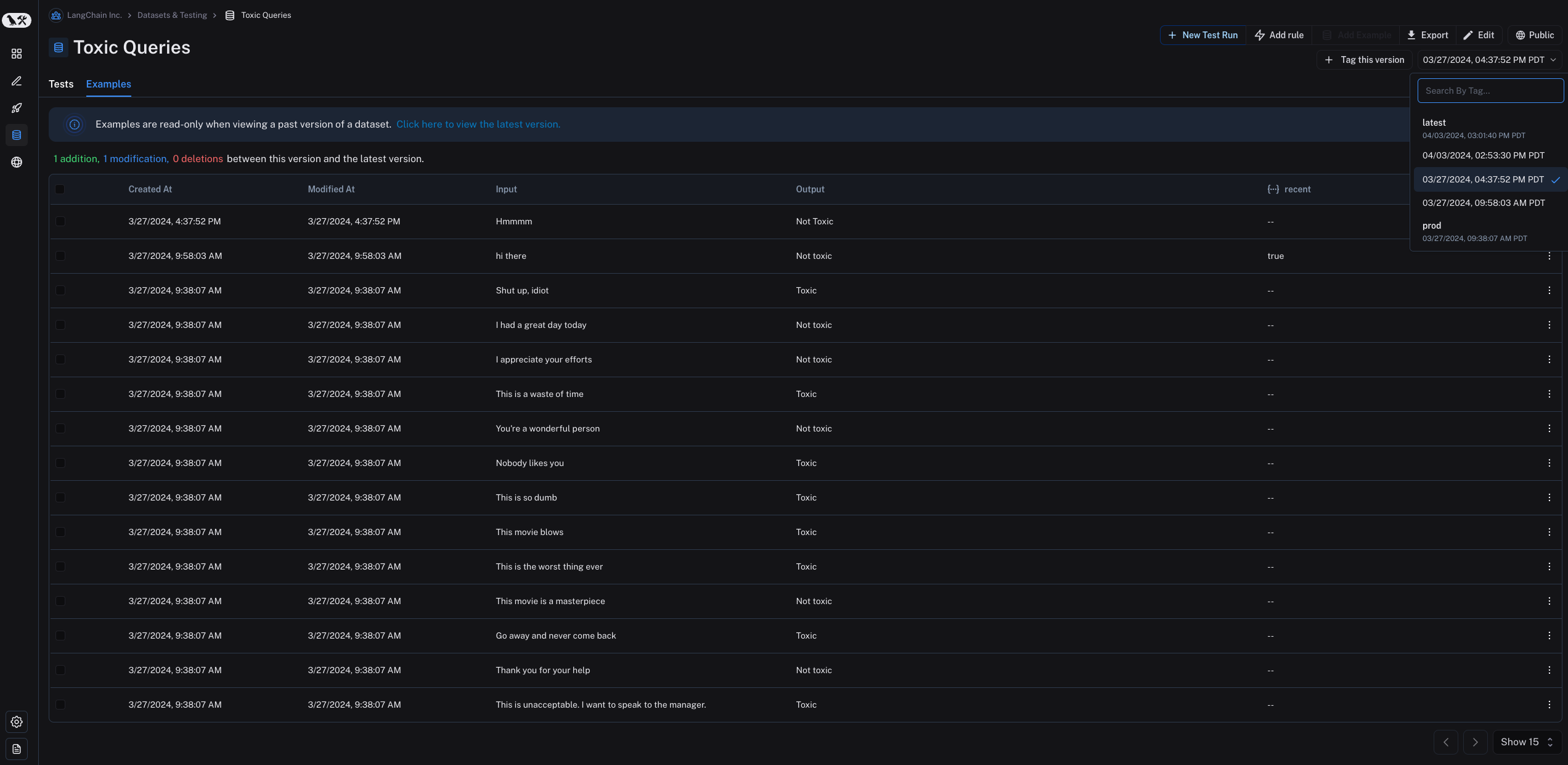
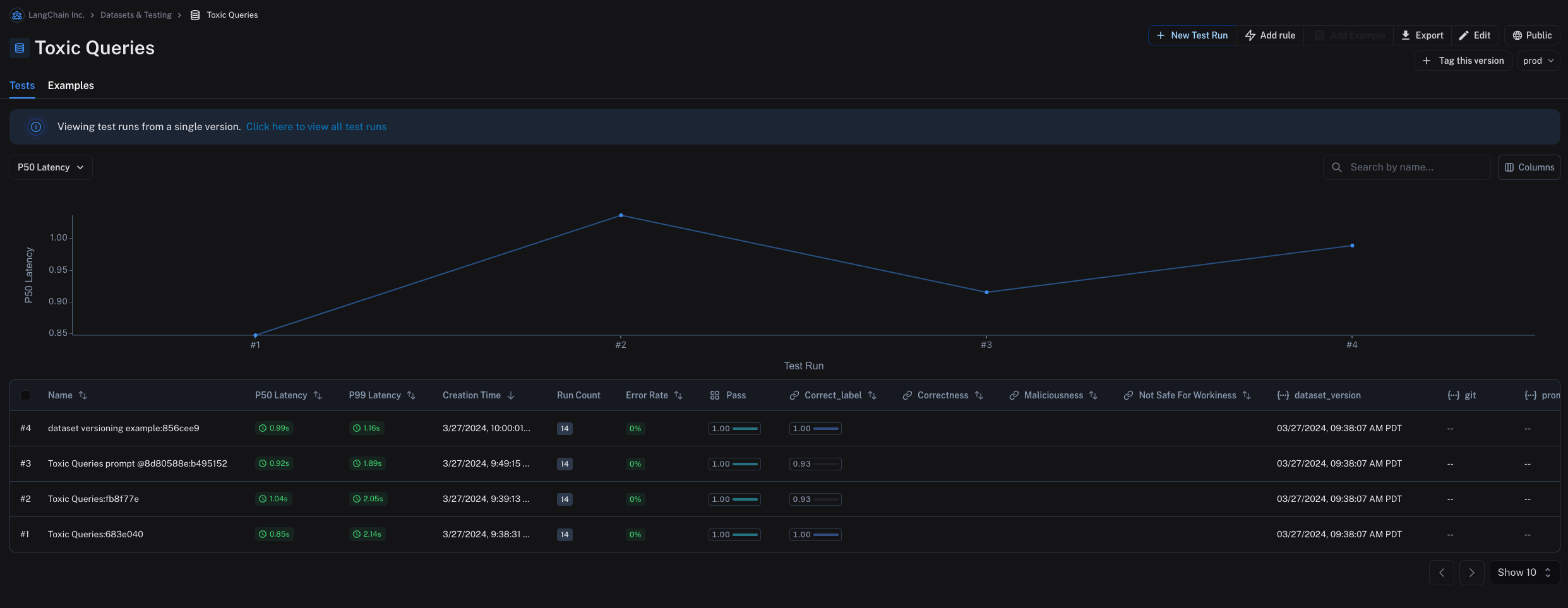
默认情况下,Examples 选项卡中显示的是数据集的最新版本,Tests 选项卡中显示的是所有版本的实验。
为版本添加标签
您还可以为数据集的版本添加标签,使其具有更易于人类阅读的名称,这对于标记数据集历史中的重要里程碑非常有用。 例如,您可以将数据集的某个版本标记为 “prod”,并使用它来对您的 LLM 管道运行测试。 您可以通过在 Examples 选项卡中单击 + Tag this version 在 UI 中为数据集的版本添加标签。
在特定数据集版本上评估
在阅读本节之前,您可能会发现参考以下内容很有帮助:
使用 list_examples
您可以使用 evaluate / aevaluate 传入一个示例可迭代对象,以在数据集的特定版本上进行评估。使用 list_examples / listExamples 通过 as_of / asOf 从特定版本标签获取示例,并将其传递给 data 参数。
在数据集的拆分/筛选视图上评估
在阅读本节之前,您可能会发现参考以下内容很有帮助:
在数据集的筛选视图上评估
您可以使用list_examples / listExamples 方法从数据集中获取示例子集以进行评估。
一个常见的工作流是获取具有特定元数据键值对的示例。
在数据集拆分上评估
您可以使用list_examples / listExamples 方法在数据集的一个或多个拆分上进行评估。splits 参数接受您希望评估的拆分列表。
共享数据集
公开共享数据集
从 Dataset & Experiments 选项卡中,选择一个数据集,单击 ⋮(页面右上角),单击 Share Dataset。这将打开一个对话框,您可以在其中复制数据集的链接。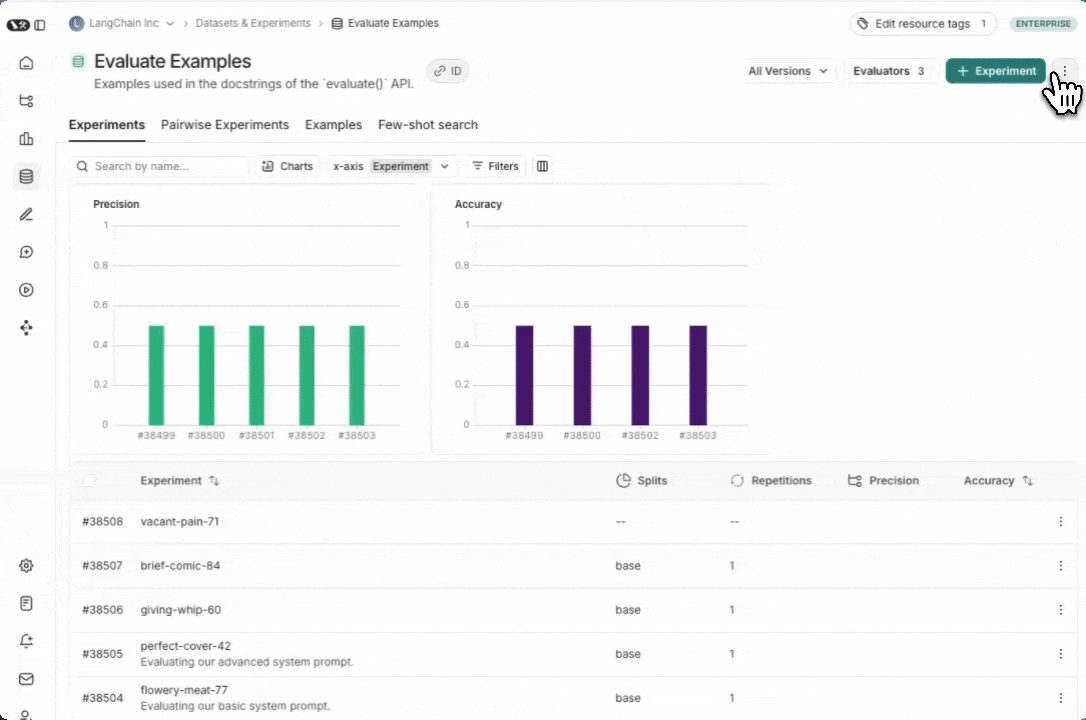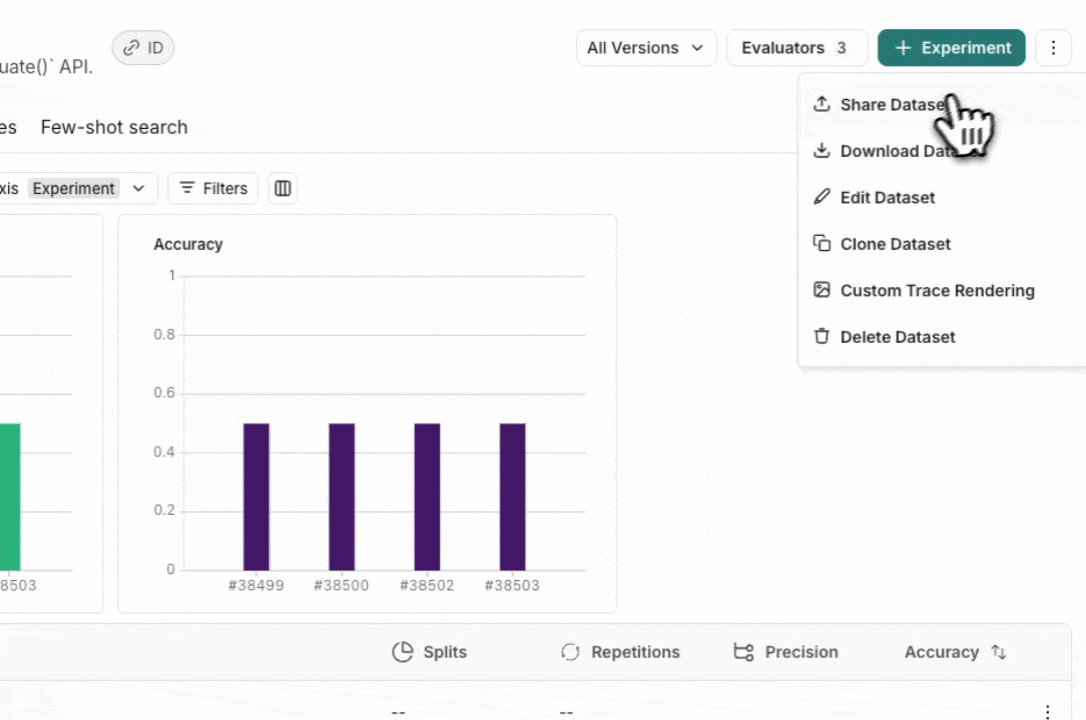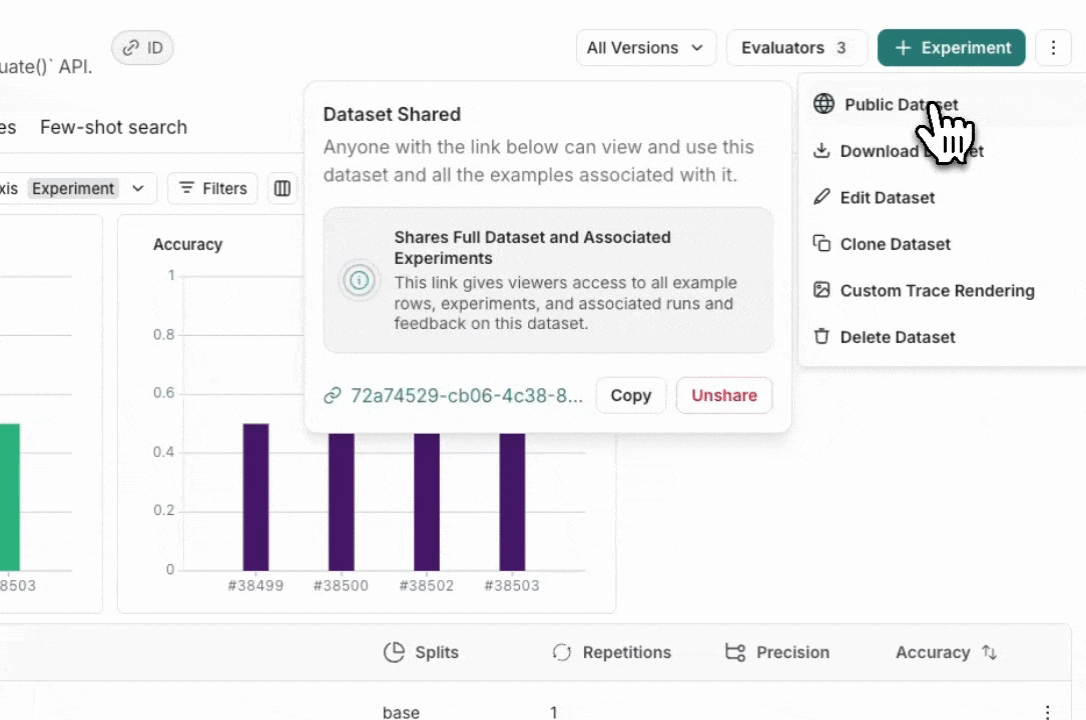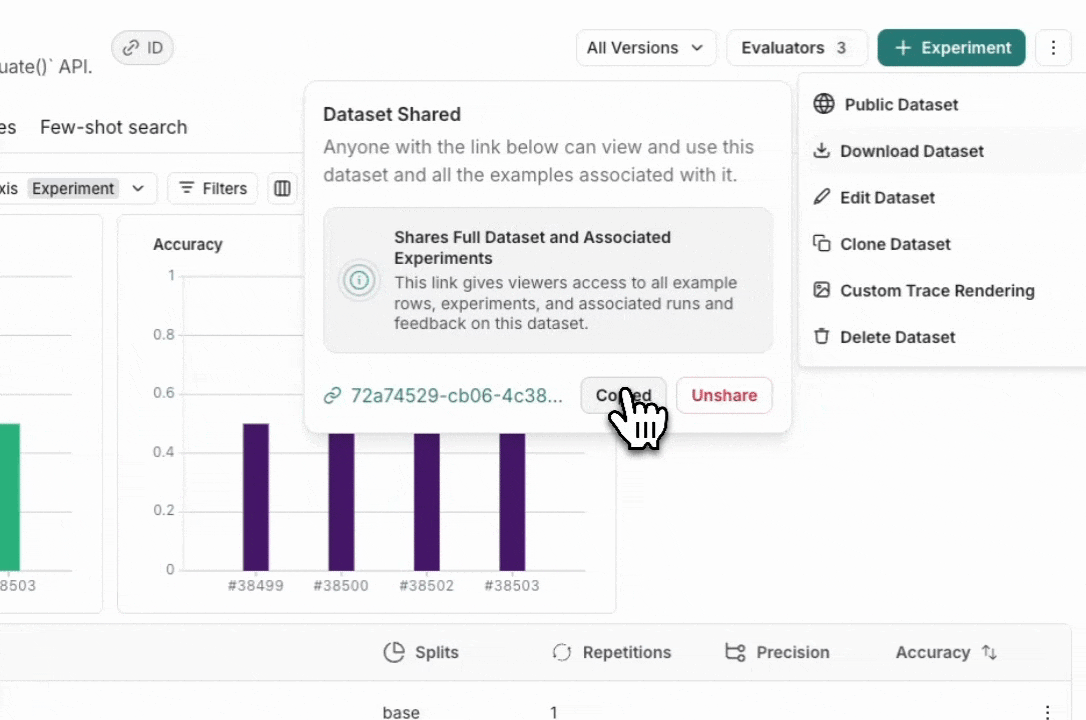
取消共享数据集
-
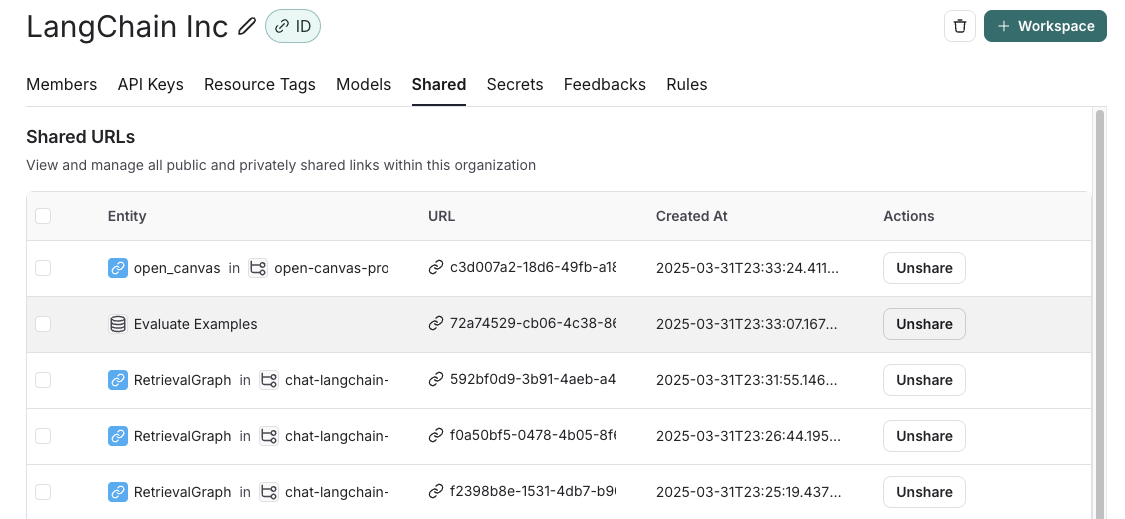
通过单击任何公开共享数据集右上角的 Public,然后在对话框中单击 Unshare 来取消共享。

- 导航到您组织的公开共享数据集列表,方法是单击 Settings -> Shared URLs 或此链接,然后单击要取消共享的数据集旁边的 Unshare。
导出数据集
您可以从 LangSmith UI 将 LangSmith 数据集导出为 CSV、JSONL 或 OpenAI 的微调格式。 从 Dataset & Experiments 选项卡中,选择一个数据集,单击 ⋮(页面右上角),单击 Download Dataset。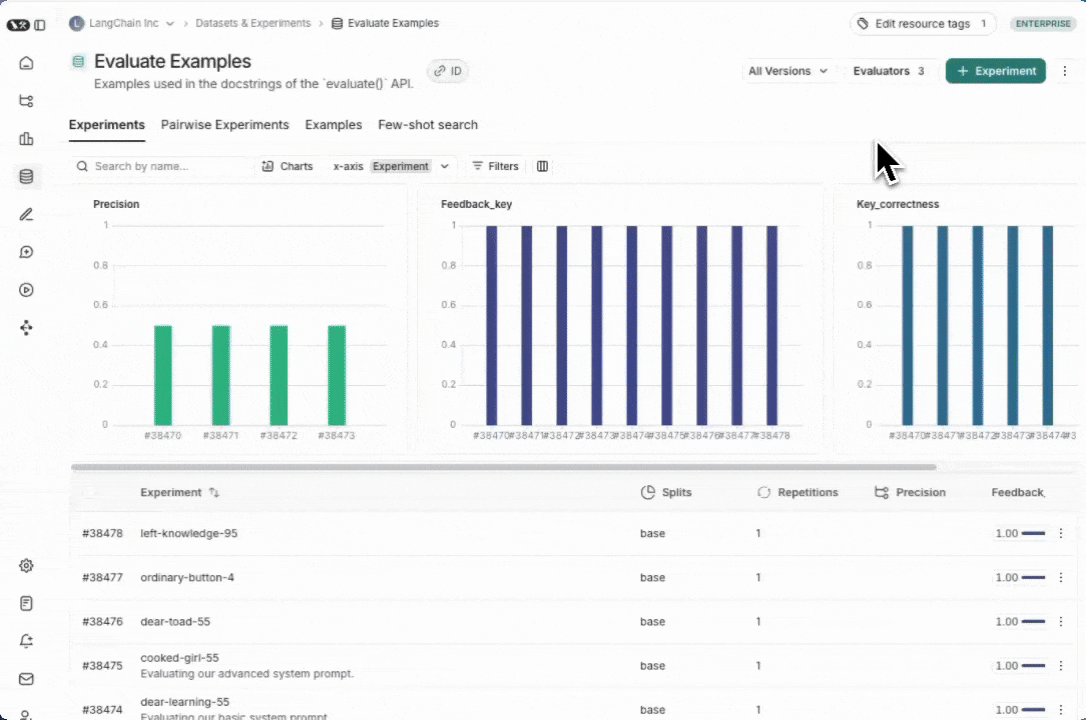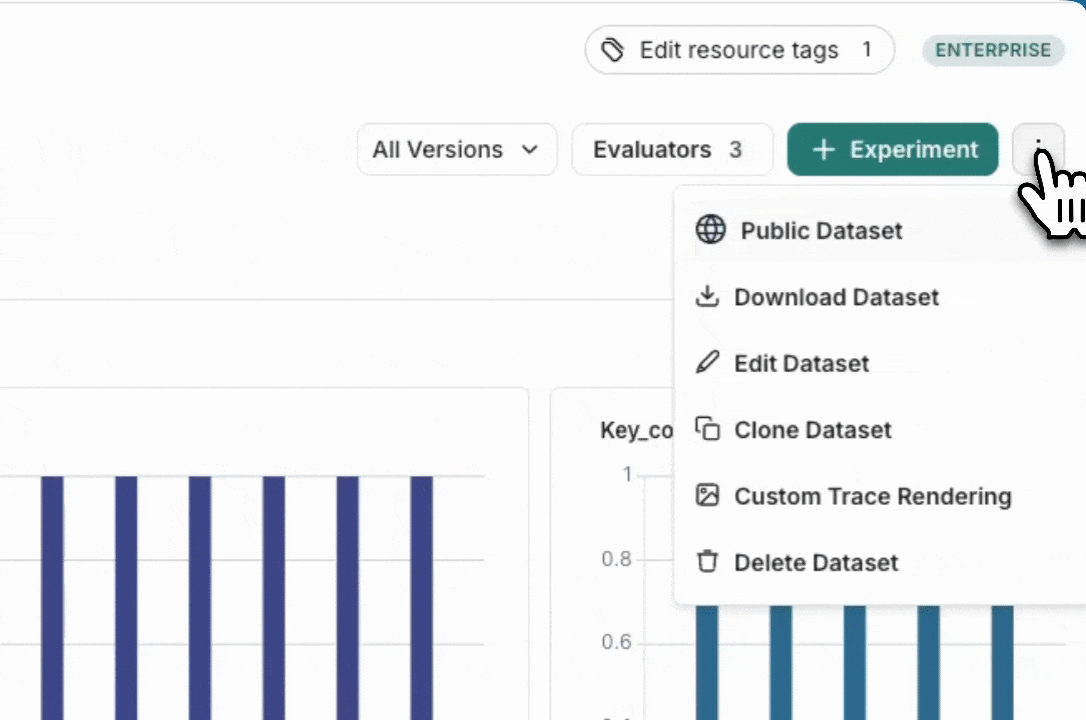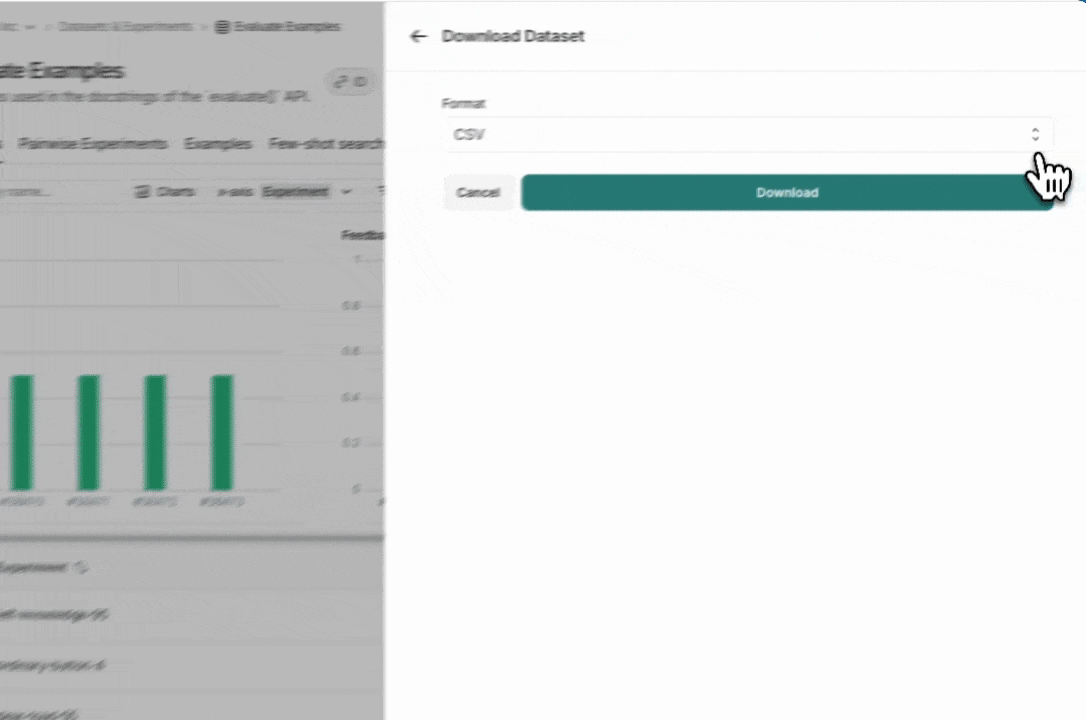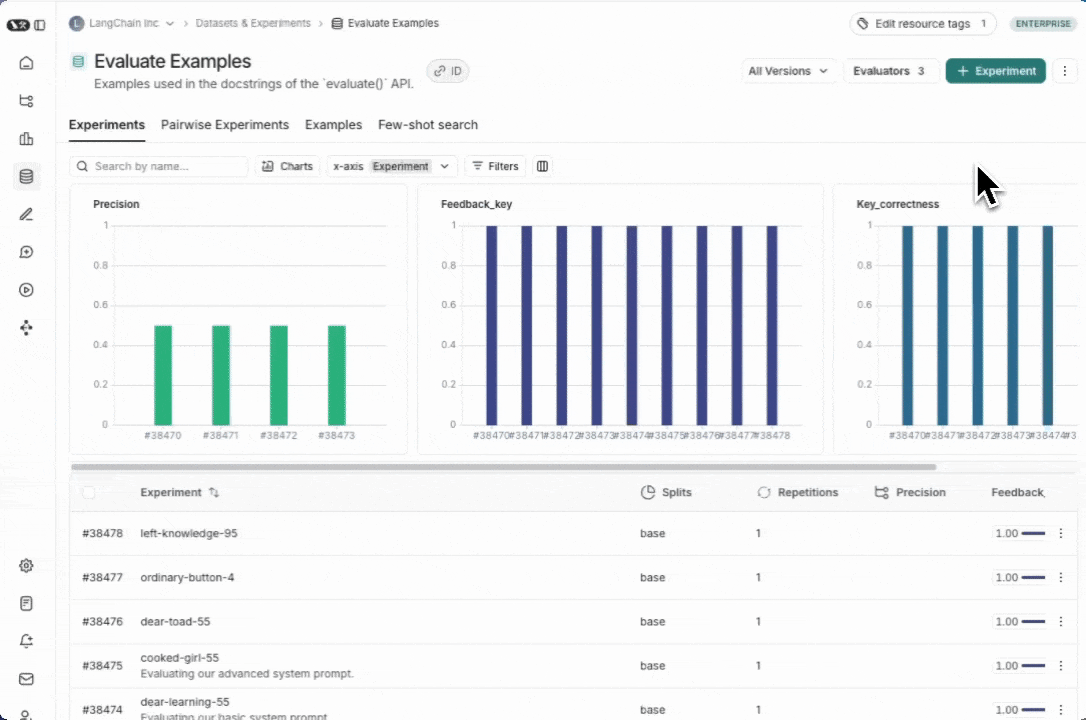
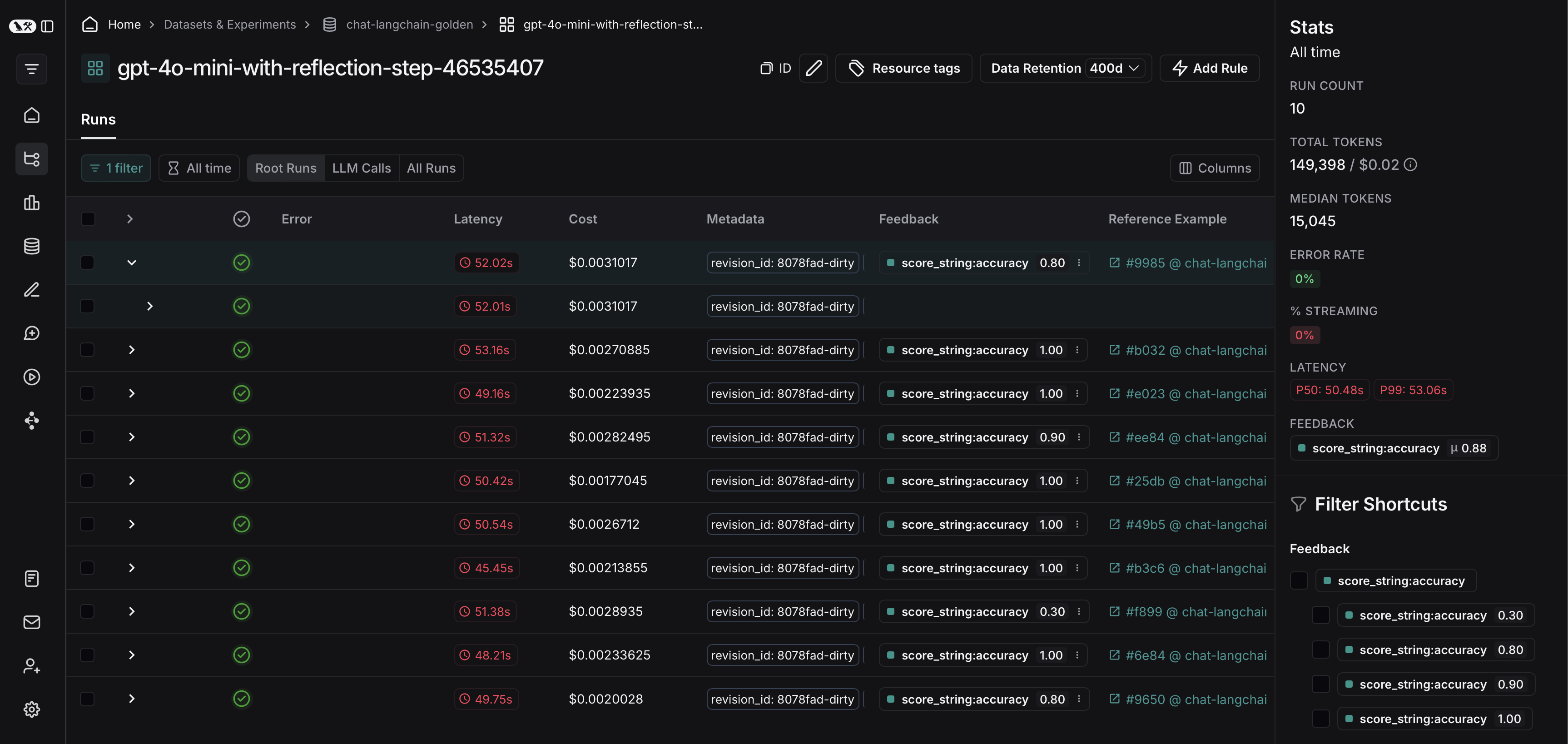
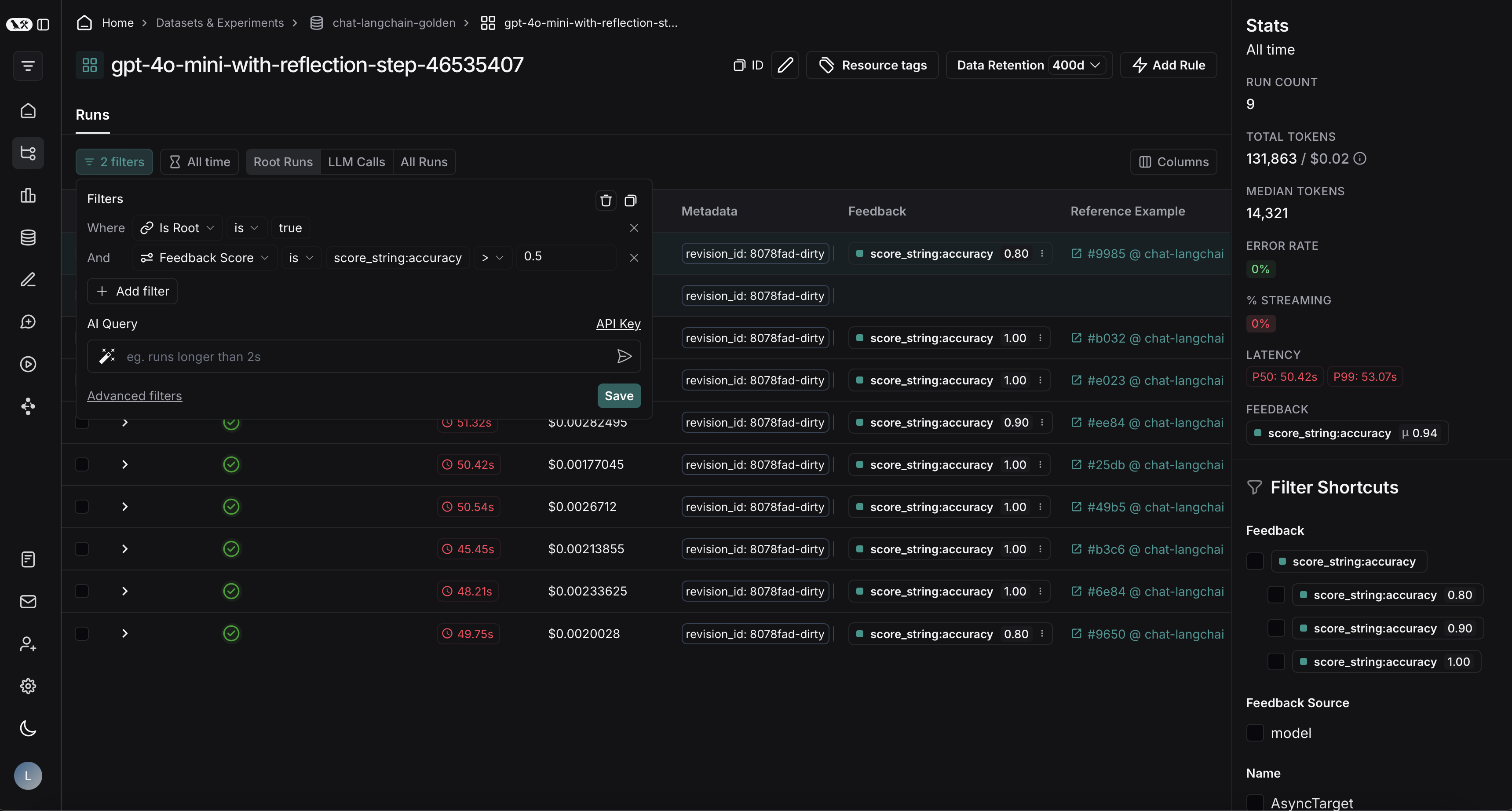
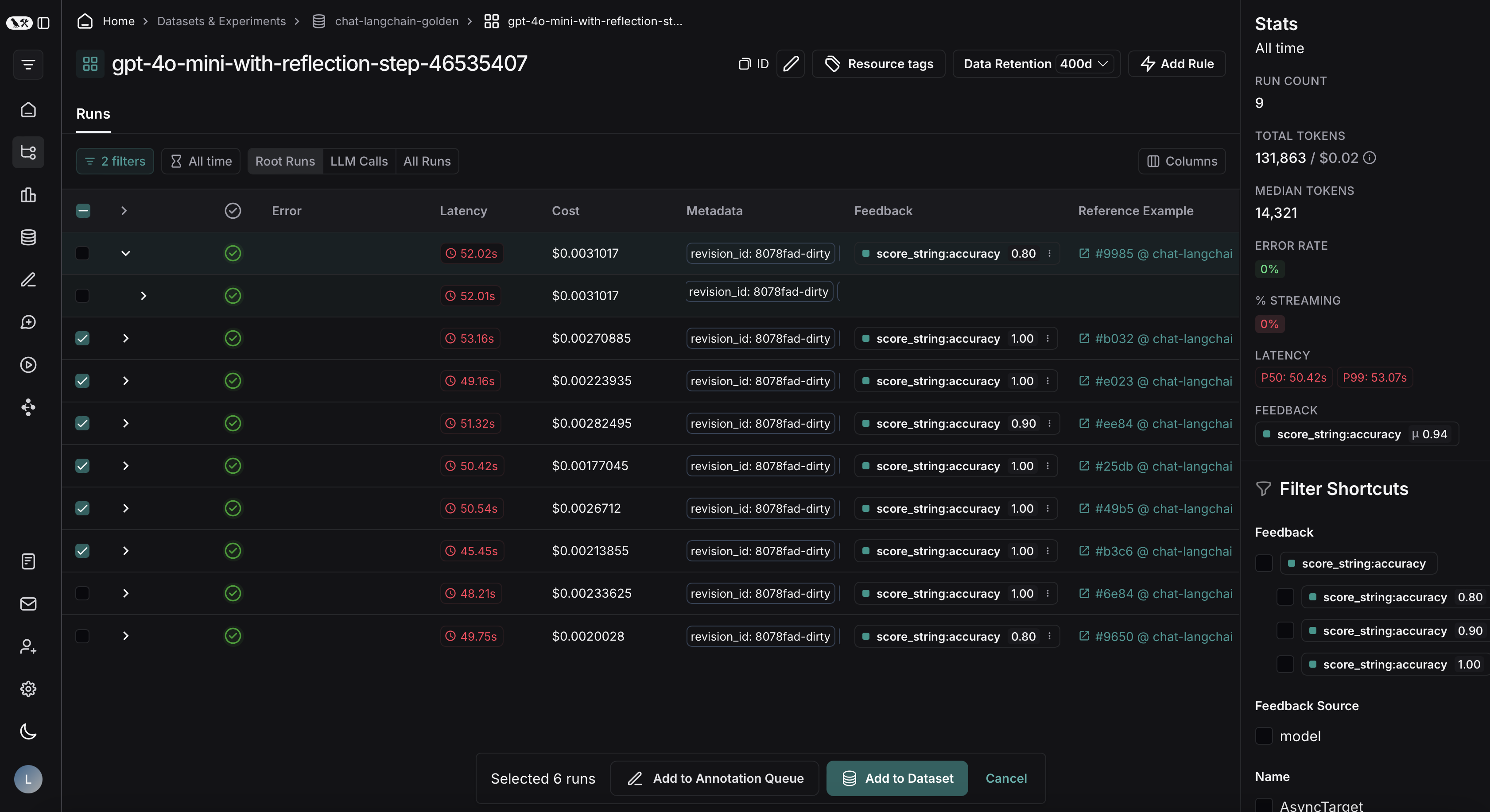
将筛选的跟踪记录从实验导出到数据集
在 LangSmith 中运行离线评估后,您可能希望将符合某些评估标准的跟踪记录导出到数据集。查看实验跟踪记录
将这些文档连接到 Claude、VSCode 等,通过 MCP 获取实时答案。