

- 每个示例需要不同的评估逻辑:标准评估流程假设对所有数据集示例一致地应用和执行评估器。对于更复杂的系统或全面的评估,特定的系统子集可能需要使用特定的输入类型和指标进行评估。这些异构评估作为一起跟踪的不同测试用例套件来编写会更简单。
- 你想要断言二元期望:在 LangSmith 中跟踪断言,并在本地(例如在 CI 流水线中)引发断言错误。当同时评估系统输出并断言其基本属性时,测试工具很有帮助。
- 你想要类似 pytest 的终端输出:获取熟悉的 pytest 输出格式
- 你已经使用 pytest 测试你的应用:将 LangSmith 跟踪添加到现有的 pytest 工作流中
JS/TS SDK 有一个类似的 Vitest/Jest 集成。
安装
此功能需要 Python SDK 版本langsmith>=0.3.4。
要获得额外功能,如丰富的终端输出和测试缓存,请安装:
定义和运行测试
pytest 集成允许你将数据集和评估器定义为测试用例。 要在 LangSmith 中跟踪测试,请添加@pytest.mark.langsmith 装饰器。每个装饰的测试用例都将同步到一个数据集示例。当你运行测试套件时,数据集将被更新,并创建一个新的实验,每个测试用例对应一个结果。
pass 布尔反馈键。它还将跟踪你记录的任何输入、输出和参考(预期)输出。
像往常一样使用 pytest 运行测试:
- 为每个测试文件创建一个数据集。如果此测试文件的数据集已存在,则会更新它
- 在每个创建/更新的数据集中创建一个实验
- 为每个测试用例创建一个实验行,包含你记录的输入、输出、参考输出和反馈
- 在
pass反馈键下收集每个测试用例的通过/失败率
记录输入、输出和参考输出
每次运行测试时,我们都会将其同步到数据集示例,并将其跟踪为一个运行。有几种不同的方法可以跟踪示例输入、参考输出和运行输出。最简单的方法是使用log_inputs、log_outputs 和 log_reference_outputs 方法。你可以在测试中的任何时候运行这些方法来更新该测试的示例和运行:
{"a": 1, "b": 2},参考输出为 {"foo": "bar"},并跟踪一个输出为 {"foo": "baz"} 的运行。
注意:如果你运行 log_inputs、log_outputs 或 log_reference_outputs 两次,之前的值将被覆盖。
定义示例输入和参考输出的另一种方法是通过 pytest fixtures/参数化。默认情况下,测试函数的任何参数都将作为相应示例上的输入记录。如果某些参数旨在表示参考输出,你可以使用 @pytest.mark.langsmith(output_keys=["name_of_ref_output_arg"]) 指定它们应被记录为参考输出:
{"c": 5},参考输出为 {"d": 6},运行输出为 {"d": 10}。
记录反馈
默认情况下,LangSmith 在pass 反馈键下收集每个测试用例的通过/失败率。你可以使用 log_feedback 添加额外的反馈。
trace_feedback() 上下文管理器的使用。这使得 LLM 作为评判者的调用与测试用例的其余部分分开跟踪。它不会出现在主测试用例运行中,而是出现在 correct 反馈键的跟踪中。
注意:确保与反馈跟踪相关的 log_feedback 调用发生在 trace_feedback 上下文内。这样我们就能将反馈与跟踪关联起来,并且在 UI 中看到反馈时,你可以点击它查看生成它的跟踪。
跟踪中间调用
LangSmith 会自动跟踪测试用例执行过程中发生的任何可跟踪的中间调用。将测试分组到测试套件中
默认情况下,给定文件中的所有测试将被分组为一个具有相应数据集的单一“测试套件”。你可以通过向@pytest.mark.langsmith 传递 test_suite_name 参数来配置测试所属的测试套件,以进行逐案分组,或者你可以设置 LANGSMITH_TEST_SUITE 环境变量,将执行中的所有测试分组到一个测试套件中:
LANGSMITH_TEST_SUITE 以获得所有结果的整合视图。
命名实验
你可以使用LANGSMITH_EXPERIMENT 环境变量为实验命名:
实验元数据
你可以将自定义元数据附加到每次测试运行创建的实验(项目)上。这对于跟踪给定实验使用了哪个模型、提示版本或环境非常有用。 选项 1:Fixture(推荐) 在你的conftest.py 中定义一个会话范围的 fixture:
conftest.py 层次结构,因此可以按目录限定范围。
选项 2:环境变量
将 LANGSMITH_EXPERIMENT_METADATA 设置为 JSON 字符串。这在 CI/CD 流水线中很有用,你不想修改代码:
revision_id 和 git 信息)始终优先于用户提供的键。
此功能需要
langsmith>=0.7.13。缓存
CI 中每次提交都运行 LLM 可能会很昂贵。为了节省时间和资源,LangSmith 允许你将 HTTP 请求缓存到磁盘。要启用缓存,请使用langsmith[pytest] 安装并设置环境变量:LANGSMITH_TEST_CACHE=/my/cache/path:
tests/cassettes,并在后续运行中从那里加载。如果你将此提交到你的仓库,你的 CI 也将能够使用缓存。
在 langsmith>=0.4.10 中,你可以选择性地为对单个 URL 或主机名的请求启用缓存,如下所示:
pytest 功能
@pytest.mark.langsmith 旨在不干扰你,并与熟悉的 pytest 功能配合良好。
使用 pytest.mark.parametrize 进行参数化
你可以像以前一样使用 parametrize 装饰器。这将为测试的每个参数化实例创建一个新的测试用例。
evaluate()。这可以并行化评估,并更容易控制单个实验和相应的数据集。
使用 pytest-xdist 进行并行化
你可以像往常一样使用 pytest-xdist 来并行化测试执行:
使用 pytest-asyncio 进行异步测试
@pytest.mark.langsmith 适用于同步或异步测试,因此你可以像以前一样运行异步测试。
使用 pytest-watch 进行监视模式
使用监视模式快速迭代你的测试。我们强烈建议仅在启用测试缓存(见下文)时使用此功能,以避免不必要的 LLM 调用:
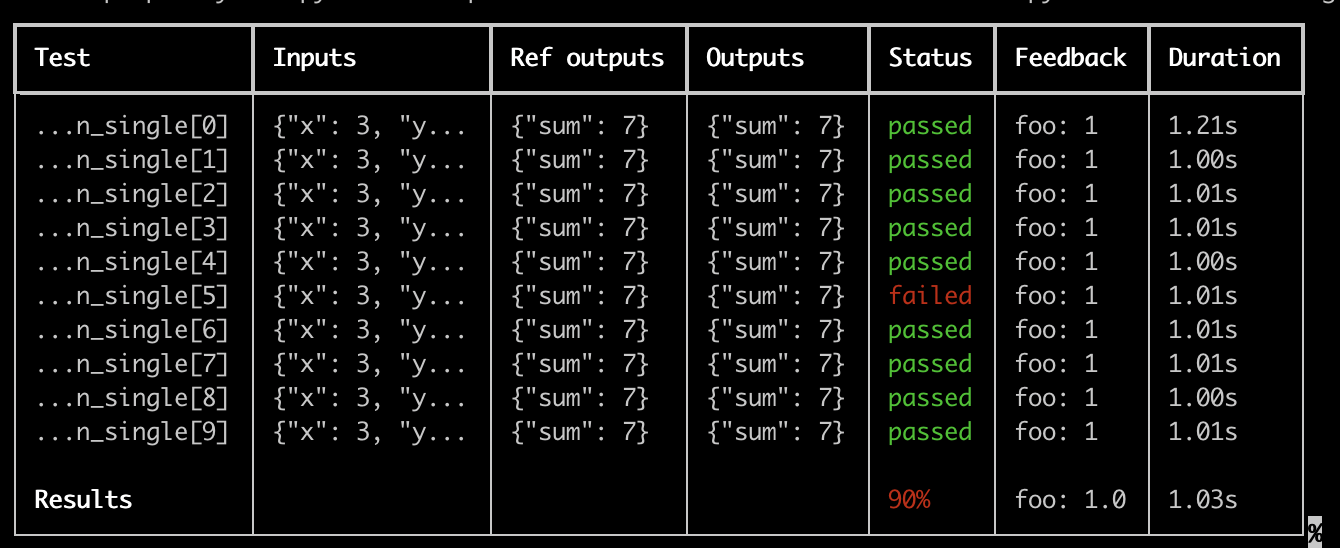
丰富的输出
如果你想查看测试运行的 LangSmith 结果的丰富显示,可以指定--langsmith-output:
langsmith<=0.3.3 中曾是 --output=langsmith,但已更新以避免与其他 pytest 插件冲突。
你将获得每个测试套件的一个漂亮的表格,随着结果上传到 LangSmith 而实时更新:
- 确保你已安装
pip install -U "langsmith[pytest]" - 丰富的输出目前不适用于
pytest-xdist
自定义输出会移除所有标准 pytest 输出。如果你试图调试一些意外行为,最好显示常规 pytest 输出以获取完整的错误跟踪。
干运行模式
如果你想在不将结果同步到 LangSmith 的情况下运行测试,可以在环境中设置LANGSMITH_TEST_TRACKING=false。
期望
LangSmith 提供了一个 expect 工具来帮助定义对 LLM 输出的期望。例如:expect 还提供“模糊匹配”方法。例如:
- 预测和期望之间的
embedding_distance - 二元
expectation分数(如果余弦距离小于 0.5 则为 1,否则为 0) - 预测和期望之间的
edit_distance - 整体测试通过/失败分数(二元)
expect 工具是基于 Jest 的 expect API 建模的,具有一些现成功能,使评分 LLM 更容易。
旧版
@test / @unit 装饰器
标记测试用例的旧方法是使用 @test 或 @unit 装饰器:
将这些文档连接到 Claude、VSCode 等,通过 MCP 获取实时答案。