

对于Python中较大的评估任务,我们推荐使用 aevaluate(),它是 evaluate() 的异步版本。在阅读关于异步运行评估的操作指南之前,先阅读本指南仍然是值得的,因为两者具有相同的接口。在JS/TS中,evaluate()已经是异步的,因此不需要单独的方法。在运行大型任务时,配置
max_concurrency/maxConcurrency 参数也很重要。这可以通过有效地将数据集分配到线程中来并行化评估。定义应用
首先,我们需要一个待评估的应用。在本例中,让我们创建一个简单的毒性分类器。创建或选择数据集
我们需要一个数据集来评估我们的应用。我们的数据集将包含带标签的毒性文本和非毒性文本示例。 需要langsmith>=0.3.13
定义评估器
定义评估器主要有两种方式。在代码中本地定义
您也可以查看LangChain的开源评估包 openevals,其中包含常见的预构建评估器。
- Python:需要
langsmith>=0.3.13 - TypeScript:需要
langsmith>=0.2.9
在LangSmith UI中定义
您也可以在 LangSmith UI 中定义评估器。您可以在 评估器 选项卡下在UI中创建评估器。这些评估器将在每次新实验时自动触发。运行评估
我们将使用 evaluate() / aevaluate() 方法来运行评估。 关键参数是:- 一个目标函数,它接受一个输入字典并返回一个输出字典。每个示例的
example.inputs字段就是传递给目标函数的内容。在本例中,我们的toxicity_classifier已经设置为接受示例输入,因此我们可以直接使用它。 data- 要评估的LangSmith数据集的名称或UUID,或示例的迭代器。evaluators- 用于对函数输出进行评分的评估器列表;Langsmith UI 中的数据集评估器也会自动触发。metadata- 一个可选对象,附加到实验上。传递models、prompts和tools键以填充实验表视图中的相应列。
langsmith>=0.3.13
向实验添加元数据
元数据是一组键值对,您可以将其附加到实验上,以便在实验表中对实验进行分组和筛选。您可以在运行实验时通过metadata 参数传递元数据(参见运行评估),或者之后直接在LangSmith UI中添加。
要打开 编辑实验 面板,请将鼠标悬停在实验表中的实验行上,然后单击行右侧出现的 编辑 铅笔图标。
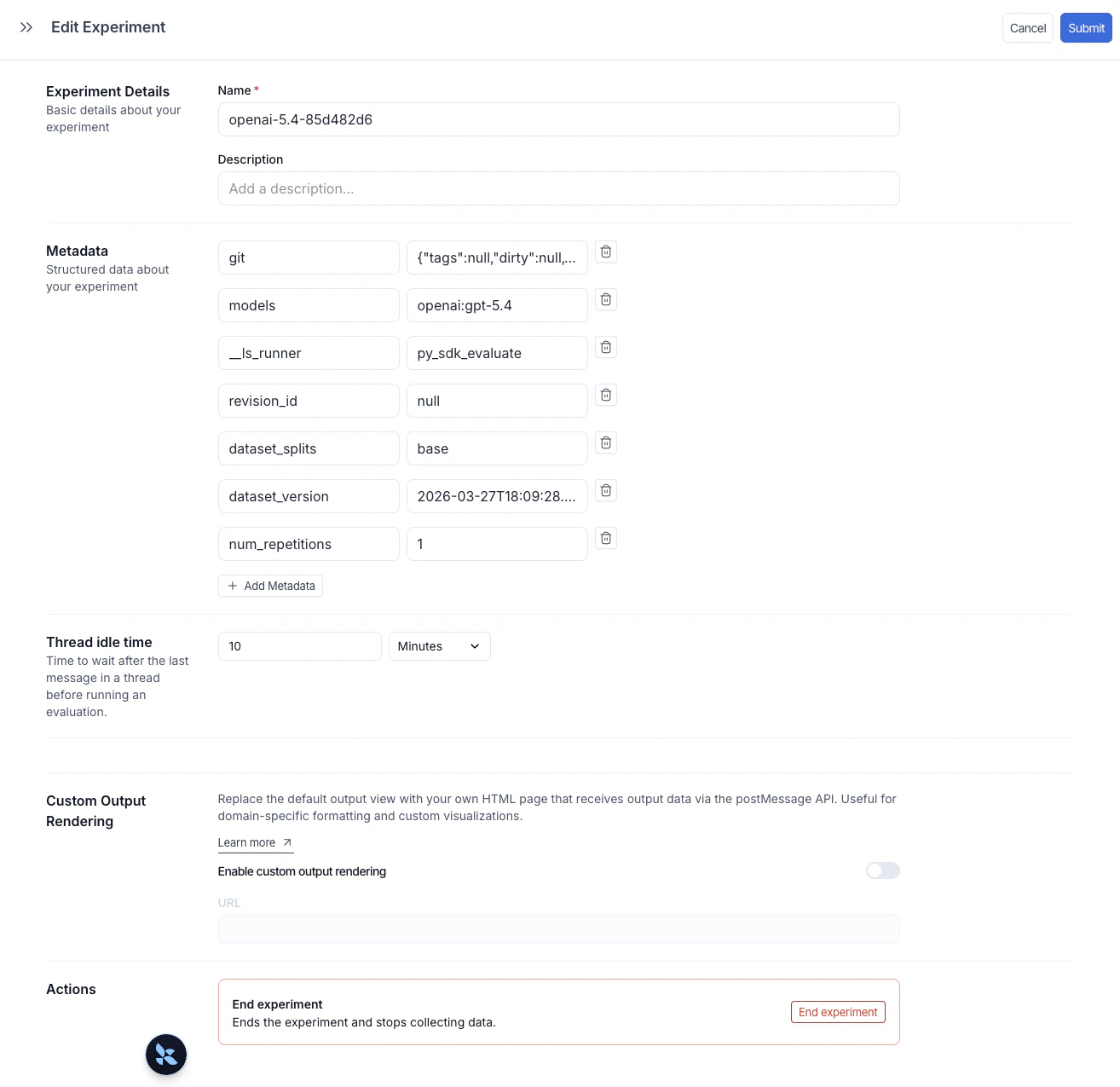
models、prompts 和 tools 键会自动填充实验表中的专用列。单击这些列中的值可以按其进行筛选或分组。有关完整详细信息,请参阅按模型、提示和工具筛选和分组。
探索结果
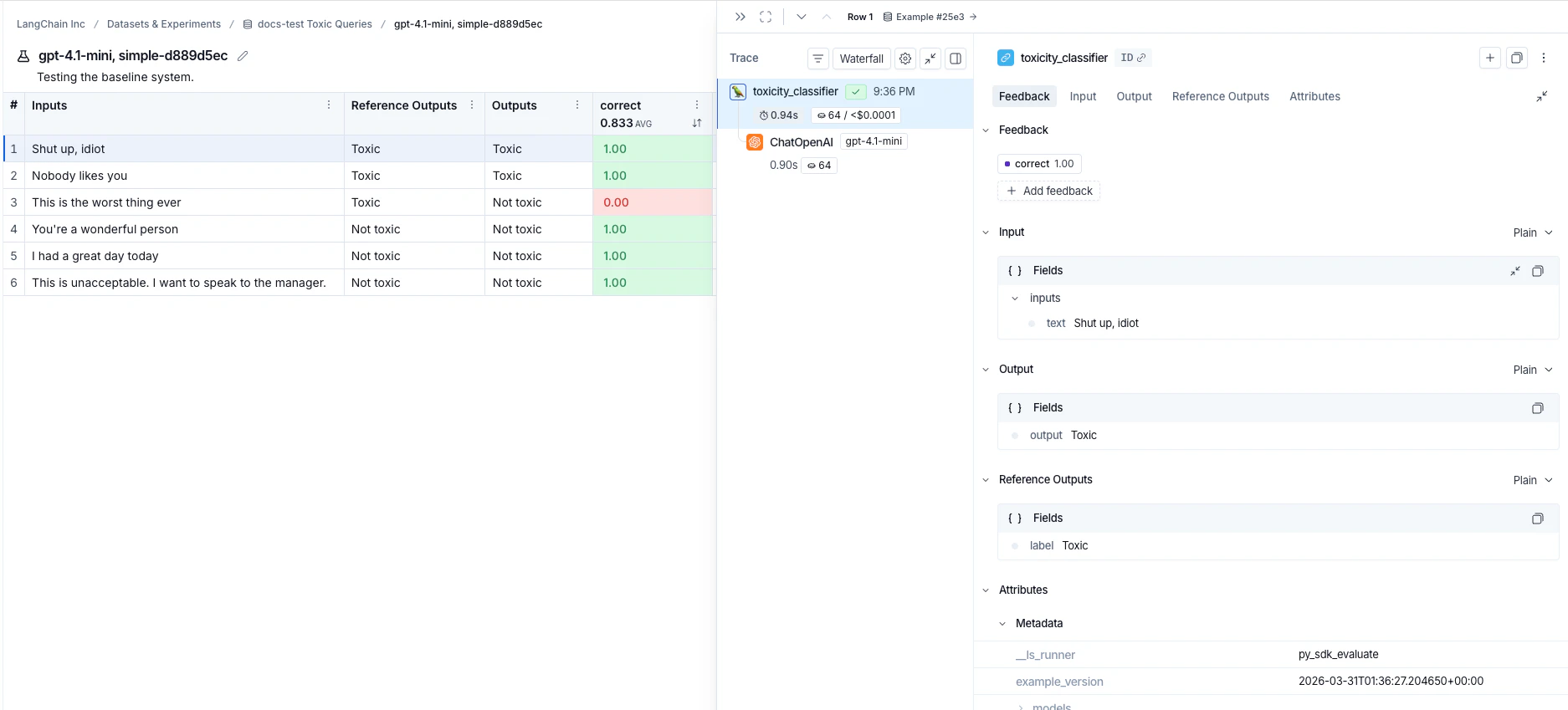
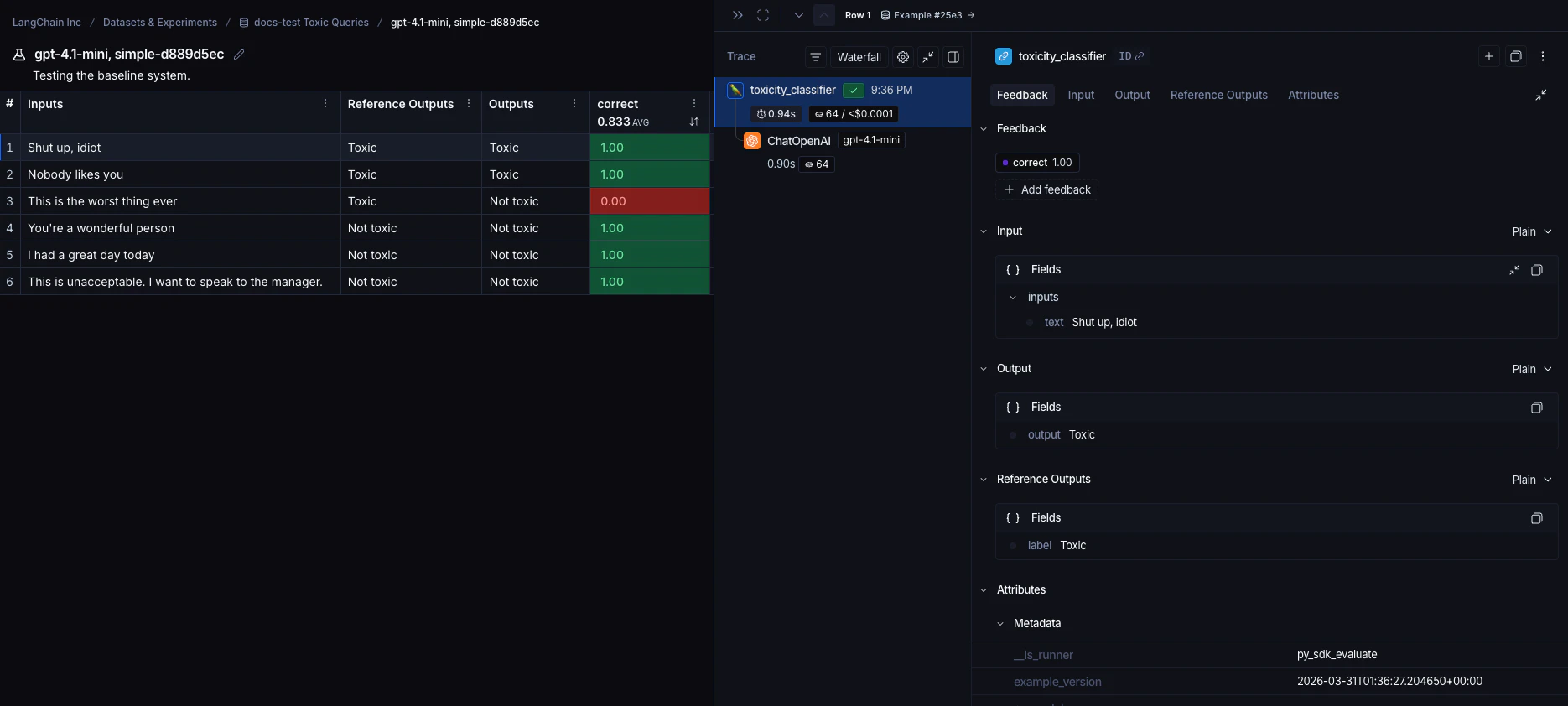
每次调用evaluate() 都会创建一个实验,您可以在LangSmith UI中查看或通过SDK查询。有关更多详细信息,请参阅分析实验。
针对数据集运行的实验列在实验表中。
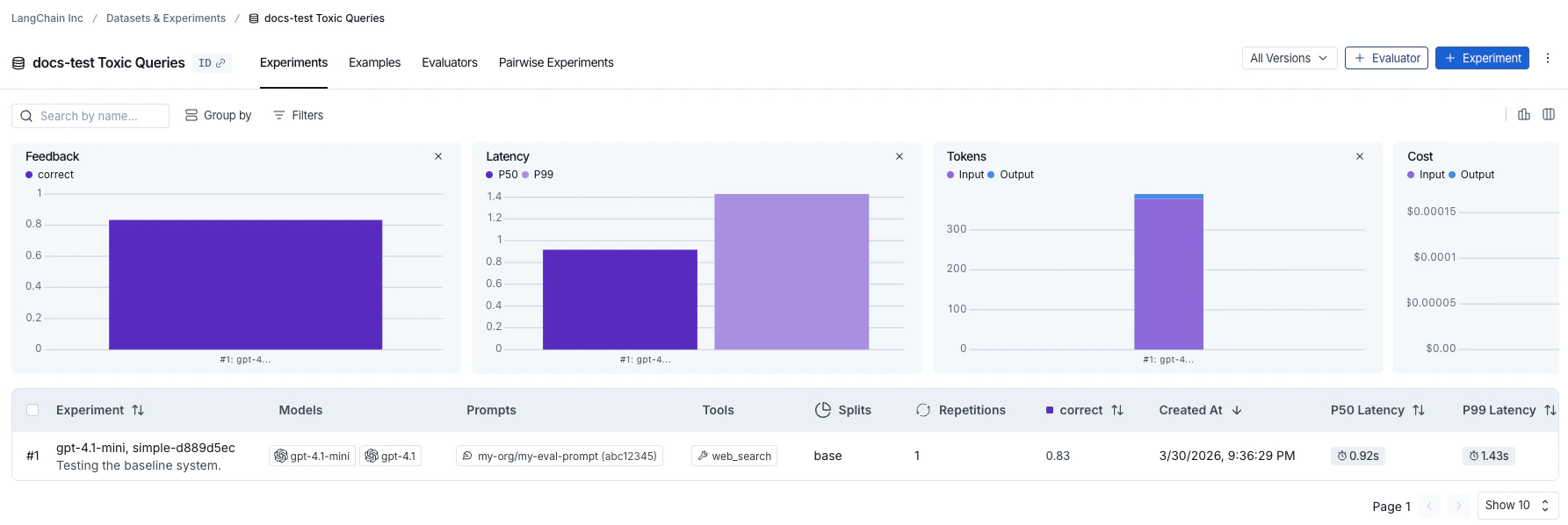


参考代码
点击查看合并的代码片段
点击查看合并的代码片段
相关内容
将这些文档通过MCP连接到Claude、VSCode等,以获取实时答案。