

概述
代理使用来自内存和执行环境的信息来完成任务。 在生产环境中,有几个基本要素决定了信息的共享和访问方式:- 线程:单次对话。消息历史记录和临时文件默认限定在线程范围内,不会跨线程传递。
- 用户:与您的代理交互的人。内存和文件可以对用户私有,也可以跨用户共享。身份和授权来自您的认证层。
- 助理:一个配置好的代理实例。内存和文件可以绑定到一个助理,也可以在所有助理间共享。
- LangSmith 部署:带有认证、Webhook 和定时任务的托管基础设施
- 生产注意事项:多租户、认证、凭据、异步和持久性
- 内存:跨对话持久化信息
- 执行环境:文件存储和代码执行
- 防护栏:速率限制、错误处理和数据隐私
- 前端:将您的 UI 连接到已部署的代理
LangSmith 部署

deepagents deploy,它打包您的代理配置,并通过一条命令将其部署为 LangSmith 部署。或者,您可以直接配置 LangSmith 部署。无论哪种方式,都会配置您的代理所需的基础设施:助理、线程、运行、存储和检查点,因此您无需自行设置。它还提供开箱即用的认证、Webhook、定时任务和可观测性,并且可以通过 MCP 或 A2A 暴露您的代理。
有关基于 CLI 的方法,请参阅使用 CLI 部署。有关手动设置,请参阅 LangSmith 部署快速入门。
除非另有说明,本页上的所有代码片段均使用以下 langgraph.json:
langgraph.json
langgraph.json 是告诉 LangGraph 平台如何构建和运行您的应用程序的配置文件。它位于项目根目录,对于本地开发(使用 langgraph dev)和生产部署都是必需的。关键字段如下:
有关完整的配置选项集(自定义 Docker 步骤、存储索引、认证处理程序等),请参阅应用结构。
生产注意事项
多租户
当您的代理服务于多个用户时,您需要处理三个问题:验证每个用户的身份、控制他们可以访问的内容,以及管理代理代表他们操作时使用的凭据。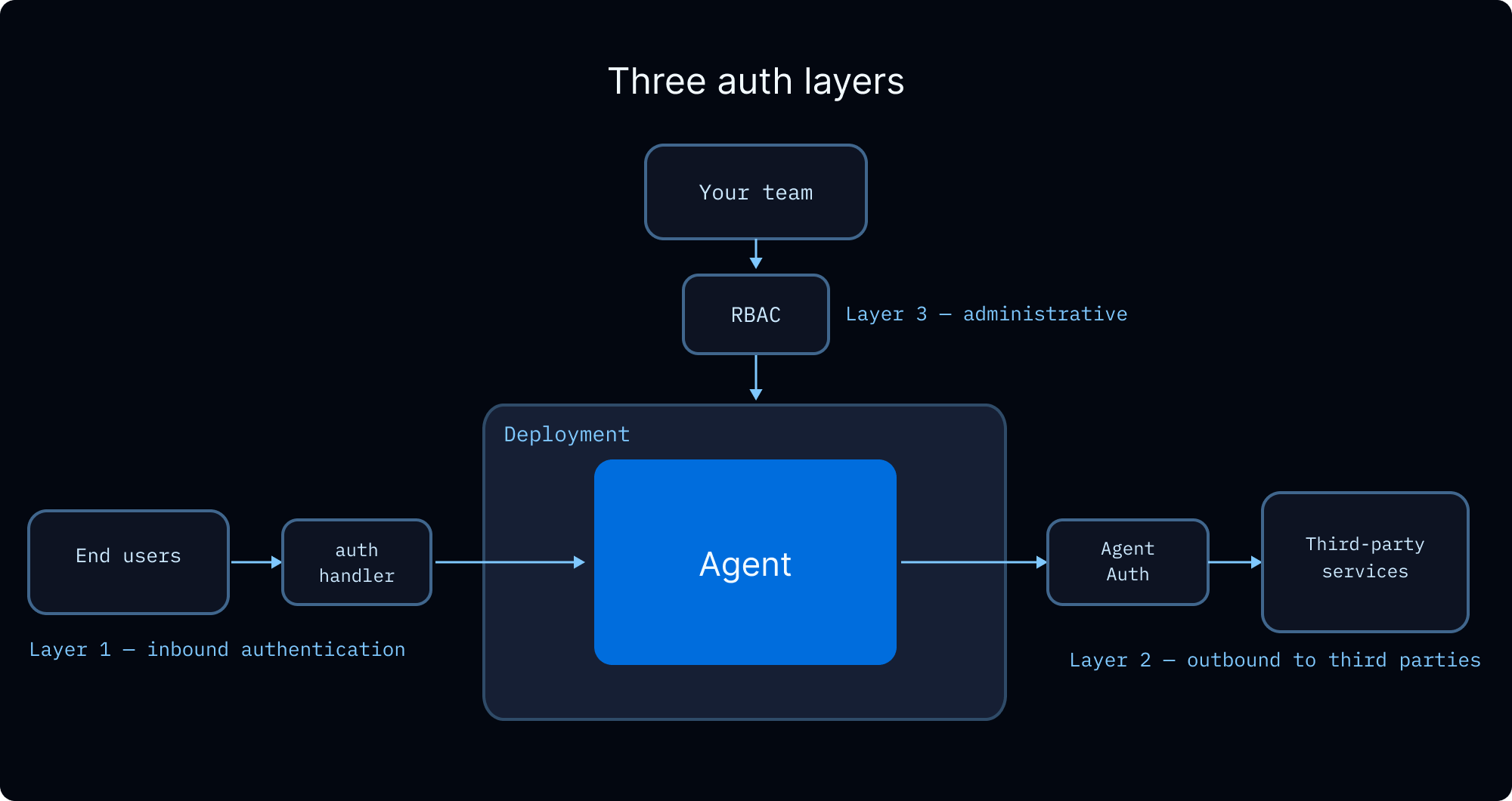
用户身份和访问控制
LangSmith 部署支持自定义认证以建立用户身份,以及授权处理程序来控制对线程、助理和存储命名空间等资源的访问。授权处理程序在认证成功后运行,可以:- 使用所有权元数据标记资源(例如,
owner: user_id) - 返回过滤器,以便用户只能看到自己的资源
- 对未授权操作返回 HTTP 403 拒绝访问
团队访问控制 (RBAC)
LangSmith 的基于角色的访问控制管理您团队中谁可以部署、配置和监控代理。这与上述最终用户授权是分开的。
企业版计划提供具有细粒度权限的自定义角色。有关完整的权限模型,请参阅 RBAC 参考。
最终用户凭据
当您的代理需要代表用户调用外部 API(例如,读取他们的 GitHub 仓库、发送 Slack 消息、查询他们的数据仓库)时,您需要一种方式将用户的凭据传递给代理,而无需硬编码它们。 通过代理认证的 OAuth。 代理认证提供托管的 OAuth 2.0 流程。配置一个 OAuth 提供程序,代理就可以请求限定于每个用户的令牌。首次使用时,代理会中断执行并呈现一个 OAuth 同意 URL。用户认证后,代理使用有效的令牌恢复执行。令牌会自动存储和刷新。异步
基于 LLM 的应用程序是 I/O 密集型的:调用语言模型、数据库和外部服务。异步编程允许这些操作并发运行而不是阻塞,从而提高吞吐量和响应能力。LangChain 遵循在异步方法名前加
a
前缀的约定(例如,ainvoke、abefore_agent、astream)。同步和异步变体位于同一个类或命名空间中。- 创建异步工具。 LangChain 在单独的线程中运行同步工具以避免阻塞,但原生异步完全避免了线程开销。
- 使用异步中间件方法。 自定义中间件应实现异步钩子(例如,
abefore_agent而不是before_agent)。 - 对外部资源生命周期使用异步。 创建沙箱或连接 MCP 服务器涉及网络调用,应使用 await。这就是为什么配置这些资源的图工厂是异步的。
持久性
深度代理运行在 LangGraph 上,它开箱即用地提供持久执行。持久化层在每个步骤检查点状态,因此因故障、超时或Human in the Loop暂停而中断的运行会从其最后记录的状态恢复,而无需重新处理之前的步骤。对于生成许多子代理的长时间运行的深度代理,这意味着运行中的失败不会丢失已完成的工作。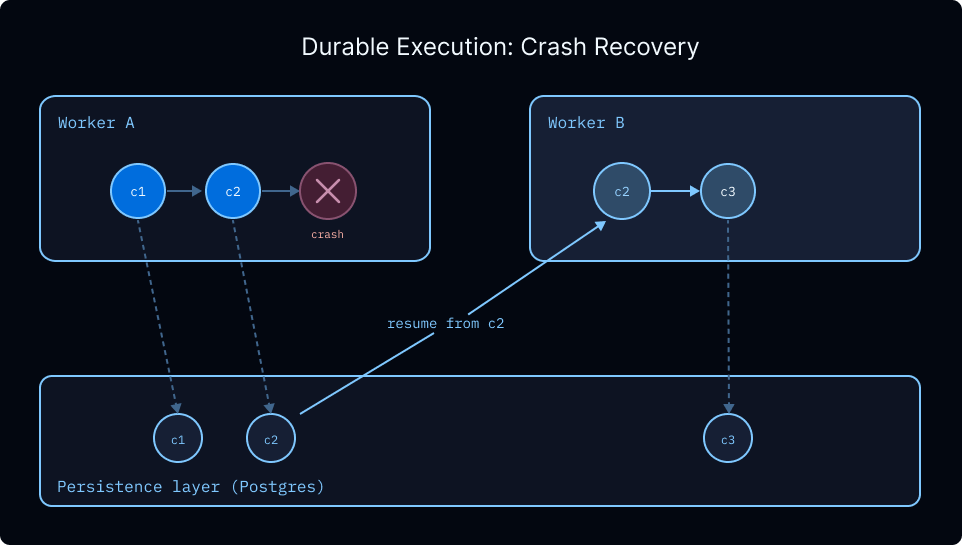
- 无限期中断。 Human in the Loop的工作流可以暂停数分钟或数天,并准确地从上次中断的地方恢复。
- 时间旅行。 每个检查点步骤都是一个可以回退到的快照,如果出现问题,您可以从较早的状态重放。
- 安全处理敏感操作。 对于涉及支付或其他不可逆操作的工作流,检查点提供审计跟踪和恢复点,以检查导致操作的确切状态。
内存
没有内存,每次对话都从头开始。内存让您的代理能够跨对话保留信息(用户偏好、学习到的指令、过去的经验),从而能够随着时间的推移个性化其行为。有关内存类型的概述,请参阅内存概念指南。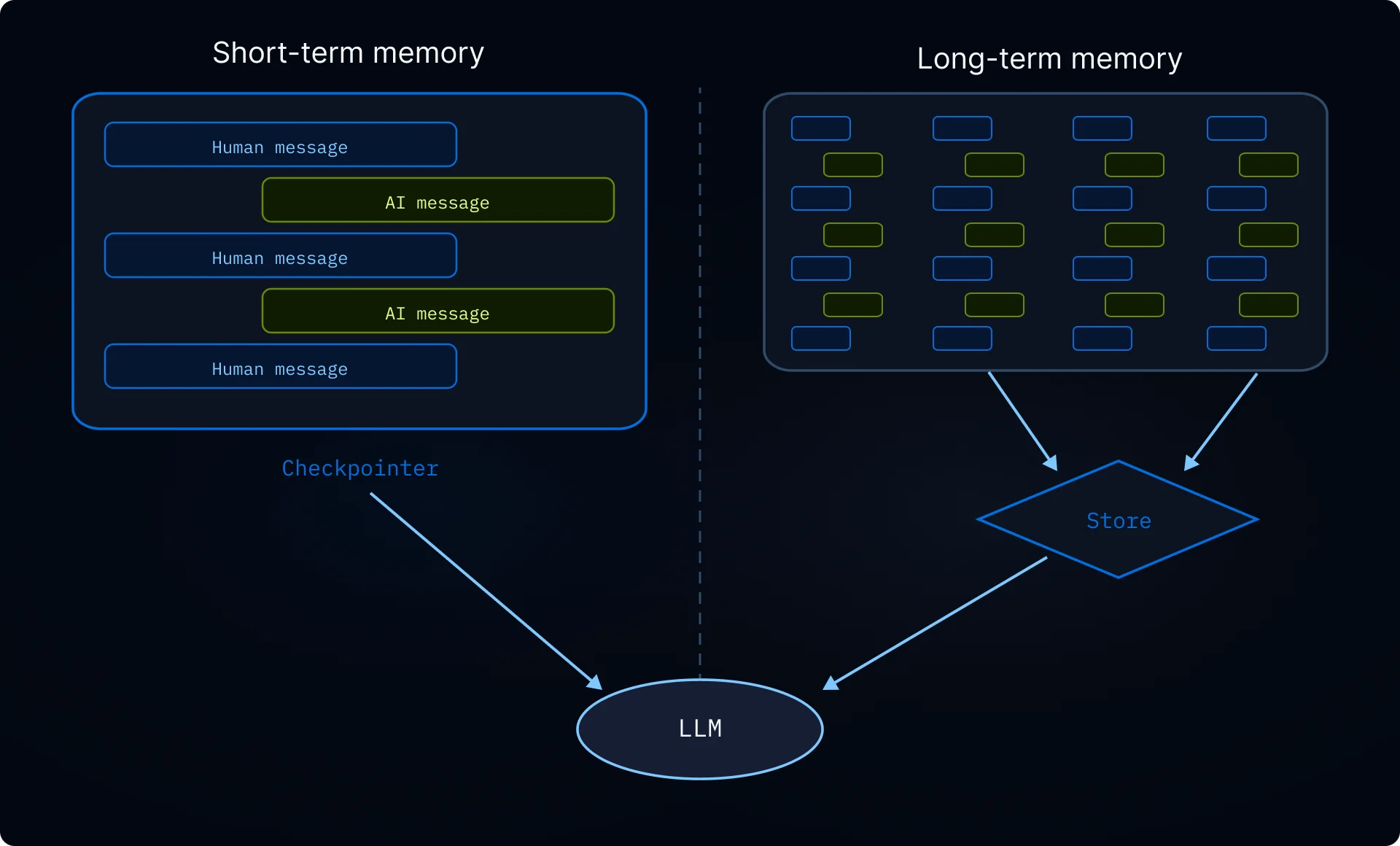
范围界定
内存始终跨对话持久化。主要问题是如何在用户和助理边界之间界定其范围。正确的范围取决于谁应该查看和修改数据:配置
在深度代理中,内存以文件形式存储在虚拟文件系统中。默认情况下,文件仅持续一次对话。要持久化它们,请将类似/memories/ 的路径路由到写入 LangGraph Store 的 StoreBackend。使用 CompositeBackend 为代理提供临时暂存空间和持久化的长期内存。
下面显示的
rt.serverInfo 和 rt.executionInfo 命名空间模式需要 deepagents>=1.9.0。- 用户(推荐)
- 助理
- 用户
- 组织
按
user_id 命名空间。每个用户获得自己的私有内存。这是推荐的默认设置,因为大多数应用程序部署单个助理。src/agent.ts
执行环境
在本地,代理可以直接读写磁盘上的文件并运行 shell 命令。在生产环境中,您需要考虑隔离性和持久性。正确的设置取决于您的代理是否需要执行代码:- 文件系统后端:如果您的代理只读写文件,这就足够了。选择符合您持久性需求的后端:临时暂存空间、持久化存储,或两者的混合。
- 沙箱:添加一个带有
execute工具的隔离容器,用于运行 shell 命令。如果您的代理需要运行代码、安装包或执行文件 I/O 以外的任何操作,请使用沙箱。
文件系统
根据需要持久化的内容选择后端:- StateBackend(默认):临时暂存空间,限定在单个对话范围内。在每个步骤检查点,因此避免写入大文件。
- StoreBackend:跨对话持久化的存储。使用命名空间工厂界定范围。
- CompositeBackend:混合两者。默认为临时暂存空间,为特定路径(如
/memories/)提供持久化路由。
沙箱
如果您的代理需要运行代码(而不仅仅是读写文件),请使用沙箱。沙箱提供文件系统和用于运行 shell 命令的execute 工具,所有这些都在隔离的容器内。这种隔离也保护了您的主机:如果代理的代码耗尽内存或崩溃,只有沙箱会受到影响。您的服务器继续运行。
生命周期
关键决策是沙箱存活多久。每次对话是获得一个新的沙箱,还是对话共享一个持久化的环境?下面的示例使用异步图工厂而不是静态图,因为沙箱需要
thread_id 或 assistant_id 来查找或创建正确的沙箱。图工厂不接收完整的
Runtime(没有 server_info 或 execution_info);而是接受 RunnableConfig
并从 config["configurable"] 读取 thread_id 和
assistant_id。工厂是异步的,因为沙箱创建是 I/O
密集型操作,需要仅在调用时可用的每次运行信息。- 线程范围(最常见)
- 助理范围
agent 变量是一个异步函数(而不是已编译的图),服务器将其视为图工厂,并在每次运行时调用它,注入配置。工厂通过提供商的基于标签的搜索查找或创建沙箱,并返回一个连接到该沙箱的新代理图。
使用 langgraph deploy 部署后,使用 SDK 从应用程序代码调用代理。无论范围如何,客户端代码都是相同的。范围完全在上面的代理工厂中处理,但行为有所不同:
- 线程范围
- 助理范围
每个线程获得自己的沙箱。同一线程内的后续消息重用相同的沙箱,但新线程总是从干净状态开始,没有来自先前对话的遗留文件或安装的包。
client.ts
文件传输
沙箱是隔离的容器,因此您的应用程序代码无法直接访问其中的文件。使用upload_files() 和 download_files() 在沙箱边界移动数据:
有关特定于提供商的文件传输示例,请参阅处理文件。有关提供商设置、安全性和生命周期模式,请参阅完整的沙箱指南。
示例:使用自定义中间件同步技能和内存
示例:使用自定义中间件同步技能和内存
管理密钥
沙箱是隔离的容器,因此来自主机的环境变量在沙箱内不可用。有两种方式向沙箱代码提供 API 密钥和其他密钥: 认证代理(推荐)。 沙箱认证代理拦截来自沙箱的出站请求,并自动注入认证头。沙箱代码正常调用外部 API,代理根据目标主机添加正确的凭据。这意味着 API 密钥永远不会出现在沙箱代码、环境变量或日志中。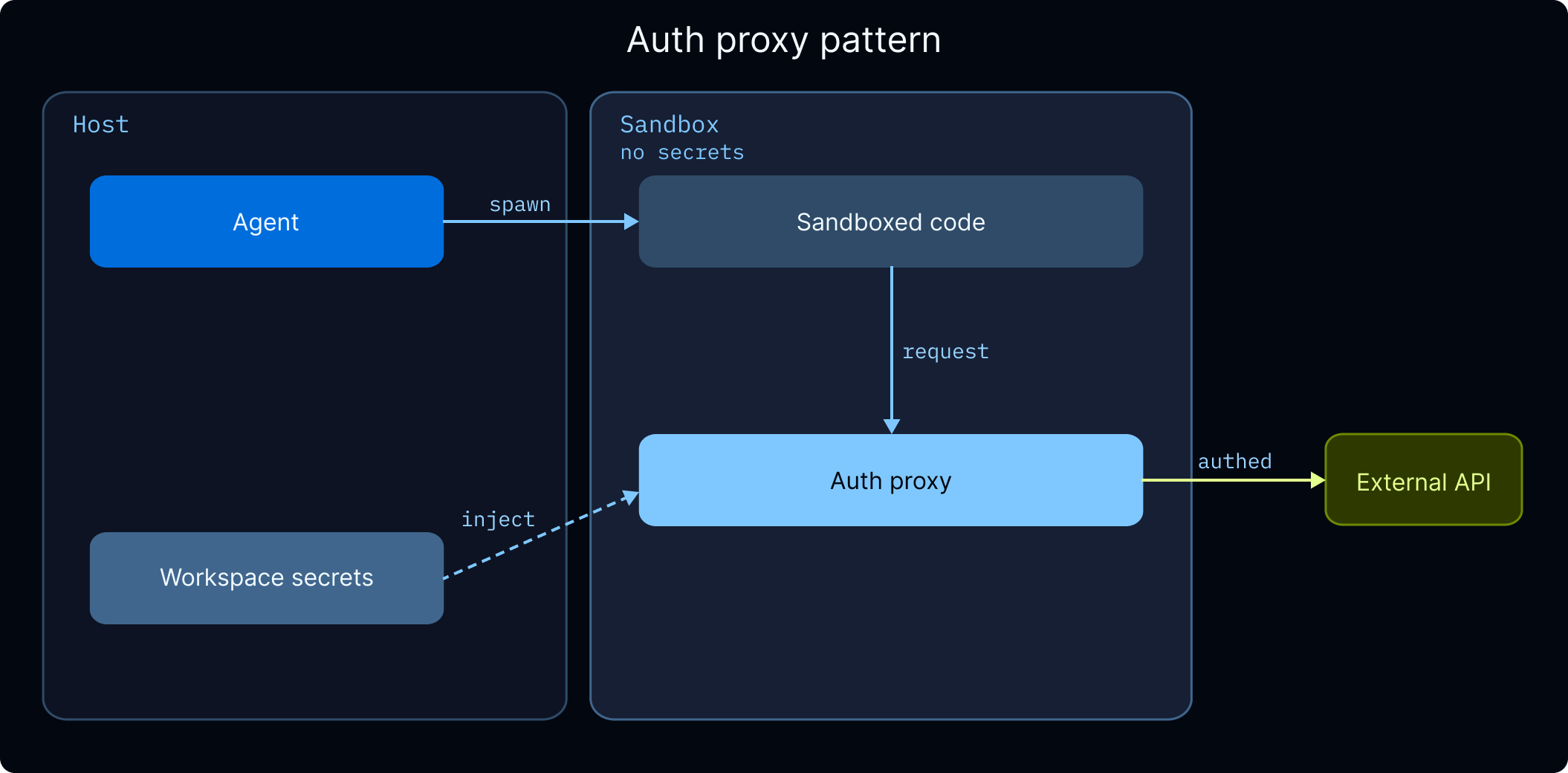
${SECRET_KEY} 引用根据存储在您 LangSmith 工作区设置中的密钥进行解析。在创建引用它们的模板之前,请在那里配置密钥。
工作区密钥。 对于不需要基于代理注入的 API 密钥(例如,代理服务器本身使用的密钥,而不是沙箱代码),请将它们存储为 LangSmith 中的工作区密钥。这些在运行时作为环境变量可供工作区中的所有代理使用。
防护栏
生产环境中的代理自主运行,这意味着它们可能无限循环、达到速率限制或处理包含敏感信息的用户数据。深度代理提供两层保护: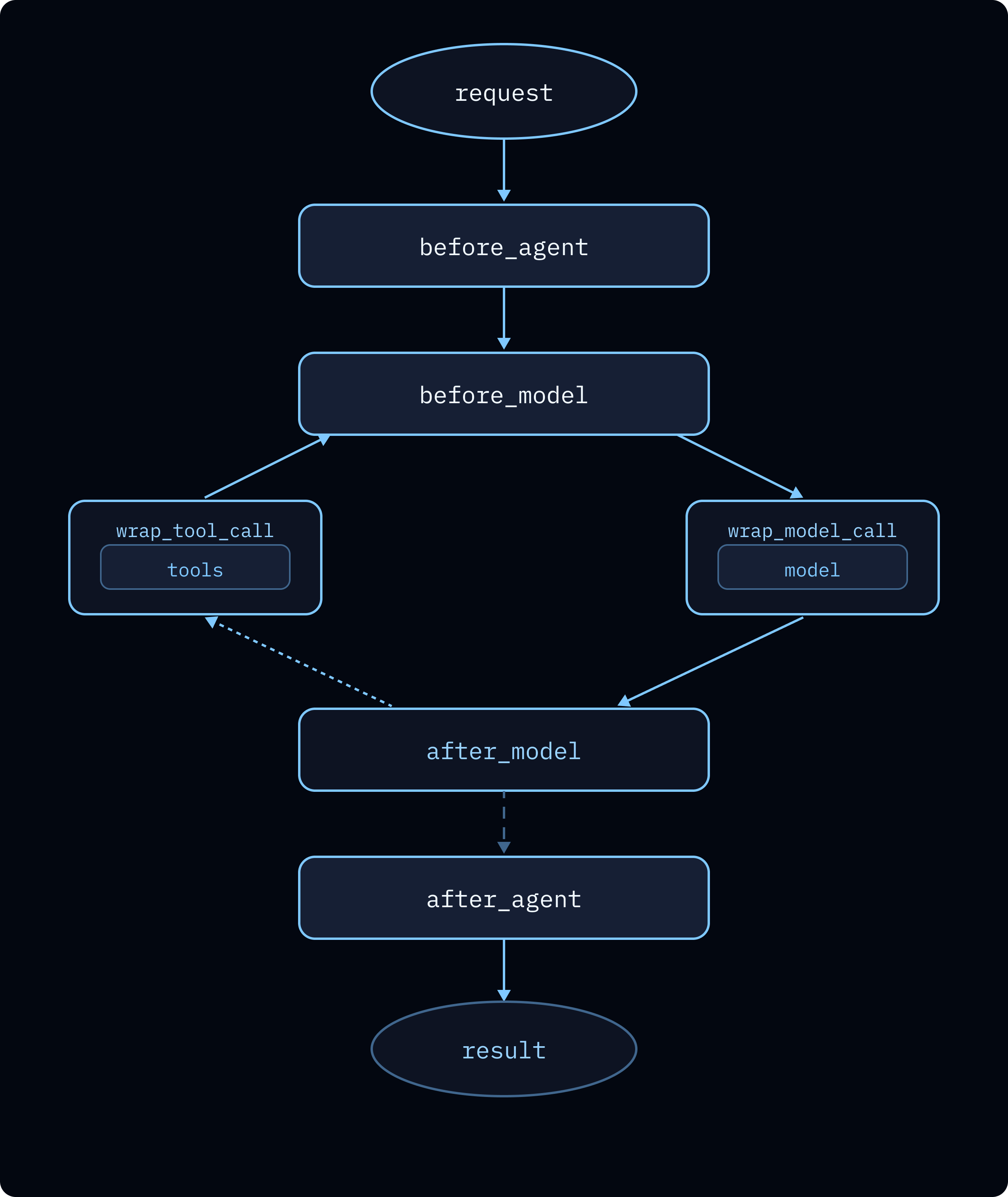
速率限制
这里的速率限制是指在单次运行内限制代理自身的 LLM 和工具使用,而不是传入请求的 API 网关速率限制。 没有限制,一个混乱的代理可能会在几分钟内通过循环调用同一个工具或进行数百次模型调用来耗尽您的 LLM API 预算。设置每次运行的模型调用和工具执行上限:run_limit 限制单次调用内的调用(每次轮次重置)。使用 thread_limit 限制整个对话中的调用(需要检查点)。有关完整配置,请参阅 ModelCallLimitMiddleware 和 ToolCallLimitMiddleware。
处理错误
并非所有错误都应以相同方式处理。瞬态故障(网络超时、速率限制)应自动重试。LLM 可以恢复的错误(错误的工具输出、解析失败)应反馈给模型。需要人工输入的错误应暂停代理。有关完整分解和代码示例,请参阅适当处理错误。 中间件处理瞬态情况。模型调用和工具调用各自有自己的重试中间件,具有指数退避。如果您的主要模型提供商完全宕机,回退中间件会切换到替代方案:read_file 不会从重试中受益,但超时的网络搜索可能会。有关完整配置,请参阅 ModelRetryMiddleware 和 ModelFallbackMiddleware。
数据隐私
如果您的代理处理可能包含电子邮件、信用卡号或其他 PII 的用户输入,您可以在其到达模型或存储在日志中之前检测并处理它:redact(替换为 [REDACTED_EMAIL])、mask(部分掩码,如 ****-****-****-1234)、hash(确定性哈希)和 block(引发错误)。您还可以为特定领域的模式编写自定义检测器。
有关完整配置,请参阅 piiMiddleware。
有关可用中间件的完整列表,请参阅预构建中间件。
前端
深度代理使用useStream 将您的 UI 连接到代理后端。useStream 是一个前端钩子(适用于 React、Vue、Svelte 和 Angular),可实时从您的代理流式传输消息、子代理进度和自定义状态。
在本地,useStream 指向 http://localhost:2024。在生产环境中,将其指向您的 LangSmith 部署并配置重连,以便用户在连接中断时不会丢失进度。
reconnectOnMount 会自动恢复进行中的运行。如果用户在代理工作时刷新页面,他们会看到它继续而不是空白屏幕。fetchStateHistory 加载线程的完整对话历史记录,因此返回的用户会看到之前的消息。
对于生成许多子代理的深度代理工作流,在提交时设置较高的 recursionLimit 以避免切断长时间运行的执行:
通过 MCP 将这些文档连接到 Claude、VSCode
等,以获取实时答案。