

构建 SQL 数据库的问答系统需要执行模型生成的 SQL
查询。这样做存在固有风险。请确保您的数据库连接权限始终尽可能严格地限定在代理所需范围内。这将减轻(但不能消除)构建模型驱动系统的风险。
概念
我们将涵盖以下概念:- 用于从 SQL 数据库读取的工具
- LangGraph 图 API,包括状态、节点、边和条件边。
- Human in the Loop流程
设置
安装
npm i langchain @langchain/core @langchain/classic @langchain/langgraph @langchain/openai typeorm sqlite3 zod
yarn add langchain @langchain/core @langchain/classic @langchain/langgraph @langchain/openai typeorm sqlite3 zod
pnpm add langchain @langchain/core @langchain/classic @langchain/langgraph @langchain/openai typeorm sqlite3 zod
LangSmith
设置 LangSmith 以检查链或代理内部发生的情况。然后设置以下环境变量:export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="..."
1. 选择一个 LLM
选择一个支持工具调用的模型:- OpenAI
- Anthropic
- Azure
- Google Gemini
- Bedrock Converse
👉 阅读 OpenAI 聊天模型集成文档
npm install @langchain/openai
pnpm install @langchain/openai
yarn add @langchain/openai
bun add @langchain/openai
import { initChatModel } from "langchain";
process.env.OPENAI_API_KEY = "your-api-key";
const model = await initChatModel("gpt-5.4");
import { ChatOpenAI } from "@langchain/openai";
const model = new ChatOpenAI({
model: "gpt-5.4",
apiKey: "your-api-key"
});
👉 阅读 Anthropic 聊天模型集成文档
npm install @langchain/anthropic
pnpm install @langchain/anthropic
yarn add @langchain/anthropic
pnpm add @langchain/anthropic
import { initChatModel } from "langchain";
process.env.ANTHROPIC_API_KEY = "your-api-key";
const model = await initChatModel("claude-sonnet-4-6");
import { ChatAnthropic } from "@langchain/anthropic";
const model = new ChatAnthropic({
model: "claude-sonnet-4-6",
apiKey: "your-api-key"
});
👉 阅读 Azure 聊天模型集成文档
npm install @langchain/azure
pnpm install @langchain/azure
yarn add @langchain/azure
bun add @langchain/azure
import { initChatModel } from "langchain";
process.env.AZURE_OPENAI_API_KEY = "your-api-key";
process.env.AZURE_OPENAI_ENDPOINT = "your-endpoint";
process.env.OPENAI_API_VERSION = "your-api-version";
const model = await initChatModel("azure_openai:gpt-5.4");
import { AzureChatOpenAI } from "@langchain/openai";
const model = new AzureChatOpenAI({
model: "gpt-5.4",
azureOpenAIApiKey: "your-api-key",
azureOpenAIApiEndpoint: "your-endpoint",
azureOpenAIApiVersion: "your-api-version"
});
👉 阅读 Google GenAI 聊天模型集成文档
npm install @langchain/google-genai
pnpm install @langchain/google-genai
yarn add @langchain/google-genai
bun add @langchain/google-genai
import { initChatModel } from "langchain";
process.env.GOOGLE_API_KEY = "your-api-key";
const model = await initChatModel("google-genai:gemini-2.5-flash-lite");
import { ChatGoogleGenerativeAI } from "@langchain/google-genai";
const model = new ChatGoogleGenerativeAI({
model: "gemini-2.5-flash-lite",
apiKey: "your-api-key"
});
👉 阅读 AWS Bedrock 聊天模型集成文档
npm install @langchain/aws
pnpm install @langchain/aws
yarn add @langchain/aws
bun add @langchain/aws
import { initChatModel } from "langchain";
// 按照此处的步骤配置您的凭据:
// https://docs.aws.amazon.com/bedrock/latest/userguide/getting-started.html
const model = await initChatModel("bedrock:gpt-5.4");
import { ChatBedrockConverse } from "@langchain/aws";
// 按照此处的步骤配置您的凭据:
// https://docs.aws.amazon.com/bedrock/latest/userguide/getting-started.html
const model = new ChatBedrockConverse({
model: "gpt-5.4",
region: "us-east-2"
});
2. 配置数据库
您将为本教程创建一个 SQLite 数据库。SQLite 是一个轻量级数据库,易于设置和使用。我们将加载chinook 数据库,这是一个代表数字媒体商店的示例数据库。
为方便起见,我们将数据库(Chinook.db)托管在一个公共的 GCS 存储桶中。
import fs from "node:fs/promises";
import path from "node:path";
const url =
"https://storage.googleapis.com/benchmarks-artifacts/chinook/Chinook.db";
const localPath = path.resolve("Chinook.db");
async function resolveDbPath() {
const exists = await fs
.access(localPath)
.then(() => true)
.catch(() => false);
if (exists) {
console.log(`${localPath} already exists, skipping download.`);
return localPath;
}
const resp = await fetch(url);
if (!resp.ok)
throw new Error(`Failed to download DB. Status code: ${resp.status}`);
const buf = Buffer.from(await resp.arrayBuffer());
await fs.writeFile(localPath, buf);
console.log(`File downloaded and saved as ${localPath}`);
return localPath;
}
@langchain/classic/sql_db 模块中提供的便捷 SQL 数据库包装器与数据库交互。该包装器提供了一个简单的接口来执行 SQL 查询和获取结果:
import { SqlDatabase } from "@langchain/classic/sql_db";
import { DataSource } from "typeorm";
const dbPath = await resolveDbPath();
const datasource = new DataSource({ type: "sqlite", database: dbPath });
const db = await SqlDatabase.fromDataSourceParams({
appDataSource: datasource,
});
const dialect = db.appDataSourceOptions.type;
console.log(`Dialect: ${dialect}`);
const tableNames = db.allTables.map((t) => t.tableName);
console.log(`Available tables: ${tableNames.join(", ")}`);
const sampleResults = await db.run("SELECT * FROM Artist LIMIT 5;");
console.log(`Sample output: ${sampleResults}`);
Dialect: sqlite
Available tables: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Sample output: [{"ArtistId":1,"Name":"AC/DC"},{"ArtistId":2,"Name":"Accept"},{"ArtistId":3,"Name":"Aerosmith"},{"ArtistId":4,"Name":"Alanis Morissette"},{"ArtistId":5,"Name":"Alice In Chains"}]
3. 添加用于数据库交互的工具
我们将创建自定义工具来与数据库交互:import { tool } from "langchain";
import * as z from "zod";
// 列出所有表的工具
const listTablesTool = tool(
async () => {
const tableNames = db.allTables.map((t) => t.tableName);
return tableNames.join(", ");
},
{
name: "sql_db_list_tables",
description: "输入是一个空字符串,输出是数据库中以逗号分隔的表列表。",
schema: z.object({}),
},
);
// 获取特定表结构的工具
const getSchemaTool = tool(
async ({ table_names }) => {
const tables = table_names.split(",").map((t) => t.trim());
return await db.getTableInfo(tables);
},
{
name: "sql_db_schema",
description:
"此工具的输入是以逗号分隔的表列表,输出是这些表的结构和示例行。请务必先调用 sql_db_list_tables 以确保表确实存在!示例输入:table1, table2, table3",
schema: z.object({
table_names: z.string().describe("以逗号分隔的表名列表"),
}),
},
);
// 执行 SQL 查询的工具
const queryTool = tool(
async ({ query }) => {
try {
const result = await db.run(query);
return typeof result === "string" ? result : JSON.stringify(result);
} catch (error) {
return `Error: ${error.message}`;
}
},
{
name: "sql_db_query",
description:
"此工具的输入是一个详细且正确的 SQL 查询,输出是来自数据库的结果。如果查询不正确,将返回错误消息。如果返回错误,请重写查询,检查查询,然后重试。",
schema: z.object({
query: z.string().describe("要执行的 SQL 查询"),
}),
},
);
const tools = [listTablesTool, getSchemaTool, queryTool];
for (const tool of tools) {
console.log(`${tool.name}: ${tool.description}\n`);
}
sql_db_list_tables: 输入是一个空字符串,输出是数据库中以逗号分隔的表列表。
sql_db_schema: 此工具的输入是以逗号分隔的表列表,输出是这些表的结构和示例行。请务必先调用 sql_db_list_tables 以确保表确实存在!示例输入:table1, table2, table3
sql_db_query: 此工具的输入是一个详细且正确的 SQL 查询,输出是来自数据库的结果。如果查询不正确,将返回错误消息。如果返回错误,请重写查询,检查查询,然后重试。
4. 定义应用步骤
我们为以下步骤构建专用节点:- 列出数据库表
- 调用“获取结构”工具
- 生成查询
- 检查查询
import {
AIMessage,
ToolMessage,
SystemMessage,
HumanMessage,
} from "@langchain/core/messages";
import { ToolNode } from "@langchain/langgraph/prebuilt";
import {
StateSchema,
MessagesValue,
GraphNode,
StateGraph,
START,
END,
} from "@langchain/langgraph";
import { z } from "zod/v4";
// 为结构和查询执行创建工具节点
const getSchemaNode = new ToolNode([getSchemaTool]);
const runQueryNode = new ToolNode([queryTool]);
// 定义状态模式
const MessagesState = new StateSchema({
messages: MessagesValue,
});
// 示例:创建一个预定的工具调用
const listTables: GraphNode<typeof MessagesState> = async (state) => {
const toolCall = {
name: "sql_db_list_tables",
args: {},
id: "abc123",
type: "tool_call" as const,
};
const toolCallMessage = new AIMessage({
content: "",
tool_calls: [toolCall],
});
const toolMessage = await listTablesTool.invoke({});
const response = new AIMessage(`Available tables: ${toolMessage}`);
return {
messages: [
toolCallMessage,
new ToolMessage({ content: toolMessage, tool_call_id: "abc123" }),
response,
],
};
};
// 示例:强制模型创建一个工具调用
const callGetSchema: GraphNode<typeof MessagesState> = async (state) => {
const llmWithTools = model.bindTools([getSchemaTool], {
tool_choice: "any",
});
const response = await llmWithTools.invoke(state.messages);
return { messages: [response] };
};
const topK = 5;
const generateQuerySystemPrompt = `
你是一个旨在与 SQL 数据库交互的代理。
给定一个输入问题,创建一个语法正确的 ${dialect}
查询来运行,然后查看查询结果并返回答案。除非
用户指定了他们希望获得的特定示例数量,否则始终将
查询限制为最多 ${topK} 个结果。
你可以按相关列对结果进行排序,以返回数据库中最有趣的
示例。永远不要查询特定表中的所有列,
只根据问题请求相关列。
不要对数据库执行任何 DML 语句(INSERT、UPDATE、DELETE、DROP 等)。
`;
const generateQuery: GraphNode<typeof MessagesState> = async (state) => {
const systemMessage = new SystemMessage(generateQuerySystemPrompt);
// 我们在这里不强制进行工具调用,以允许模型在
// 获得解决方案时自然地响应。
const llmWithTools = model.bindTools([queryTool]);
const response = await llmWithTools.invoke([
systemMessage,
...state.messages,
]);
return { messages: [response] };
};
const checkQuerySystemPrompt = `
你是一个注重细节的 SQL 专家。
仔细检查 ${dialect} 查询中的常见错误,包括:
- 在 NULL 值上使用 NOT IN
- 在应该使用 UNION ALL 时使用了 UNION
- 使用 BETWEEN 表示排他范围
- 谓词中的数据类型不匹配
- 正确引用标识符
- 为函数使用正确数量的参数
- 转换为正确的数据类型
- 为连接使用正确的列
如果存在上述任何错误,请重写查询。如果没有错误,
只需重现原始查询。
运行此检查后,你将调用适当的工具来执行查询。
`;
const checkQuery: GraphNode<typeof MessagesState> = async (state) => {
const systemMessage = new SystemMessage(checkQuerySystemPrompt);
// 生成一个用于检查的人工用户消息
const lastMessage = state.messages[state.messages.length - 1];
if (!lastMessage.tool_calls || lastMessage.tool_calls.length === 0) {
throw new Error("No tool calls found in the last message");
}
const toolCall = lastMessage.tool_calls[0];
const userMessage = new HumanMessage(toolCall.args.query);
const llmWithTools = model.bindTools([queryTool], {
tool_choice: "any",
});
const response = await llmWithTools.invoke([systemMessage, userMessage]);
// 保留原始消息 ID
response.id = lastMessage.id;
return { messages: [response] };
};
5. 实现代理
我们现在可以使用 图 API 将这些步骤组装成一个工作流。我们在查询生成步骤定义了一个条件边,如果生成了查询,则路由到查询检查器,或者如果没有工具调用存在(即 LLM 已经对查询给出了响应),则结束。import { StateGraph, ConditionalEdgeRouter } from "@langchain/langgraph";
const shouldContinue: ConditionalEdgeRouter<
typeof MessagesState,
"check_query"
> = (state) => {
const messages = state.messages;
const lastMessage = messages[messages.length - 1];
if (!lastMessage.tool_calls || lastMessage.tool_calls.length === 0) {
return END;
} else {
return "check_query";
}
};
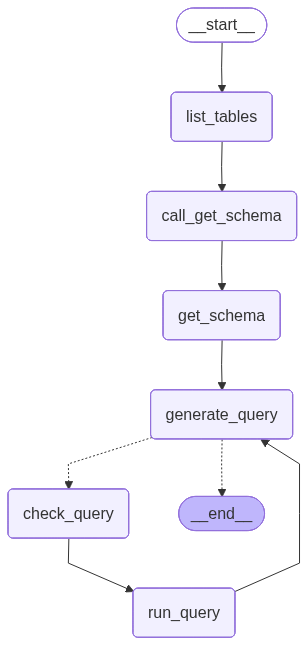
const builder = new StateGraph(MessagesState)
.addNode("list_tables", listTables)
.addNode("call_get_schema", callGetSchema)
.addNode("get_schema", getSchemaNode)
.addNode("generate_query", generateQuery)
.addNode("check_query", checkQuery)
.addNode("run_query", runQueryNode)
.addEdge(START, "list_tables")
.addEdge("list_tables", "call_get_schema")
.addEdge("call_get_schema", "get_schema")
.addEdge("get_schema", "generate_query")
.addConditionalEdges("generate_query", shouldContinue)
.addEdge("check_query", "run_query")
.addEdge("run_query", "generate_query");
const agent = builder.compile();
import * as fs from "node:fs/promises";
const drawableGraph = await agent.getGraphAsync();
const image = await drawableGraph.drawMermaidPng();
const imageBuffer = new Uint8Array(await image.arrayBuffer());
await fs.writeFile("graph.png", imageBuffer);
const question = "Which genre on average has the longest tracks?";
const stream = await agent.stream(
{ messages: [{ role: "user", content: question }] },
{ streamMode: "values" },
);
for await (const step of stream) {
if (step.messages && step.messages.length > 0) {
const lastMessage = step.messages[step.messages.length - 1];
console.log(lastMessage.toFormattedString());
}
}
================================ Human Message =================================
Which genre on average has the longest tracks?
================================== Ai Message ==================================
Available tables: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
================================== Ai Message ==================================
Tool Calls:
sql_db_schema (call_yzje0tj7JK3TEzDx4QnRR3lL)
Call ID: call_yzje0tj7JK3TEzDx4QnRR3lL
Args:
table_names: Genre, Track
================================= Tool Message =================================
Name: sql_db_schema
CREATE TABLE "Genre" (
"GenreId" INTEGER NOT NULL,
"Name" NVARCHAR(120),
PRIMARY KEY ("GenreId")
)
/*
3 rows from Genre table:
GenreId Name
1 Rock
2 Jazz
3 Metal
*/
CREATE TABLE "Track" (
"TrackId" INTEGER NOT NULL,
"Name" NVARCHAR(200) NOT NULL,
"AlbumId" INTEGER,
"MediaTypeId" INTEGER NOT NULL,
"GenreId" INTEGER,
"Composer" NVARCHAR(220),
"Milliseconds" INTEGER NOT NULL,
"Bytes" INTEGER,
"UnitPrice" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("TrackId"),
FOREIGN KEY("MediaTypeId") REFERENCES "MediaType" ("MediaTypeId"),
FOREIGN KEY("GenreId") REFERENCES "Genre" ("GenreId"),
FOREIGN KEY("AlbumId") REFERENCES "Album" ("AlbumId")
)
/*
3 rows from Track table:
TrackId Name AlbumId MediaTypeId GenreId Composer Milliseconds Bytes UnitPrice
1 For Those About To Rock (We Salute You) 1 1 1 Angus Young, Malcolm Young, Brian Johnson 343719 11170334 0.99
2 Balls to the Wall 2 2 1 U. Dirkschneider, W. Hoffmann, H. Frank, P. Baltes, S. Kaufmann, G. Hoffmann 342562 5510424 0.99
3 Fast As a Shark 3 2 1 F. Baltes, S. Kaufman, U. Dirkscneider & W. Hoffman 230619 3990994 0.99
*/
================================== Ai Message ==================================
Tool Calls:
sql_db_query (call_cb9ApLfZLSq7CWg6jd0im90b)
Call ID: call_cb9ApLfZLSq7CWg6jd0im90b
Args:
query: SELECT Genre.Name, AVG(Track.Milliseconds) AS AvgMilliseconds FROM Track JOIN Genre ON Track.GenreId = Genre.GenreId GROUP BY Genre.GenreId ORDER BY AvgMilliseconds DESC LIMIT 5;
================================== Ai Message ==================================
Tool Calls:
sql_db_query (call_DMVALfnQ4kJsuF3Yl6jxbeAU)
Call ID: call_DMVALfnQ4kJsuF3Yl6jxbeAU
Args:
query: SELECT Genre.Name, AVG(Track.Milliseconds) AS AvgMilliseconds FROM Track JOIN Genre ON Track.GenreId = Genre.GenreId GROUP BY Genre.GenreId ORDER BY AvgMilliseconds DESC LIMIT 5;
================================= Tool Message =================================
Name: sql_db_query
[('Sci Fi & Fantasy', 2911783.0384615385), ('Science Fiction', 2625549.076923077), ('Drama', 2575283.78125), ('TV Shows', 2145041.0215053763), ('Comedy', 1585263.705882353)]
================================== Ai Message ==================================
The genre with the longest tracks on average is "Sci Fi & Fantasy," with an average track length of approximately 2,911,783 milliseconds. Other genres with relatively long tracks include "Science Fiction," "Drama," "TV Shows," and "Comedy."
有关上述运行的详细信息,请参阅 LangSmith
跟踪。
6. 实现Human in the Loop审查
在执行代理的 SQL 查询之前进行检查是谨慎的做法,以避免任何意外操作或低效。 在这里,我们利用 LangGraph 的Human in the Loop功能,在执行 SQL 查询之前暂停运行并等待人工审查。使用 LangGraph 的持久化层,我们可以无限期地暂停运行(或至少在持久化层存活期间)。 让我们将sql_db_query 工具包装在一个接收人工输入的节点中。我们可以使用 interrupt 函数来实现这一点。下面,我们允许输入以批准工具调用、编辑其参数或提供用户反馈。
import { RunnableConfig } from "@langchain/core/runnables";
import { tool } from "langchain";
import { interrupt } from "@langchain/langgraph";
import * as z from "zod";
const queryToolWithInterrupt = tool(
async (input, config: RunnableConfig) => {
const request = {
action: queryTool.name,
args: input,
description: "Please review the tool call",
};
const response = interrupt([request]);
// 批准工具调用
if (response.type === "accept") {
const toolResponse = await queryTool.invoke(input, config);
return toolResponse;
}
// 更新工具调用参数
else if (response.type === "edit") {
const editedInput = response.args.args;
const toolResponse = await queryTool.invoke(editedInput, config);
return toolResponse;
}
// 用用户反馈响应 LLM
else if (response.type === "response") {
const userFeedback = response.args;
return userFeedback;
} else {
throw new Error(`Unsupported interrupt response type: ${response.type}`);
}
},
{
name: queryTool.name,
description: queryTool.description,
schema: queryTool.schema,
},
);
上述实现遵循了更广泛的Human in the
Loop指南中的工具中断示例。有关详细信息和替代方案,请参阅该指南。
import { MemorySaver, ConditionalEdgeRouter } from "@langchain/langgraph";
const shouldContinueWithHuman: ConditionalEdgeRouter<
typeof MessagesState,
"run_query"
> = (state) => {
const messages = state.messages;
const lastMessage = messages[messages.length - 1];
if (!lastMessage.tool_calls || lastMessage.tool_calls.length === 0) {
return END;
} else {
return "run_query";
}
};
const runQueryNodeWithInterrupt = new ToolNode([queryToolWithInterrupt]);
const builderWithHuman = new StateGraph(MessagesState)
.addNode("list_tables", listTables)
.addNode("call_get_schema", callGetSchema)
.addNode("get_schema", getSchemaNode)
.addNode("generate_query", generateQuery)
.addNode("run_query", runQueryNodeWithInterrupt)
.addEdge(START, "list_tables")
.addEdge("list_tables", "call_get_schema")
.addEdge("call_get_schema", "get_schema")
.addEdge("get_schema", "generate_query")
.addConditionalEdges("generate_query", shouldContinueWithHuman)
.addEdge("run_query", "generate_query");
const checkpointer = new MemorySaver();
const agentWithHuman = builderWithHuman.compile({ checkpointer });
const config = { configurable: { thread_id: "1" } };
const question = "Which genre on average has the longest tracks?";
const stream = await agentWithHuman.stream(
{ messages: [{ role: "user", content: question }] },
{ ...config, streamMode: "values" },
);
for await (const step of stream) {
if (step.messages && step.messages.length > 0) {
const lastMessage = step.messages[step.messages.length - 1];
console.log(lastMessage.toFormattedString());
}
}
// 检查中断
const state = await agentWithHuman.getState(config);
if (state.next.length > 0) {
console.log("\nINTERRUPTED:");
console.log(JSON.stringify(state.tasks[0].interrupts[0], null, 2));
}
...
INTERRUPTED:
{
"action": "sql_db_query",
"args": {
"query": "SELECT Genre.Name, AVG(Track.Milliseconds) AS AvgLength FROM Track JOIN Genre ON Track.GenreId = Genre.GenreId GROUP BY Genre.Name ORDER BY AvgLength DESC LIMIT 5;"
},
"description": "Please review the tool call"
}
import { Command } from "@langchain/langgraph";
const resumeStream = await agentWithHuman.stream(
new Command({ resume: { type: "accept" } }),
// new Command({ resume: { type: "edit", args: { query: "..." } } }),
{ ...config, streamMode: "values" },
);
for await (const step of resumeStream) {
if (step.messages && step.messages.length > 0) {
const lastMessage = step.messages[step.messages.length - 1];
console.log(lastMessage.toFormattedString());
}
}
================================== Ai Message ==================================
Tool Calls:
sql_db_query (call_t4yXkD6shwdTPuelXEmY3sAY)
Call ID: call_t4yXkD6shwdTPuelXEmY3sAY
Args:
query: SELECT Genre.Name, AVG(Track.Milliseconds) AS AvgLength FROM Track JOIN Genre ON Track.GenreId = Genre.GenreId GROUP BY Genre.Name ORDER BY AvgLength DESC LIMIT 5;
================================= Tool Message =================================
Name: sql_db_query
[('Sci Fi & Fantasy', 2911783.0384615385), ('Science Fiction', 2625549.076923077), ('Drama', 2575283.78125), ('TV Shows', 2145041.0215053763), ('Comedy', 1585263.705882353)]
================================== Ai Message ==================================
The genre with the longest average track length is "Sci Fi & Fantasy" with an average length of about 2,911,783 milliseconds. Other genres with long average track lengths include "Science Fiction," "Drama," "TV Shows," and "Comedy."
后续步骤
查看评估图指南,了解如何使用 LangSmith 评估 LangGraph 应用程序,包括像这样的 SQL 代理。将这些文档连接到 Claude、VSCode 等,通过 MCP
获取实时答案。