

- 从您的生产追踪项目中选择要测试的样本运行。
- 将运行输入转换为数据集,并将运行输出记录为针对该数据集的初始实验。
- 在新数据集上执行您的新系统,并比较实验结果。
通常,您不会有明确的“基准真相”答案可用。在这种情况下,您可以手动标记输出,或使用不依赖参考数据的评估器。如果您的应用程序允许捕获基准真相标签(例如,允许用户留下反馈),我们强烈建议这样做。
设置
配置环境
安装并设置环境变量。本指南需要langsmith>=0.2.4。
为方便起见,本教程将使用 LangChain OSS 框架,但此处展示的 LangSmith 功能与框架无关。
定义应用程序
在这个例子中,让我们创建一个简单的推文撰写应用程序,它可以访问一些互联网搜索工具:模拟生产数据
现在让我们模拟一些生产数据:将生产追踪转换为实验
第一步是根据生产输入生成一个数据集。然后复制所有追踪作为基线实验。选择要回测的运行
您可以使用list_runs 的 filter 参数来选择要回测的运行。filter 参数使用 LangSmith 追踪查询语法 来选择运行。
将运行转换为实验
convert_runs_to_test 是一个函数,它接收一些运行并执行以下操作:
- 输入(以及可选的输出)作为示例保存到数据集中。
- 输入和输出作为实验存储,就像您运行了
evaluate函数并收到了这些输出一样。
与新系统进行基准测试
现在我们可以开始将生产运行与新系统进行基准测试的过程。定义评估器
首先,让我们定义用于比较两个系统的评估器。请注意,我们没有参考输出,因此需要设计仅需要实际输出的评估指标。评估基线
现在,让我们对基线实验运行我们的评估器。定义并评估新系统
现在,让我们定义并评估我们的新系统。在这个例子中,我们的新系统将与旧系统相同,但将使用 GPT-4o 而不是 GPT-3.5。由于我们已经使模型可配置,我们只需更新传递给智能体的默认配置:比较结果
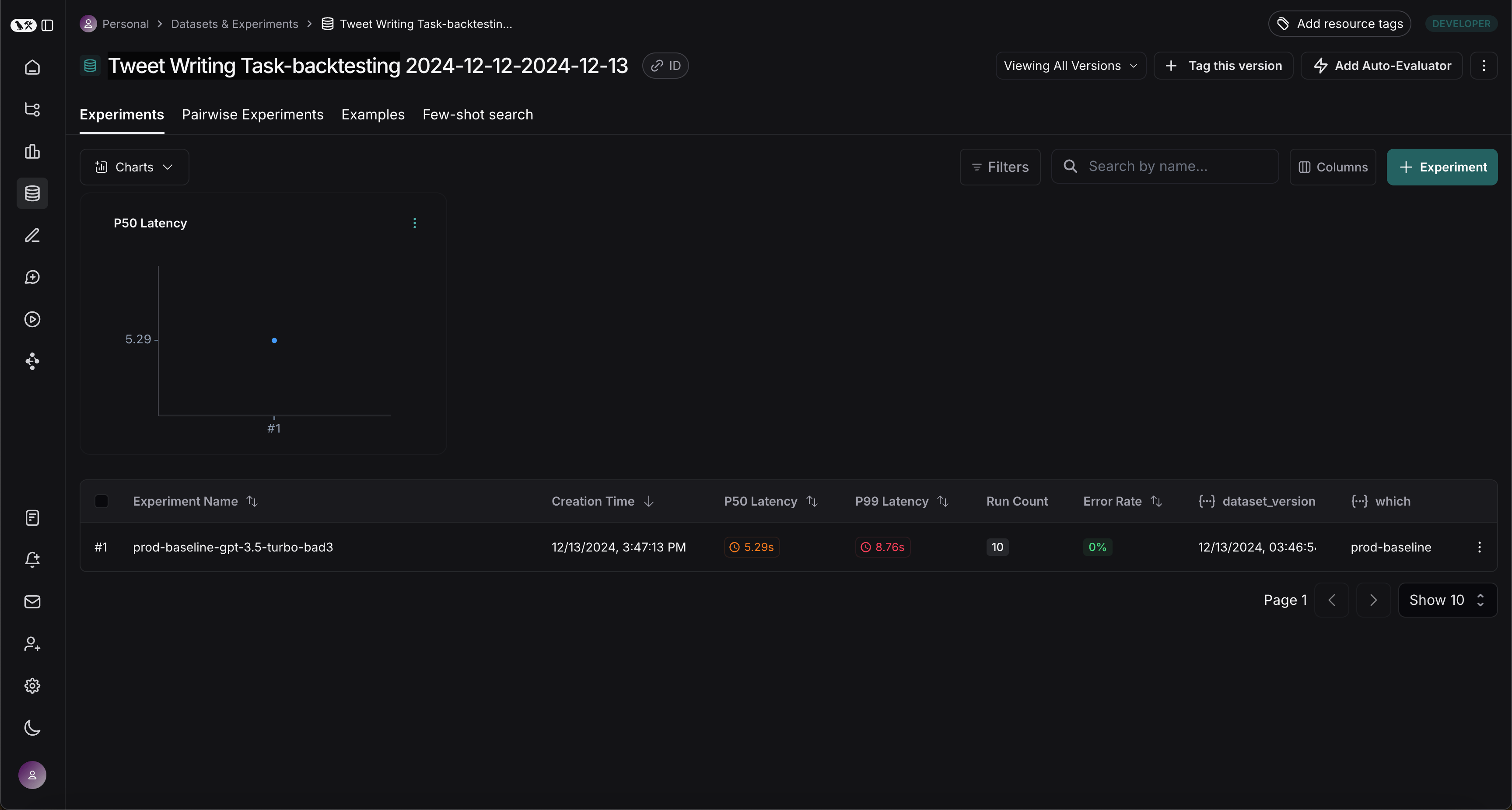
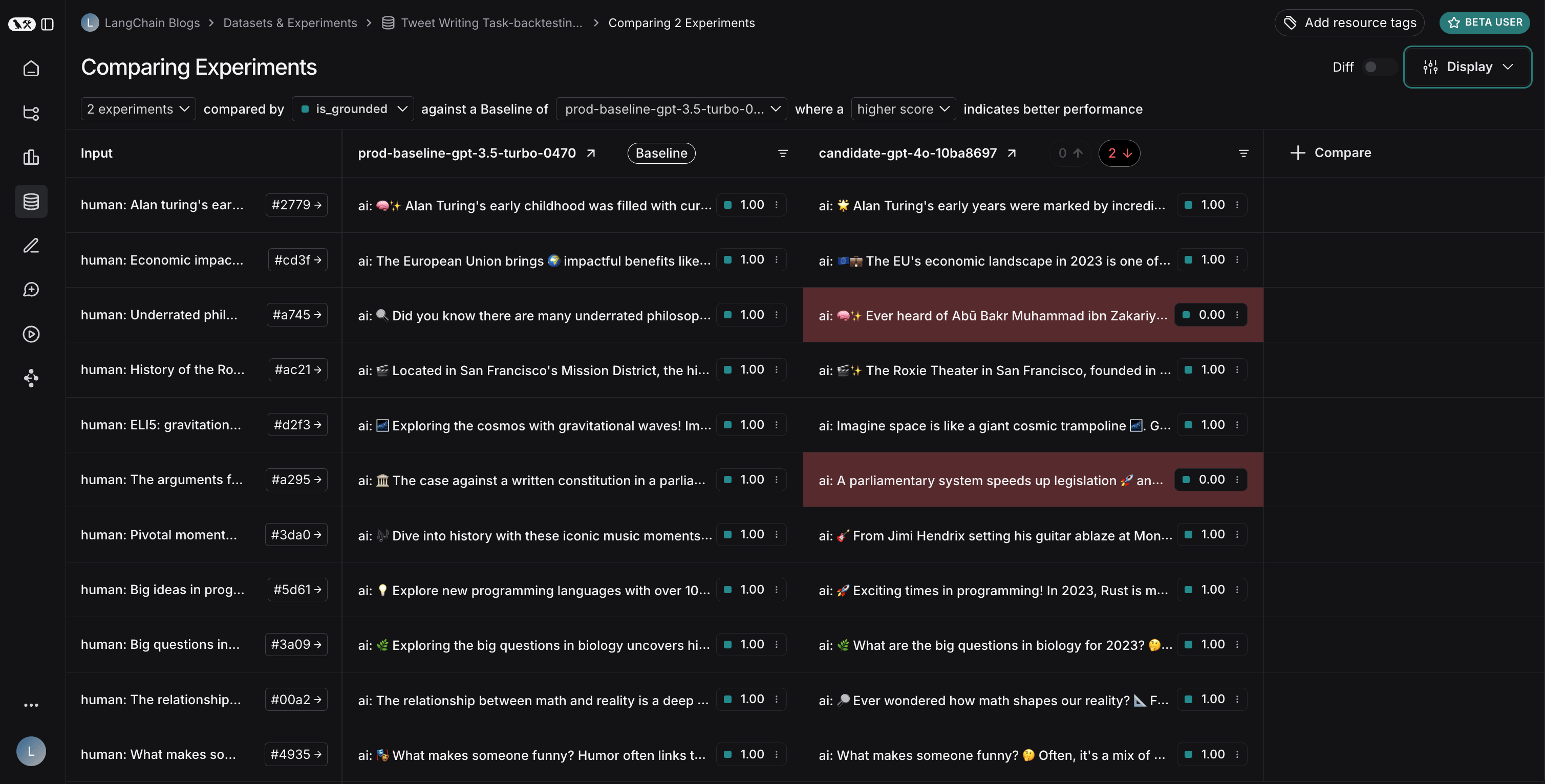
运行两个实验后,您可以在数据集中查看它们:
- GPT-4o 在遵循格式规则方面表现出改进,始终包含请求数量的表情符号
- 然而,GPT-4o 在保持基于提供的搜索结果方面不太可靠
- 优化我们的提示词,更加强调仅使用提供的信息
- 或者修改我们的系统架构,以更好地约束模型的输出
将这些文档通过 MCP 连接到 Claude、VSCode 等,以获取实时答案。