

在开始阅读本页之前,以下内容可能有所帮助:
工作原理
LangSmith的对齐评估器功能包含一系列步骤,帮助您将LLM作为评判者的评估器与人类专家反馈对齐。您可以使用此功能来对齐在数据集上运行的评估器,用于离线评估或在线评估。无论哪种情况,步骤都相似:- 选择实验或运行,其中包含来自您应用的输出。
- 将选定的实验或运行添加到标注队列,人类专家可以在其中对数据进行标注。
- 针对标注的示例测试您的LLM作为评判者的评估器提示词。检查评估器结果与标注数据不一致的情况。这表明您的评估器提示词需要改进的领域。
- 精炼并重复以提高评估器对齐度。更新您的LLM作为评判者的评估器提示词并再次测试。
先决条件
在开始本指南的离线评估或在线评估之前,您需要以下内容:离线评估
在线评估
- 一个已经向LangSmith发送跟踪信息的应用程序。
- 使用其中一种跟踪集成进行配置以开始。
入门指南
您可以在数据集和跟踪项目中为新的和现有的评估器进入对齐流程。1. 选择实验或运行
选择一个或多个实验(或运行)发送进行人工标注。这将把运行添加到标注队列。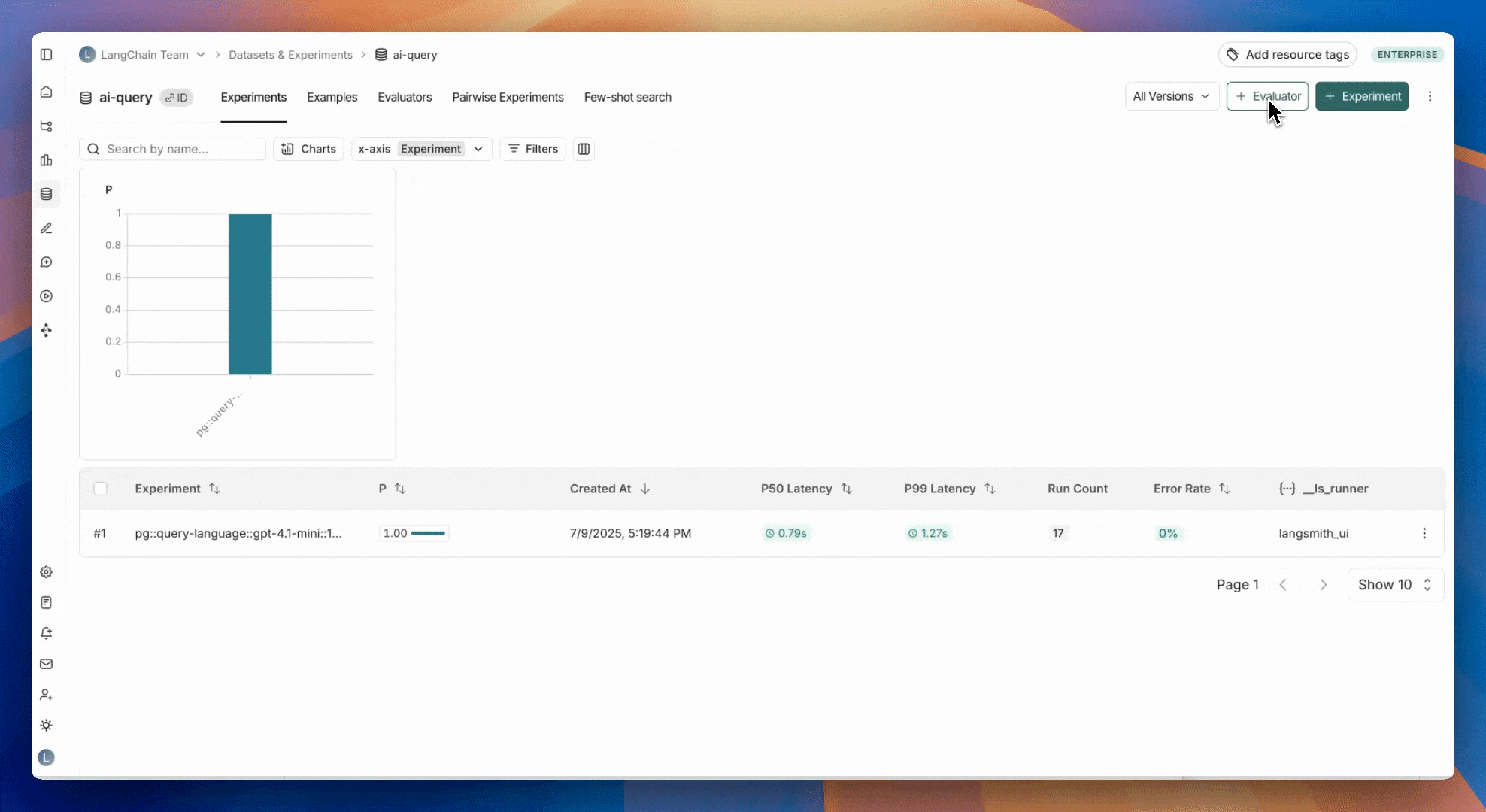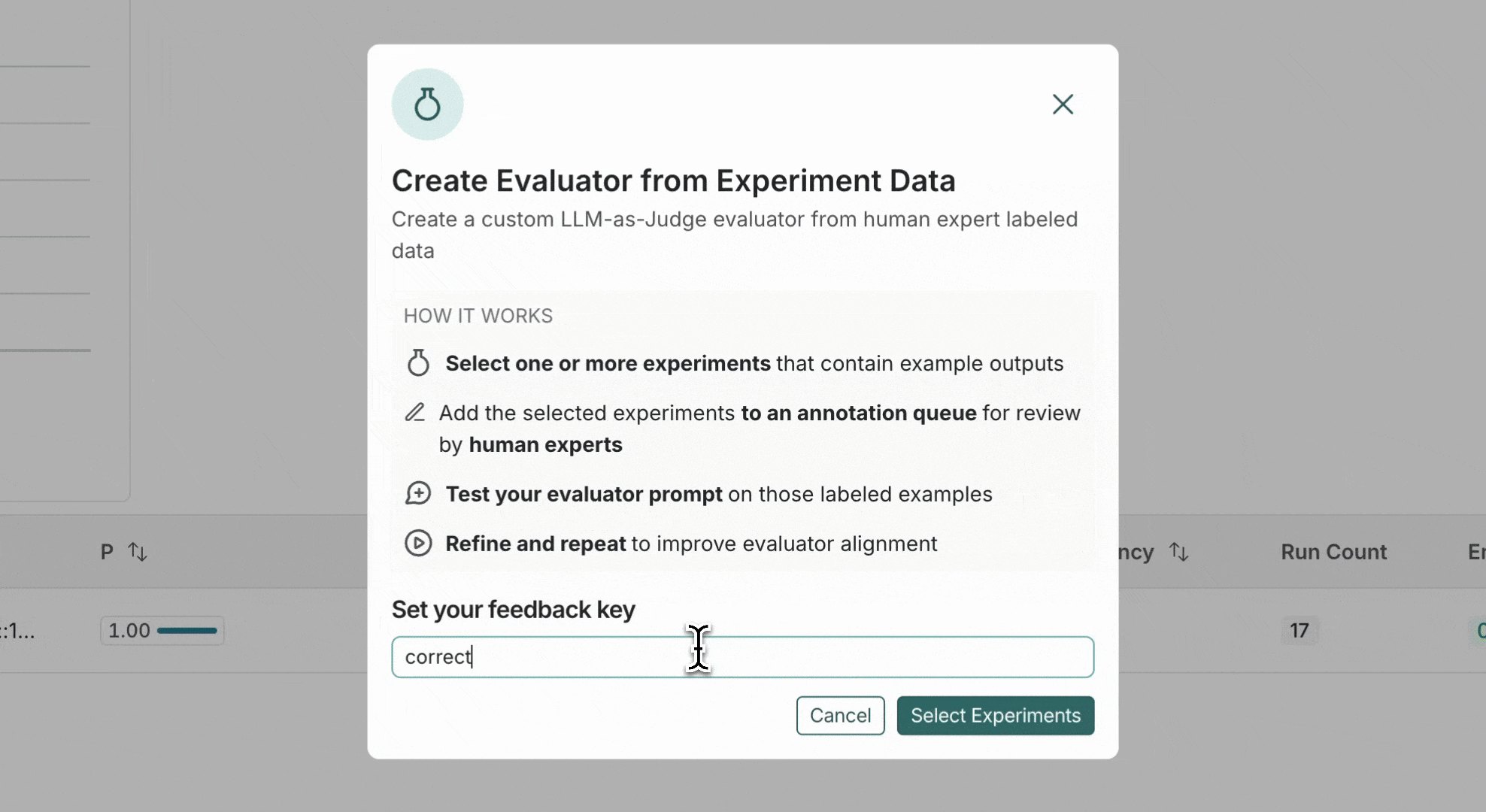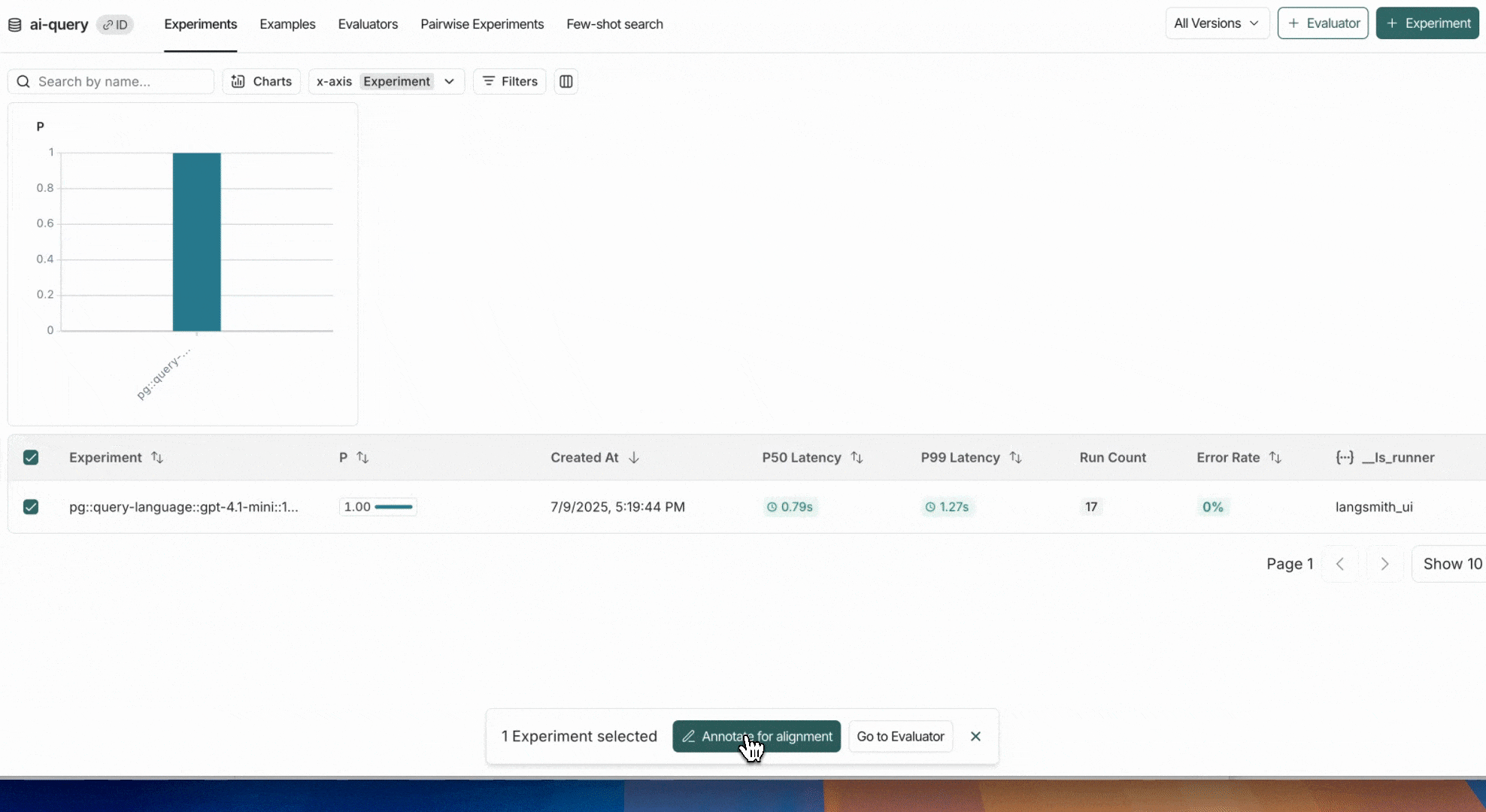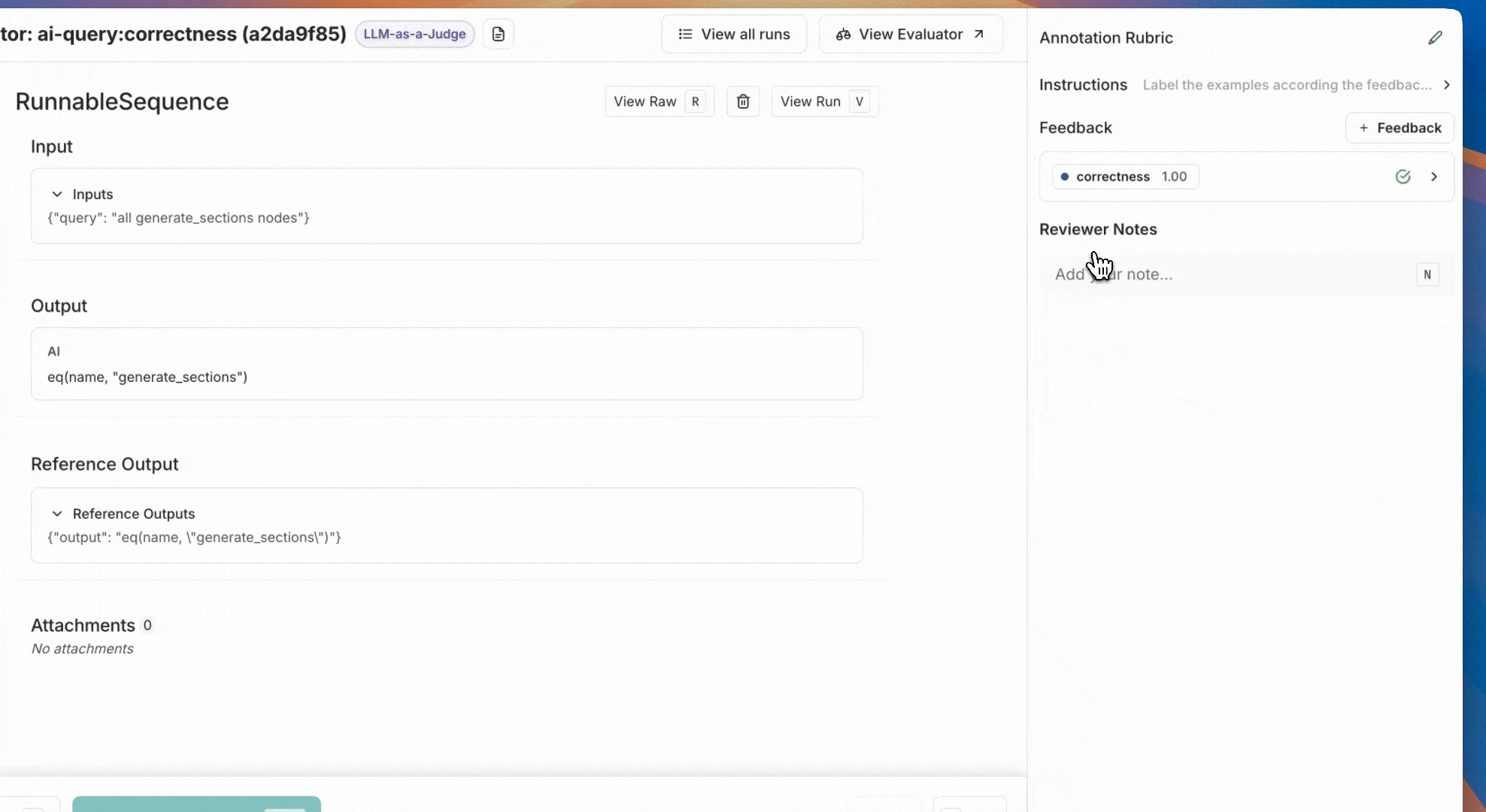
数据集应能代表您在生产环境中预期看到的输入和输出。虽然您不需要涵盖每一种可能的场景,但重要的是要包含预期用例范围内的示例。例如,如果您正在构建一个回答关于棒球、篮球和足球问题的体育机器人,您的数据集应至少包含来自每项运动的一个标注示例。
2. 标注示例
通过添加反馈分数来标注标注队列中的示例。标注完一个示例后,点击添加到参考数据集。如果您的实验中有大量示例,您不需要标注每个示例就可以开始。我们建议从至少20个示例开始,您随时可以稍后添加更多。我们建议您标注的示例具有多样性(在0和1标签之间保持平衡),以确保您正在构建一个全面的评估器提示词。
3. 针对标注的示例测试您的评估器提示词
一旦您有了标注的示例,下一步就是迭代您的评估器提示词,使其尽可能好地模仿标注数据。此迭代在评估器Playground中完成。 要进入评估器Playground:点击评估器队列右上角的查看评估器按钮。这将带您进入您正在对齐的评估器的详细信息页面。点击评估器Playground按钮以访问Playground。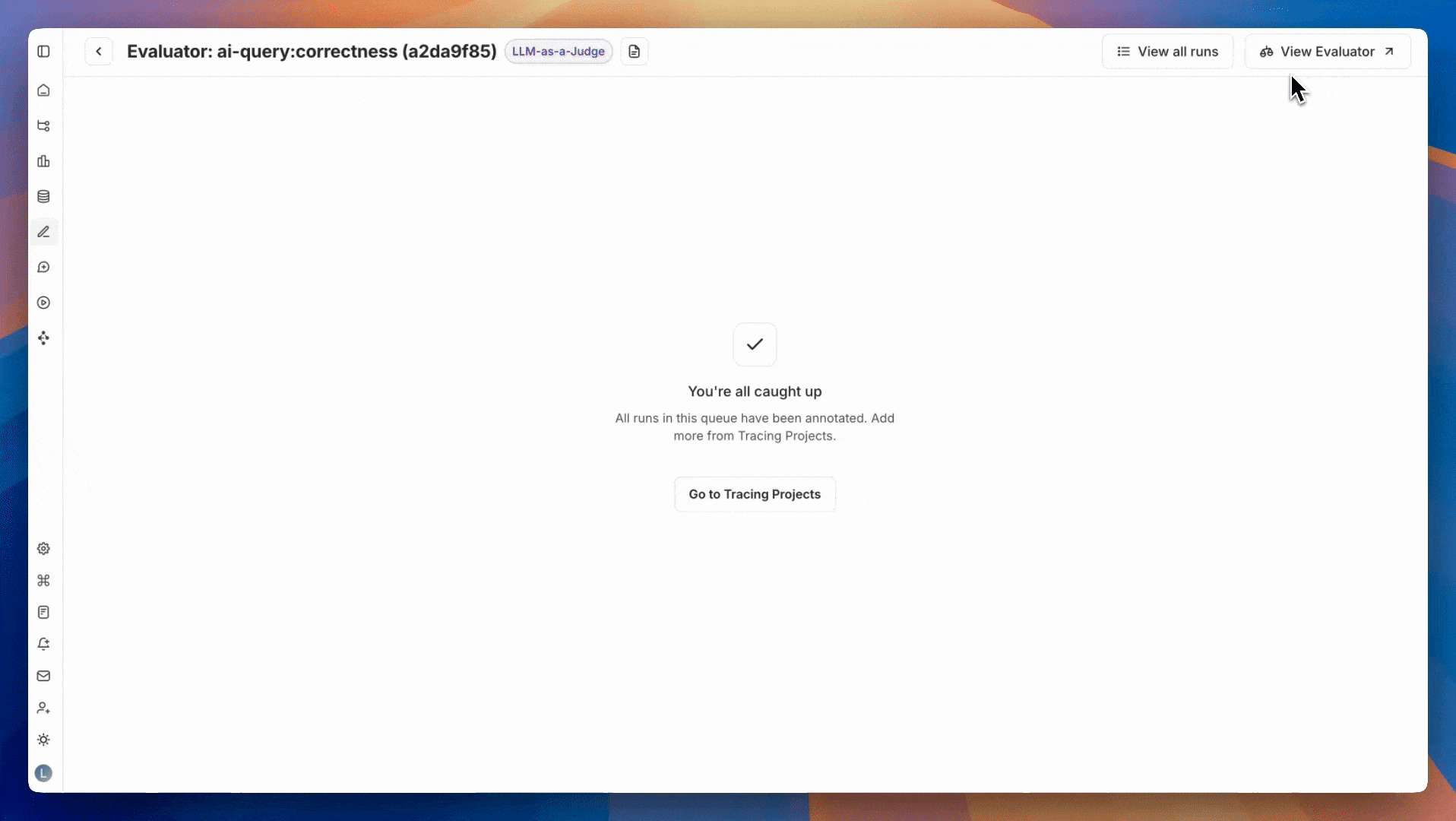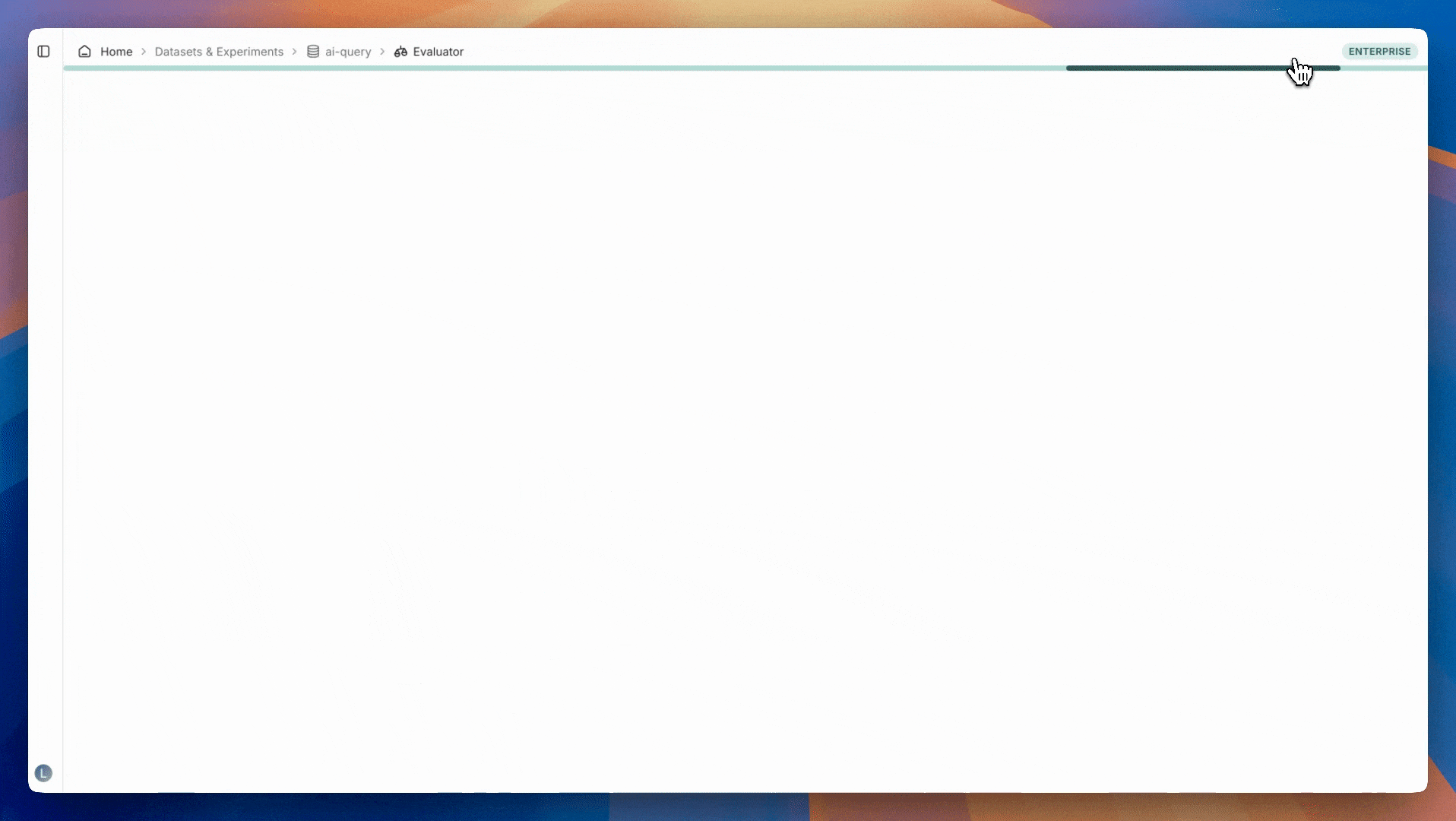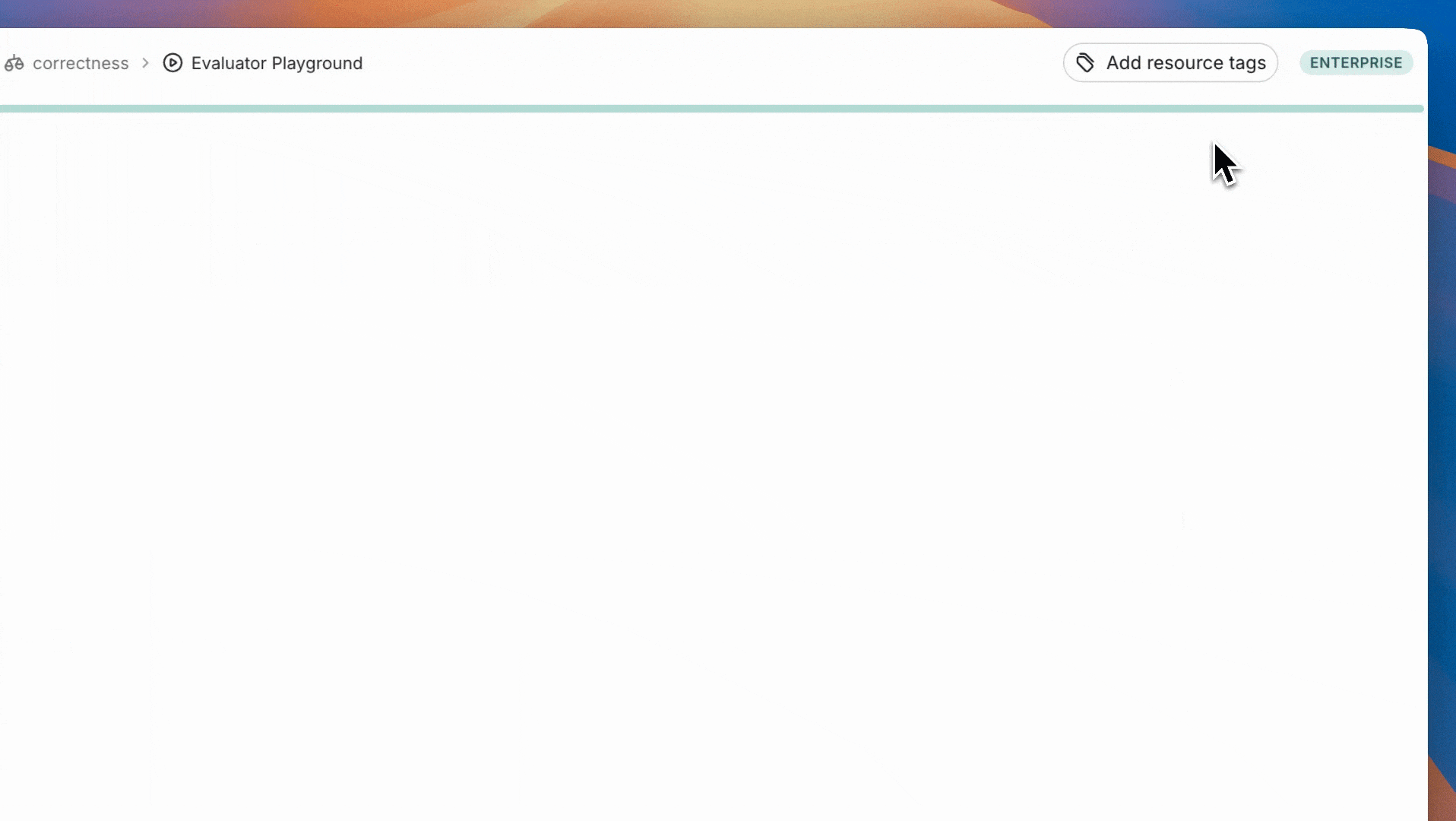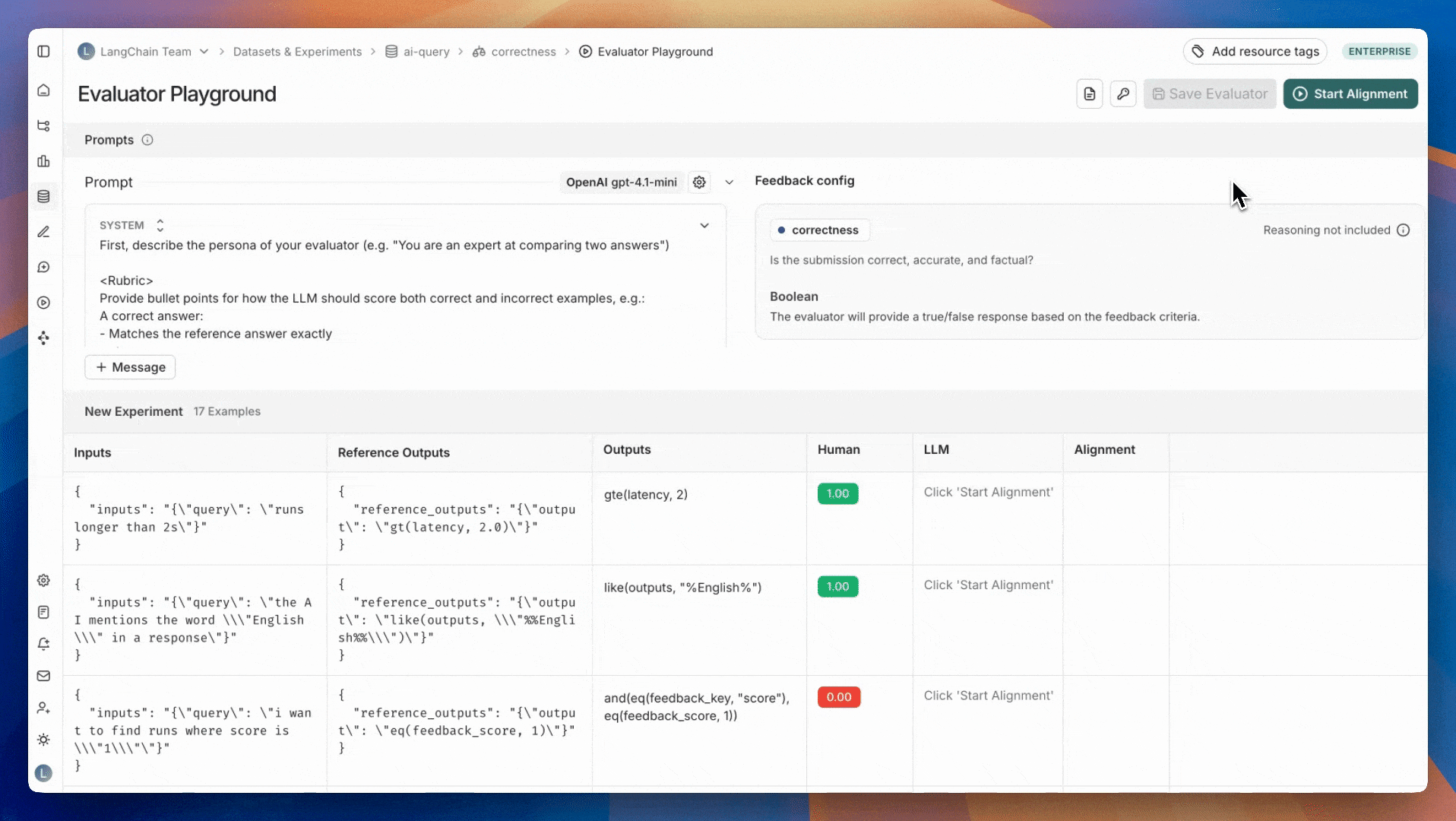
4. 重复以提高评估器对齐度
通过更新提示词并再次测试来迭代,以提高评估器对齐度。对评估器提示词的更新默认不会保存。我们建议您定期保存评估器提示词,尤其是在看到对齐分数提高之后。当您迭代提示词时,评估器Playground将显示您评估器提示词最近保存版本的对齐分数以供比较。
提高评估器对齐度的技巧
1. 调查不一致的示例 深入研究不一致的示例,并尝试将它们归类为常见的失败模式,这是提高评估器对齐度的一个很好的第一步。 一旦您识别出常见的失败模式,请在评估器提示词中添加说明,以便LLM了解它们。例如,如果您注意到它不理解特定的缩写,您可以解释“MFA代表‘多因素认证’”。或者,如果它对评估器上下文中什么是好/坏感到困惑,您可以告诉它“一个好的回复总是包含至少3个潜在的预订酒店”。 2. 检查LLM分数背后的推理 要理解LLM为何对某个示例给出那样的评分,您可以为LLM作为评判者的评估器启用推理功能。推理有助于理解LLM的思维过程,并可以帮助您识别常见的失败模式,以便将其纳入评估器提示词。 为了在评估器Playground中查看推理,请将鼠标悬停在LLM分数上。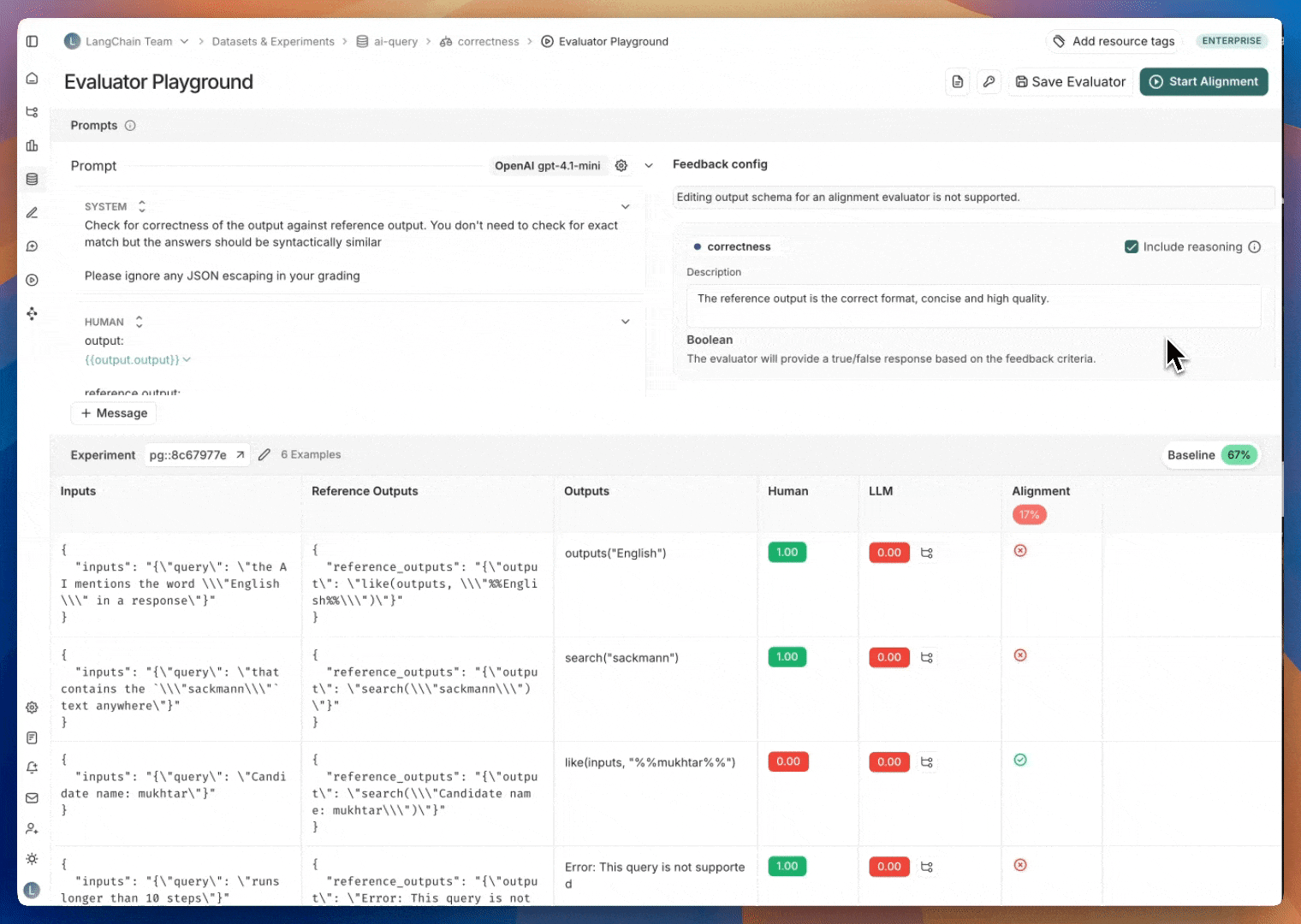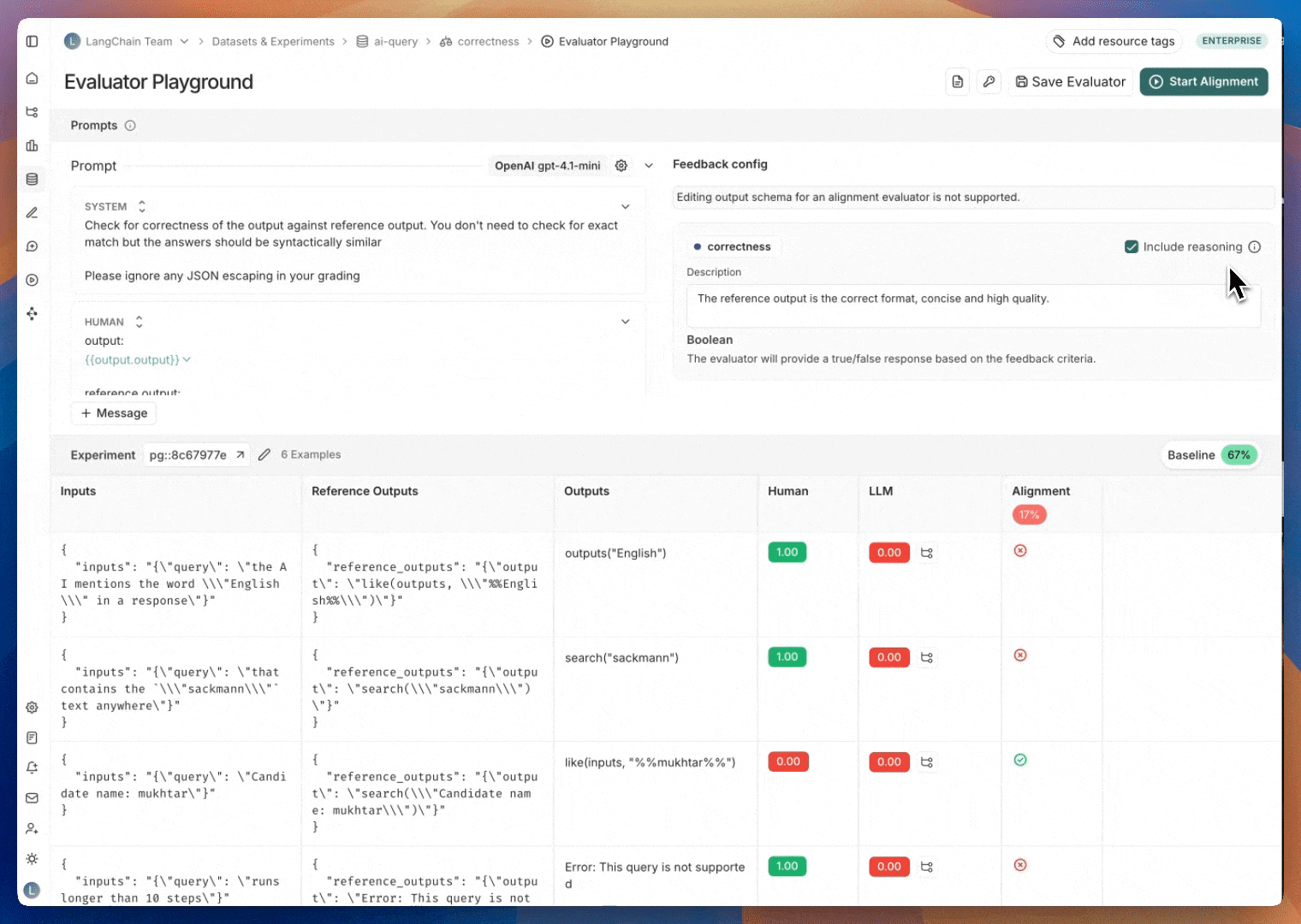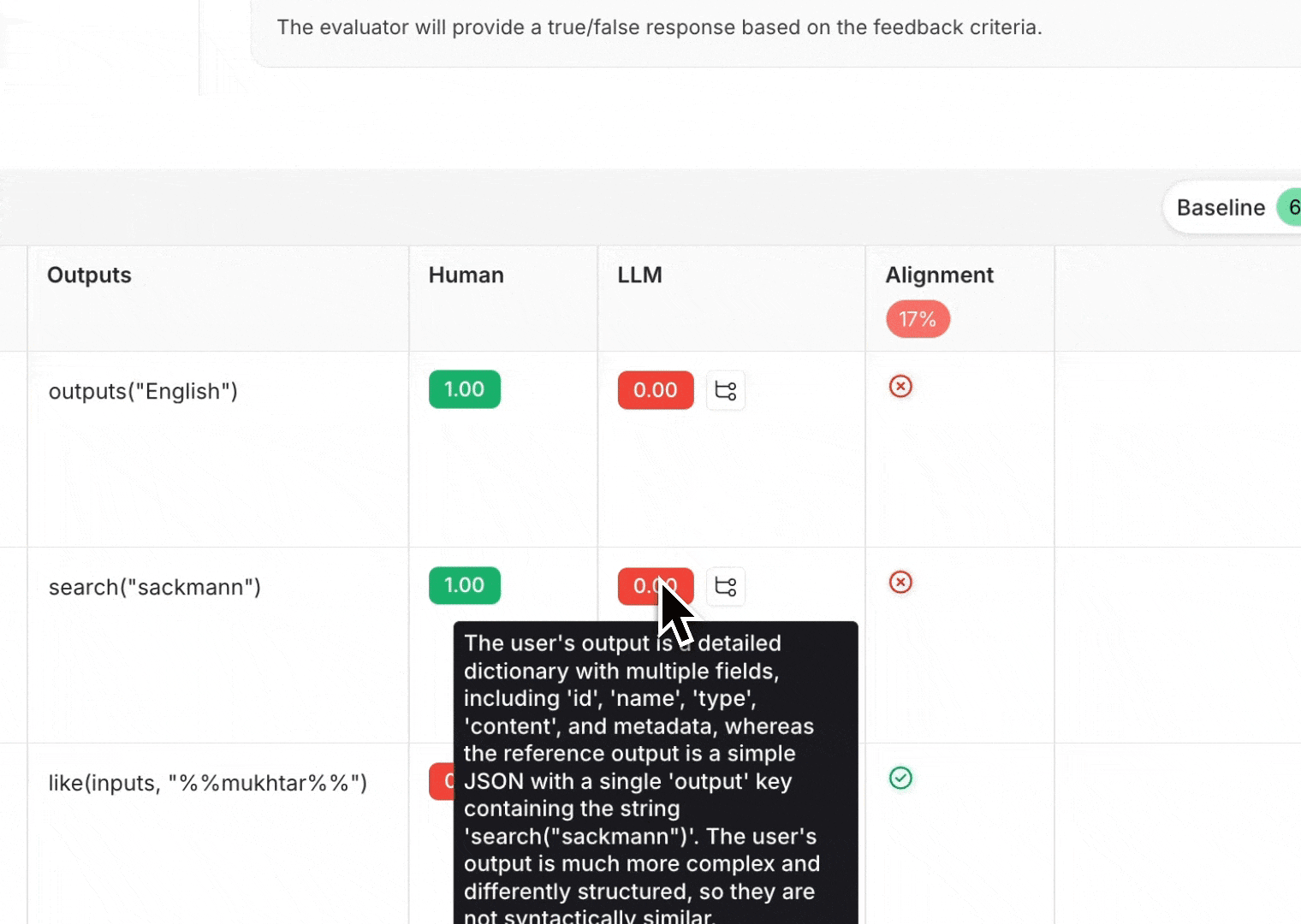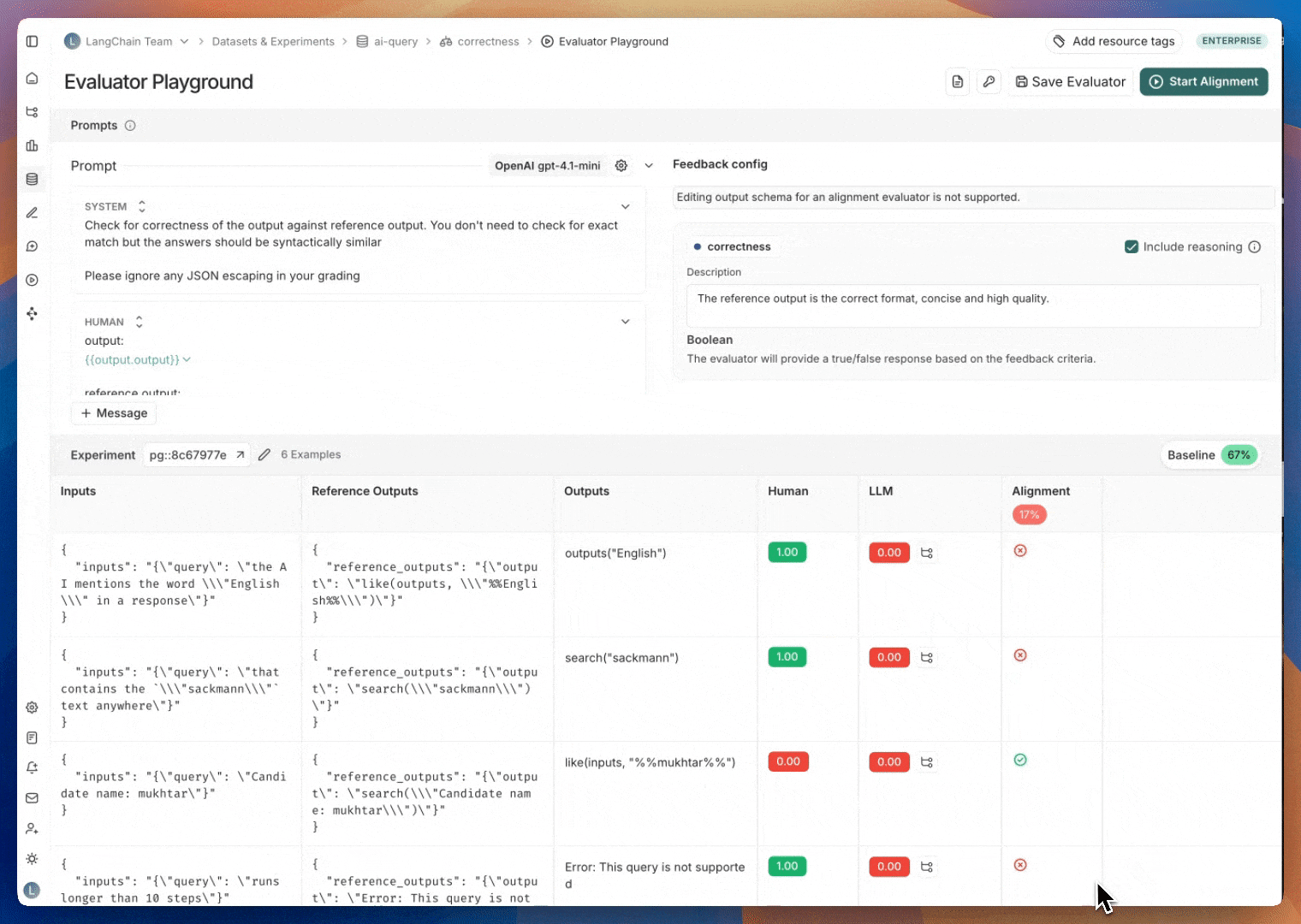
视频指南
通过MCP将这些文档连接到Claude、VSCode等,以获取实时答案。