


evaluate() 评估流程相比,Vitest 或 Jest 测试框架在以下情况下很有用:
- 每个示例需要不同的评估逻辑:标准评估流程假设对所有数据集示例一致地应用和执行评估器。对于更复杂的系统或全面的评估,特定的系统子集可能需要使用特定的输入类型和指标进行评估。这些异构评估作为一起跟踪的不同测试用例套件来编写会更简单。
- 你想要断言二元期望:在 LangSmith 中跟踪断言,并在本地(例如在 CI 流水线中)引发断言错误。当同时评估系统输出并断言其基本属性时,测试工具很有帮助。
- 你想要利用 Vitest/Jest 生态系统的 mocks、监视模式、本地结果或其他功能。
需要 JS/TS SDK 版本
langsmith>=0.3.1。Python SDK 有一个类似的 pytest 集成。
设置
按如下方式设置集成。请注意,虽然你可以使用现有的测试配置文件将 LangSmith 评估与其他单元测试(作为标准的*.test.ts 文件)一起添加,但下面的示例还将设置一个单独的测试配置文件和命令来运行你的评估。它将假设你的测试文件以 .eval.ts 结尾。
这确保了自定义测试报告器和其他 LangSmith 接触点不会修改你现有的测试输出。
Vitest
如果尚未安装,请安装所需的开发依赖项:openai(和 langsmith)作为依赖项:
ls.vitest.config.ts 文件,包含以下基础配置:
include确保只运行项目中以eval.ts的某种变体结尾的文件reporters负责将你的输出格式化为如上所示setupFiles在运行评估之前运行dotenv以加载环境变量testTimeout为每个测试设置全局默认超时时间。因为 LLM 调用可能很慢,我们将其从 Vitest 默认值增加
package.json 的 scripts 字段中添加以下内容,以使用你刚创建的配置运行 Vitest:
Jest
如果尚未安装,请安装所需的开发依赖项:openai(和 langsmith)作为依赖项:
以下设置说明适用于基本的 JS 文件和 CJS。要添加对 TypeScript 和 ESM 的支持,请参阅 Jest 的官方文档或使用 Vitest。
ls.jest.config.cjs 的单独配置文件:
testMatch确保只运行项目中以eval.js的某种变体结尾的文件reporters负责将你的输出格式化为如上所示setupFiles在运行评估之前运行dotenv以加载环境变量testTimeout为每个测试设置全局默认超时时间。因为 LLM 调用可能很慢,我们将其从 Jest 默认值增加
package.json 的 scripts 字段中添加以下内容,以使用你刚创建的配置运行 Jest:
定义并运行评估
你现在可以使用熟悉的 Vitest/Jest 语法将评估定义为测试,但有几点注意事项:- 你应该从
langsmith/jest或langsmith/vitest入口点导入describe和test。 - 你必须将测试用例包装在
describe块中。 - 声明测试时,签名略有不同——有一个额外的参数包含示例输入和预期输出。
sql.eval.ts(或者如果你在不使用 TypeScript 的情况下使用 Jest,则为 sql.eval.js)的文件并粘贴以下代码来尝试:
ls.describe() 视为定义一个 LangSmith 数据集。如果你在运行测试套件时设置了 LangSmith 跟踪环境变量,SDK 将执行以下操作:
- 如果不存在,则在 LangSmith 中创建一个与传递给
ls.describe()的名称同名的数据集。 - 如果不存在匹配的示例,则在数据集中为传递给测试用例的每个输入和预期输出创建一个示例。
- 创建一个新的实验,其中包含每个测试用例的一个结果。
- 在
pass反馈键下收集每个测试用例的通过/失败率。
pass 布尔反馈键。它还将跟踪你使用 ls.logOutputs() 记录的任何输出,或从测试函数返回的输出,作为实验中来自你应用的“实际”结果值。
如果你还没有,请创建一个包含你的 OPENAI_API_KEY 和 LangSmith 凭据的 .env 文件:
eval 脚本来运行测试:
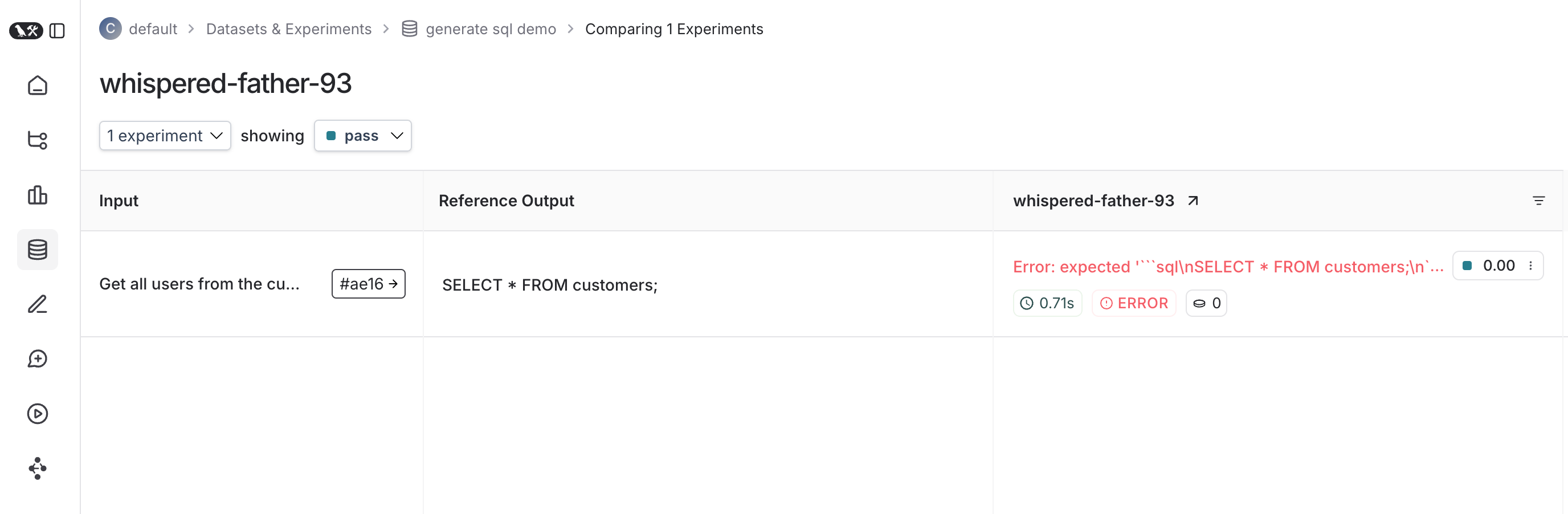
跟踪反馈
默认情况下,LangSmith 在pass 反馈键下收集每个测试用例的通过/失败率。你可以使用 ls.logFeedback() 或 ls.wrapEvaluator() 添加额外的反馈。为此,请尝试将以下内容作为你的 sql.eval.ts 文件(或者如果你在不使用 TypeScript 的情况下使用 Jest,则为 sql.eval.js):
myEvaluator 函数周围使用了 ls.wrapEvaluator()。这使得 LLM 作为评判者的调用与测试用例的其余部分分开跟踪,以避免混乱,并且如果包装函数的返回值匹配 { key: string; score: number | boolean },则会方便地创建反馈。在这种情况下,评估器跟踪将显示在与 correctness 反馈键关联的跟踪中,而不是显示在主测试用例运行中。
你可以通过在 UI 中单击相应的反馈芯片来查看 LangSmith 中的评估器运行。
对测试用例运行多个示例
你可以对多个示例运行相同的测试用例,并使用ls.test.each() 参数化你的测试。当你想要以相同的方式针对不同输入评估你的应用时,这很有用:
使用现有数据集(仅限 Vitest)
你可以针对 LangSmith 中的现有数据集运行测试,而不是内联定义示例:- 使用
client.listExamples()从 LangSmith 中已存在的数据集获取示例。 - 通过迭代异步生成器将示例收集到一个数组中(例如
testExamples)。 - 将数组传递给
ls.test.each(),以针对数据集中的每个示例运行你的测试逻辑。
记录输出
每次我们运行测试时,我们都会将其同步到数据集示例并将其跟踪为一次运行。要跟踪运行的最终输出,你可以像这样使用ls.logOutputs():
跟踪中间调用
LangSmith 将自动跟踪在测试用例执行过程中发生的任何可跟踪的中间调用。聚焦或跳过测试
你可以在ls.test() 和 ls.describe() 上链接 Vitest/Jest 的 .skip 和 .only 方法:
配置测试套件
你可以通过向ls.describe() 传递一个额外的参数来为整个套件配置测试套件,或者通过向 ls.test() 传递一个 config 字段来为单个测试配置测试套件,例如元数据或自定义客户端:
process.env.ENVIRONMENT、process.env.NODE_ENV 和 process.env.LANGSMITH_ENVIRONMENT 中提取环境变量,并将它们设置为创建的实验的元数据。然后你可以在 LangSmith 的 UI 中按元数据过滤实验。
有关配置选项的完整列表,请参阅 API 参考。
试运行模式
如果你想在不将结果同步到 LangSmith 的情况下运行测试,你可以省略 LangSmith 跟踪环境变量或在环境中设置LANGSMITH_TEST_TRACKING=false。
测试将正常运行,但实验日志不会发送到 LangSmith。
将这些文档通过 MCP 连接到 Claude、VSCode 等,以获取实时答案。