

当在线评估器在跟踪中的任何运行上运行时,该跟踪将自动升级为扩展数据保留。此升级会影响跟踪定价,但确保符合您评估标准(通常是对分析最有价值的)的跟踪被保留以供调查。
查看在线评估器
导航到跟踪页面并选择一个跟踪项目。要查看该项目的现有在线评估器,请点击评估器选项卡。
配置在线评估器
1. 导航到在线评估器
导航到跟踪页面并选择一个跟踪项目。点击评估器选项卡,然后点击 + 评估器以打开添加评估器面板。在从头开始创建下选择代码评估器以构建新的评估器,或在附加现有评估器下从您的工作区中选择现有的代码评估器。2. 为评估器命名
为您的评估器提供一个名称。此名称将在代码中引用评估器时使用,也将是此评估器生成的反馈的名称。3. 创建过滤器
例如,您可能希望基于以下条件应用特定的评估器:- 运行中用户留下了反馈,表示响应不令人满意。
- 调用特定工具调用的运行。有关更多信息,请参阅过滤工具调用。
- 匹配特定元数据的运行(例如,如果您记录带有
plan_type的跟踪,并且只想对来自企业客户的跟踪运行评估)。有关更多信息,请参阅向跟踪添加元数据。
4. (可选)配置采样率
配置采样率以控制触发自动化操作的已过滤运行的百分比。例如,为了控制成本,您可能希望设置一个过滤器,仅将评估器应用于 10% 的跟踪。为此,您需要将采样率设置为 0.1。5. (可选)将规则应用于过去的运行
通过切换应用于过去的运行并输入“回填起始日期”将规则应用于过去的运行。这仅在创建规则时可能。注意:回填作为后台作业处理,因此您不会立即看到结果。 为了跟踪回填进度,您可以通过导航到跟踪项目中的评估器选项卡并点击您创建的评估器的日志按钮来查看评估器的日志。在线评估器日志类似于自动化规则日志。- 添加评估器名称
- 可选地过滤您希望应用评估器的运行或配置采样率。
- 选择应用评估器
编写您的评估函数
代码评估器限制。允许的库:您可以导入所有标准库函数,以及以下公共包:网络访问:您无法从代码评估器访问互联网。
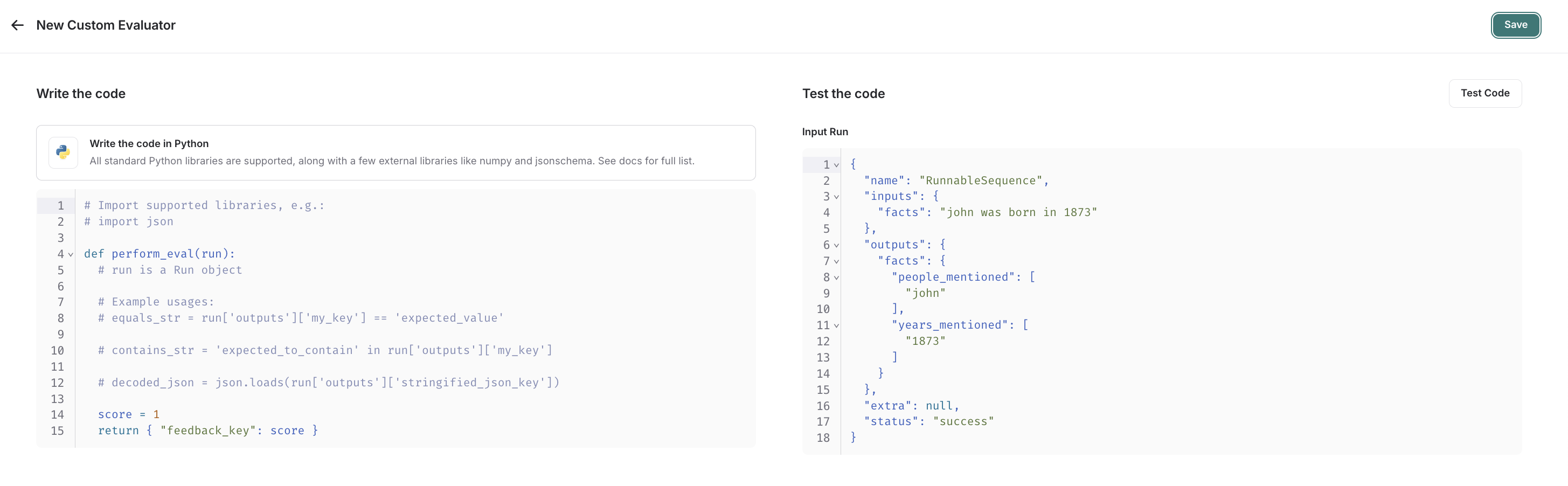
- 一个
Run(参考)。这代表要评估的采样运行。
- 反馈字典:一个字典,其键是您要返回的反馈类型,值是您将为该反馈键给出的分数。例如,
{"correctness": 1, "silliness": 0}将在运行上创建两种类型的反馈,一种表示它是正确的,另一种表示它不愚蠢。
测试并保存您的评估函数
在保存之前,您可以通过点击测试代码在最近的运行上测试您的评估器函数,以确保您的代码正确执行。 一旦您保存,您的在线评估器将在新采样的运行(或者如果您选择了回填选项,也包括回填的运行)上运行。 如果您更喜欢视频教程,请查看 LangSmith 课程介绍中的在线评估视频。将这些文档通过 MCP 连接到 Claude、VSCode 等,以获取实时答案。