

- 分析单个实验:查看和解释实验结果,自定义列,筛选数据,并比较运行。
- 在实验标签视图中设置基线:为一个你希望超越的数据集设置基线。
- 在实验标签视图中按模型、提示和工具筛选与分组:使用 模型、提示 和 工具 列在 实验 标签视图中筛选和分组实验。
- 将实验结果下载为 CSV:导出你的实验数据以供外部分析和共享。
- 重命名实验:在 Playground 和实验视图中更新实验名称。
分析单个实验
运行实验后,你可以使用 LangSmith 的实验视图来分析结果,并从实验性能中得出见解。打开实验视图
要打开实验视图,- 从 数据集与实验 页面选择相关的数据集,这将打开 实验 标签视图。
- 点击你想要查看的实验行。
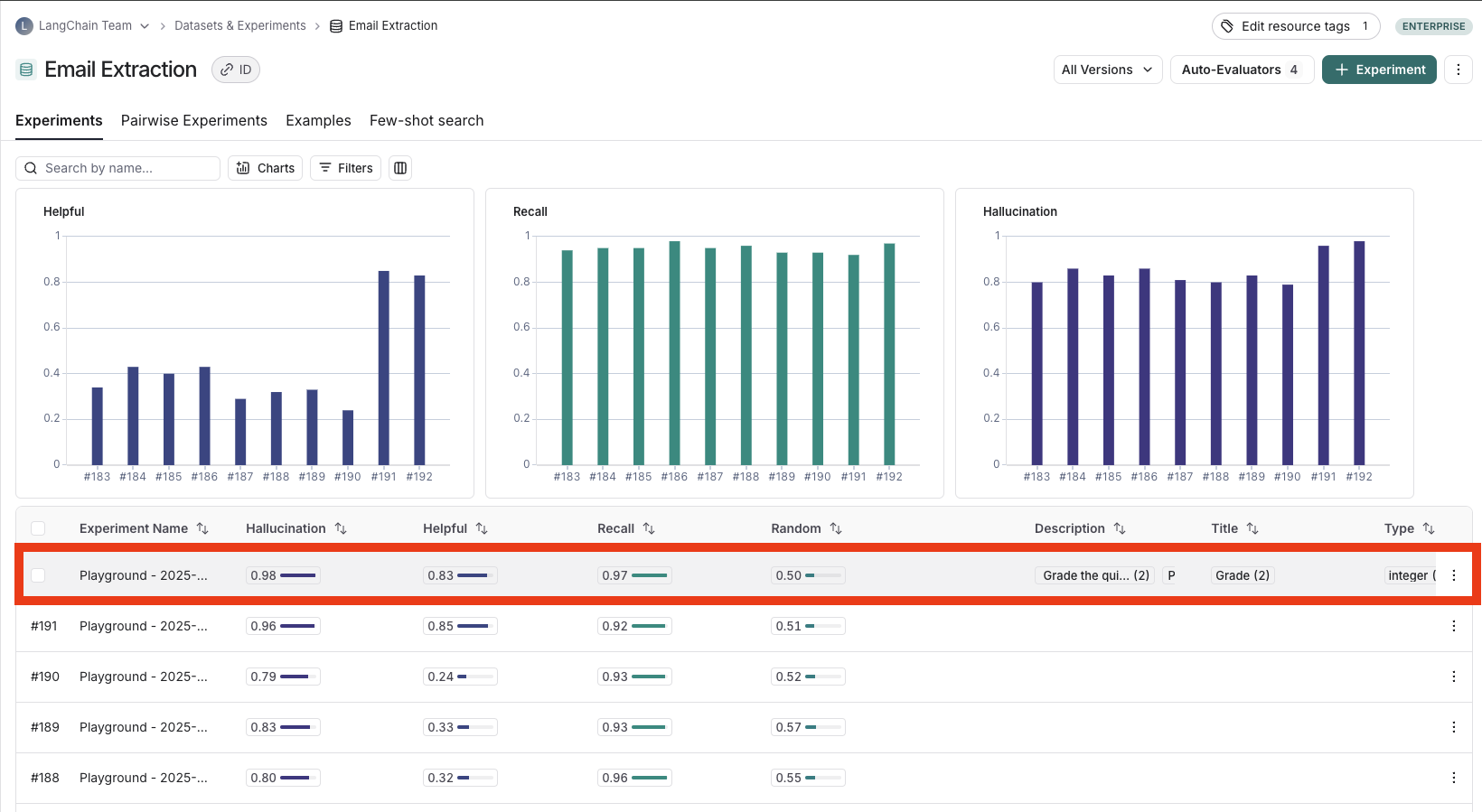
查看实验结果
自定义列
默认情况下,实验视图显示数据集中每个示例的输入、输出和参考输出,来自评估的反馈分数,以及实验指标,如成本、令牌数、延迟和状态。 你可以通过点击视图右上角的 列 图标来自定义列,以便更轻松地解释实验结果:- 将输入、输出和参考输出中的字段拆分到各自的列中。如果你有很长的输入/输出/参考输出,并且希望突出显示重要字段,这尤其有用。
- 隐藏和重新排序列,以创建用于分析的专注视图。
- 控制反馈分数的小数精度。默认情况下,LangSmith 显示的数值反馈分数小数精度为 2,但你可以自定义此设置,最多可达 6 位小数。
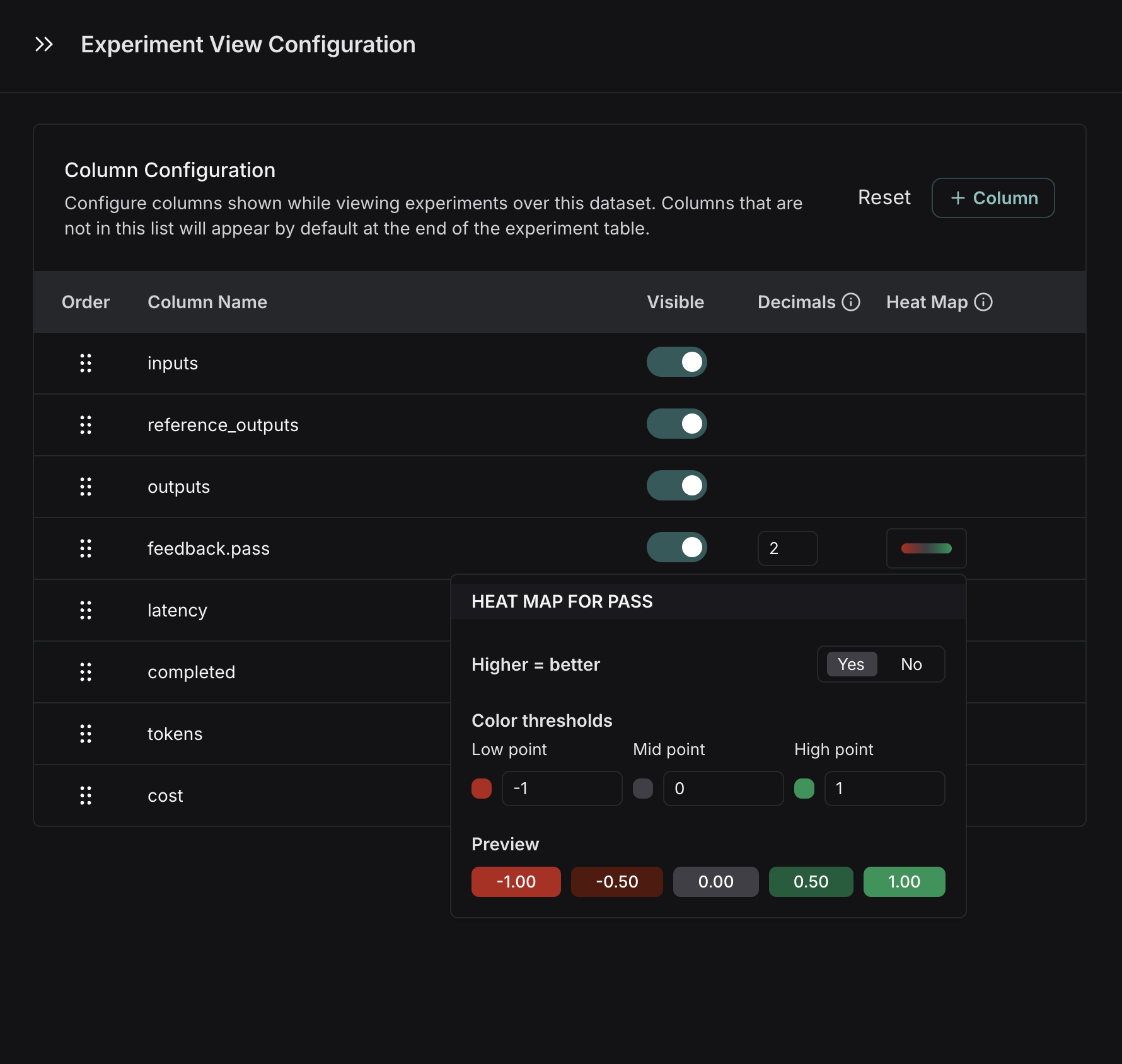
- 设置热力图阈值,为实验中的数值反馈分数设置高、中、低阈值,这会影响分数标签渲染为红色或绿色的阈值:
排序和筛选
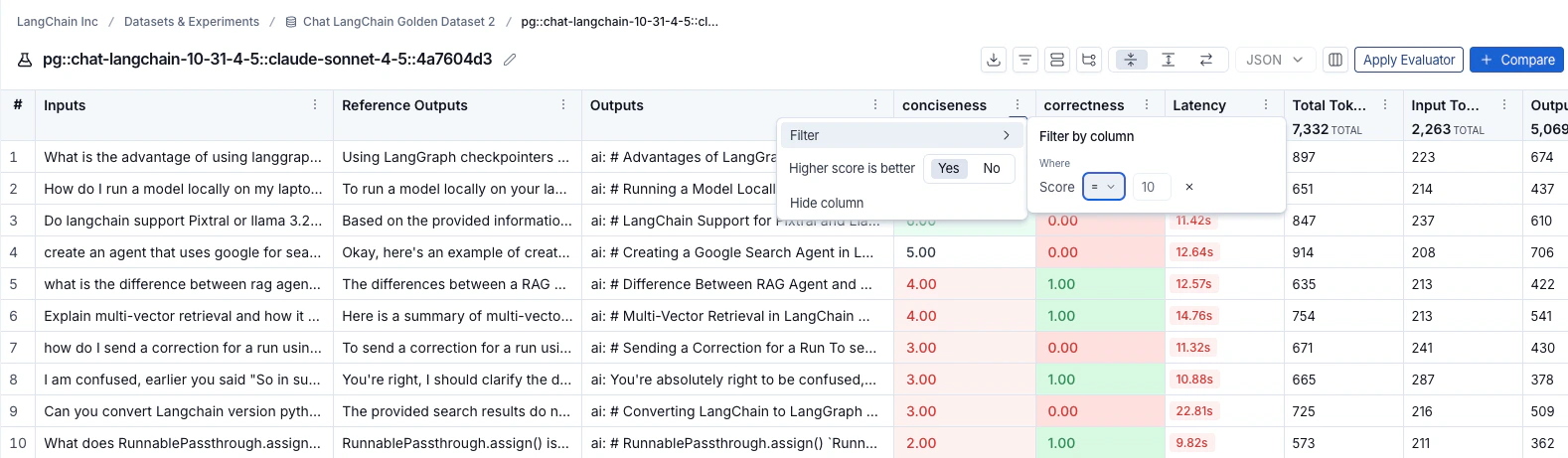
要按反馈分数对行进行排序,请点击列标题中的 排序依据 图标。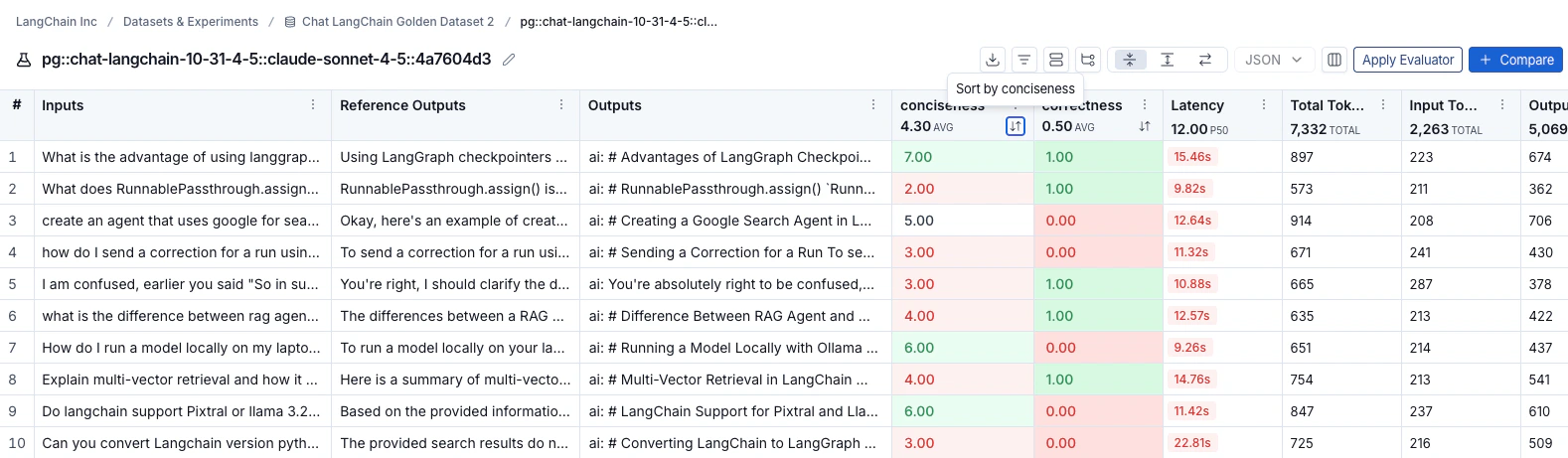
表格视图
在实验视图的右上角选择三种表格视图图标之一:- 紧凑:将每次运行显示为单行,以便快速比较分数。
- 完整:显示每次运行的完整输出。
- 差异:显示每次运行的参考输出与输出之间的文本差异。
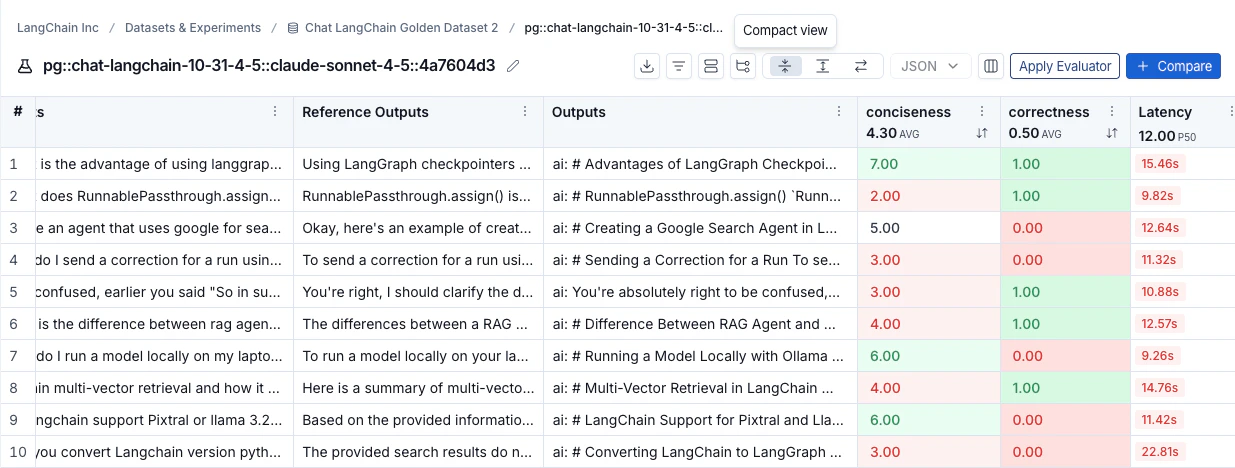
查看跟踪
点击实验视图中的任何行以打开详细信息面板,该面板显示该运行的跟踪以及反馈、输入、输出和属性。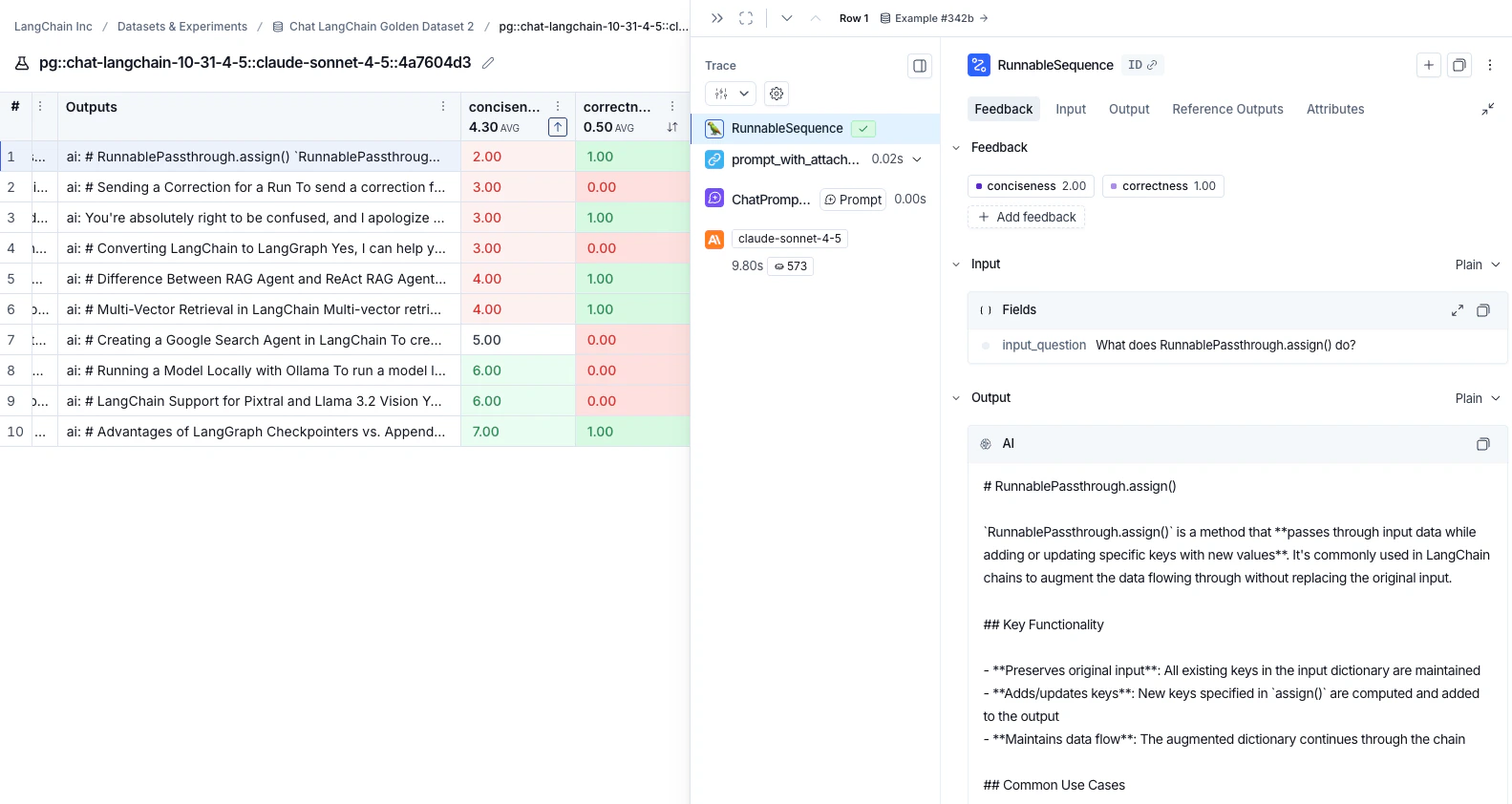
查看评估器运行
通过将鼠标悬停在评估器分数上,你可以查看有关该评估器运行的更多详细信息。对于 LLM 作为评判的评估器,点击 来源 链接可查看使用的提示,或点击 评估器跟踪 在新的浏览器标签页中打开跟踪。对于具有重复的实验,点击聚合平均分数可查看所有单独运行的链接。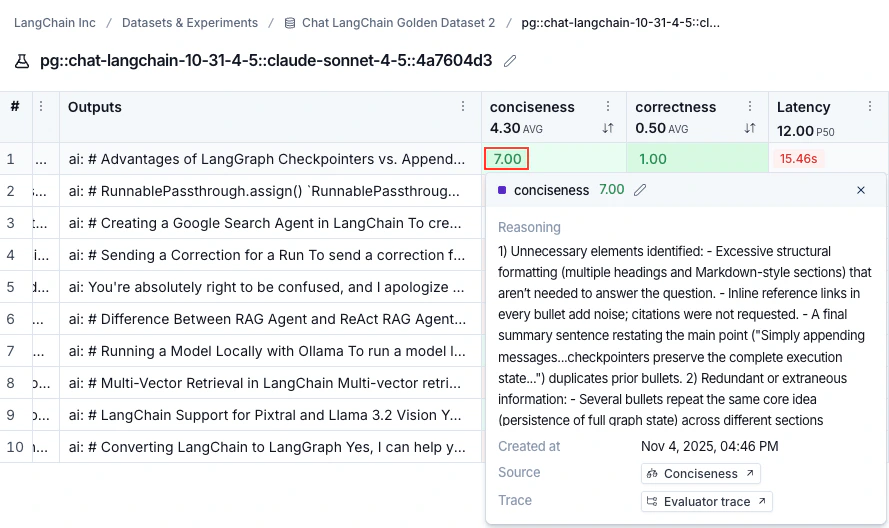
按元数据分组结果
你可以向示例添加元数据以对其进行分类和组织。例如,如果你正在评估问答数据集的事实准确性,元数据可能包括每个问题所属的学科领域。元数据可以通过 UI 或 SDK 添加。 要按元数据分析结果,请使用实验视图右上角的 分组依据 图标,并选择所需的元数据键。这将显示每个元数据组的平均反馈分数、延迟、总令牌数和成本。你只能在 2025 年 2 月 20 日之后创建的实验上按示例元数据进行分组。在此日期之前的任何实验仍然可以按元数据分组,但前提是元数据位于实验跟踪本身上。
重复
如果你使用重复运行了实验,请点击任何行以打开详细信息面板。重复摘要 显示指标表、所有反馈分数,并允许你切换输出或查看带有跟踪的各个重复。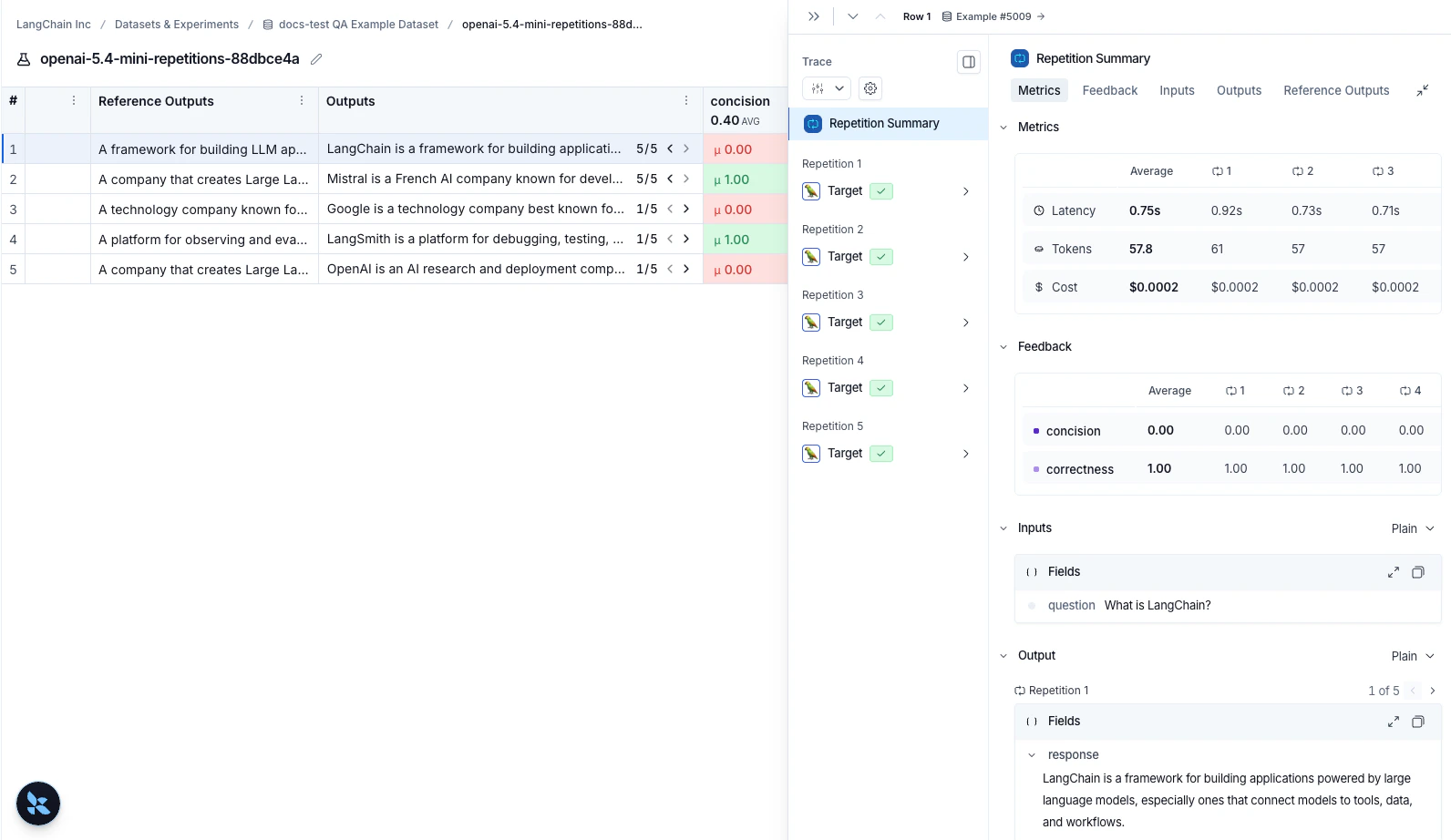
与另一个实验比较
在实验视图的右上角,你可以选择另一个实验进行比较。这将打开一个比较视图,你可以在其中查看两个实验的比较情况。要了解有关比较视图的更多信息,请参阅如何比较实验结果。在实验标签视图中设置基线
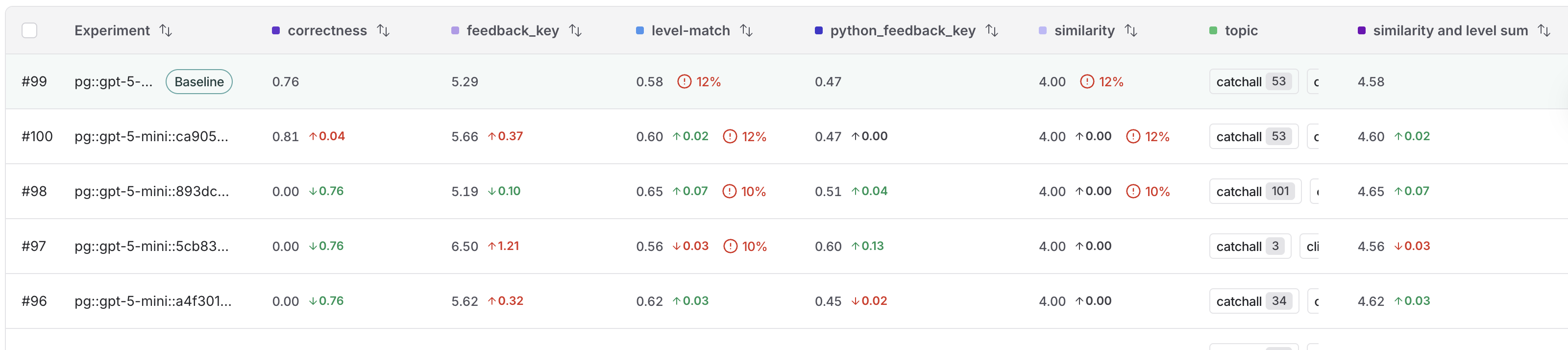
虽然你可能运行数十个测试,但通常有一个你试图超越的特定基准。设置 基线 可以将你的结果锚定到这个参考点,从而让你在拥挤的实验列表中识别改进或退步。 通过指定基线,你可以:- 突出显示参考:明确标记你表现最佳的运行,使其在 实验 标签视图的顶部保持可见,以便你进行迭代。
- 查看即时差异:自动查看所有实验的性能差异,这意味着你不一定需要执行手动并排选择。
- 加速评估:快速确定新的迭代是否达到或超过你当前的性能标准。
- 在 LangSmith UI 中,导航到左侧菜单中的 数据集与实验 选项。
- 从表格中选择你要处理的数据集。
- 在 实验 标签视图中,将鼠标悬停在实验行上,以在行的右端显示 设置基线 按钮。点击以选择你的基线实验。
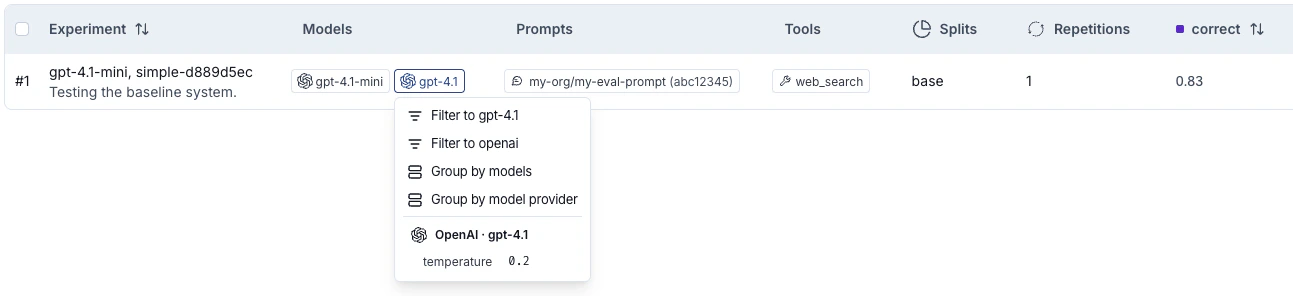
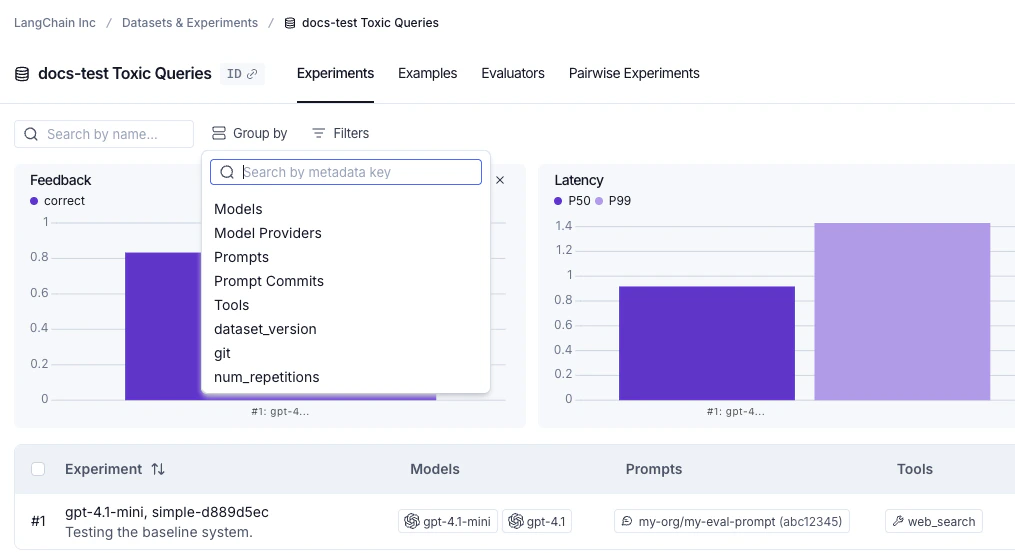
在实验标签视图中按模型、提示和工具筛选与分组
实验表包括 模型、提示 和 工具 列,显示每个实验使用了哪些模型、提示和工具,从而更容易一目了然地了解运行之间的变化。 当你从 Playground 运行实验时,这些列会自动填充。通过 SDK 运行实验时,将包含models、prompts 和 tools 键的 metadata 对象传递给 evaluate():
将实验结果下载为 CSV
LangSmith 允许你将实验结果下载为 CSV 文件,以供外部分析和共享。点击实验视图右上角的 下载为 CSV 图标。实验结果的下载限制为 5,000 行。
重命名实验
实验名称在每个工作区中必须是唯一的。
-
实验视图:使用实验名称旁边的铅笔图标重命名实验。

-
Playground:系统会自动分配一个格式为
pg::prompt-name::model::uuid(例如pg::gpt-5.4-mini::897ee630)的默认名称。你可以在运行实验后立即通过编辑 Playground 表格标题中的名称来重命名实验。
将这些文档连接到 Claude、VSCode 等,通过 MCP 获取实时答案。