

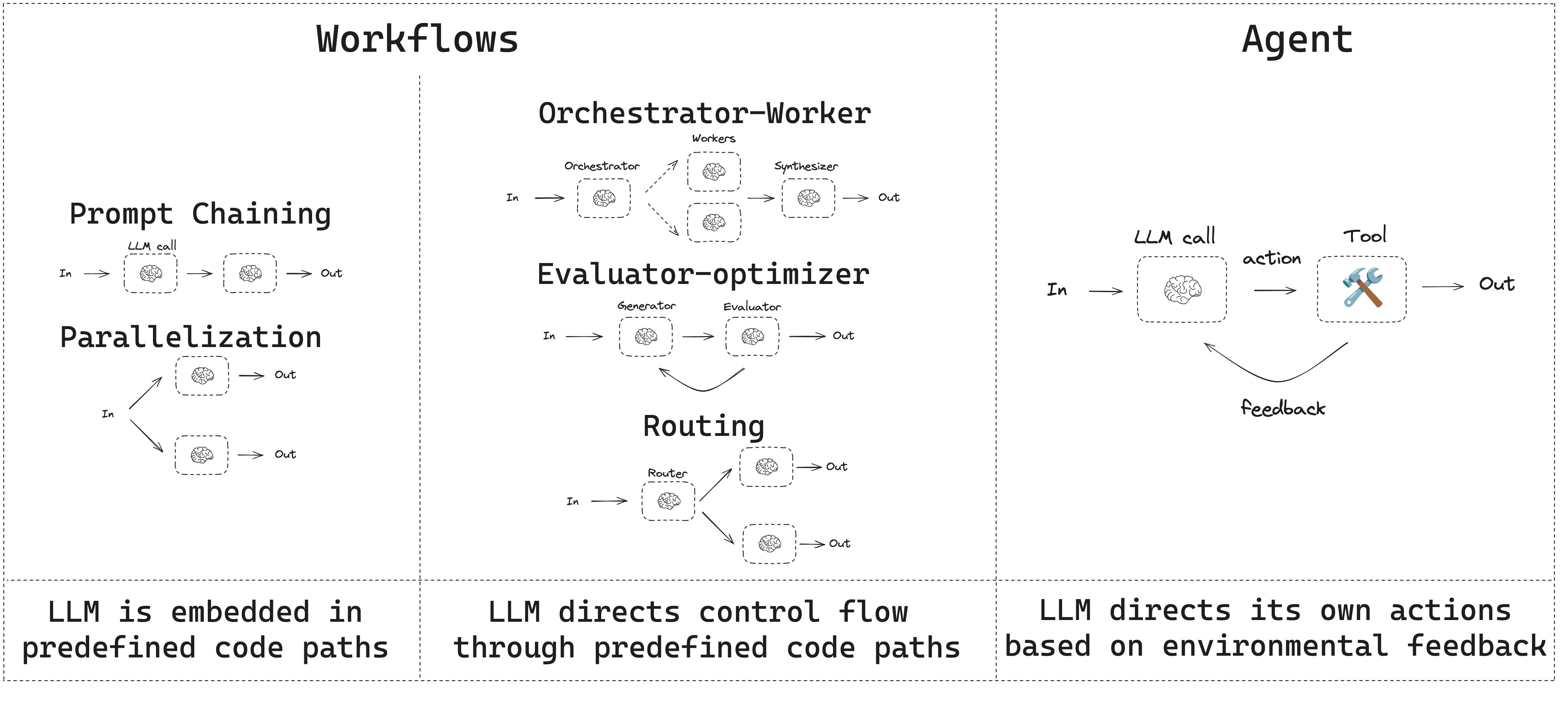
- 工作流具有预定的代码路径,旨在按特定顺序运行。
- 代理是动态的,定义自己的流程和工具使用方式。
设置
要构建工作流或代理,您可以使用任何支持结构化输出和工具调用的聊天模型。以下示例使用 Anthropic:- 安装依赖项:
pip install langchain_core langchain-anthropic langgraph
- 初始化 LLM:
import os
import getpass
from langchain_anthropic import ChatAnthropic
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("ANTHROPIC_API_KEY")
llm = ChatAnthropic(model="claude-sonnet-4-6")
LLM 与增强
工作流和代理系统基于 LLM 以及您添加到其中的各种增强功能。工具调用、结构化输出和短期记忆是根据需求定制 LLM 的几种选项。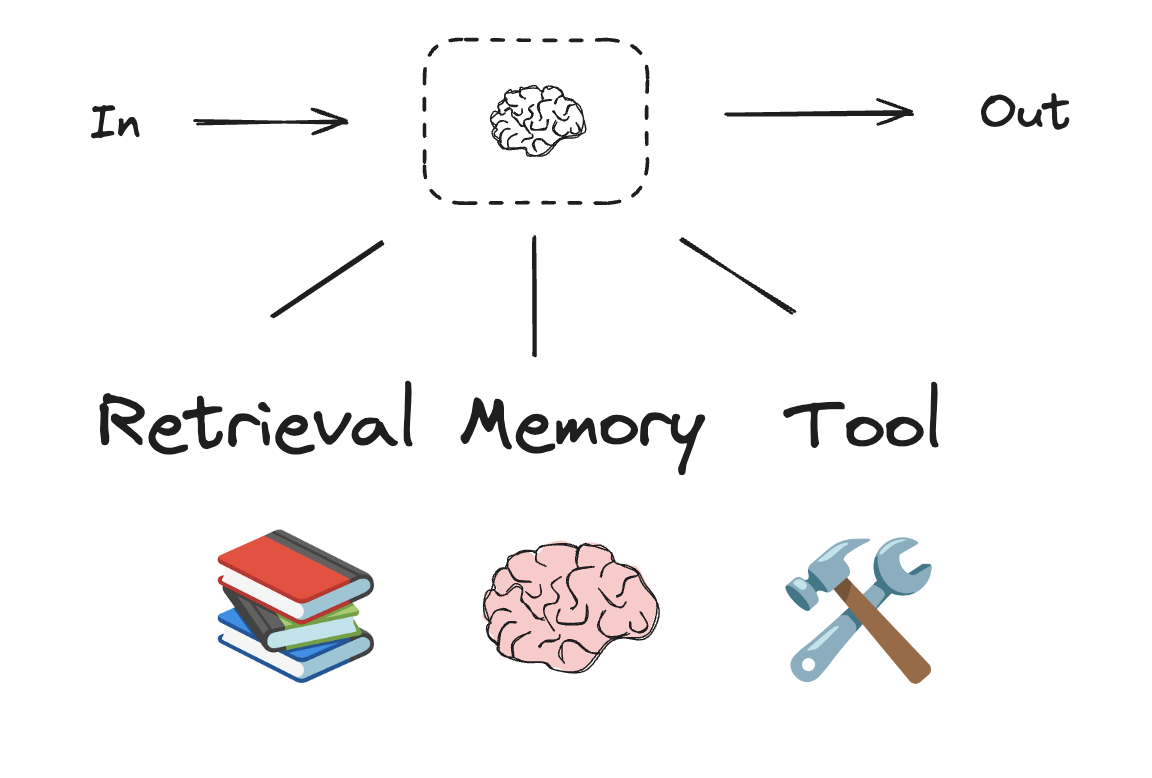
# 结构化输出的模式
from pydantic import BaseModel, Field
class SearchQuery(BaseModel):
search_query: str = Field(None, description="针对网络搜索优化的查询。")
justification: str = Field(
None, description="为什么此查询与用户的请求相关。"
)
# 使用结构化输出模式增强 LLM
structured_llm = llm.with_structured_output(SearchQuery)
# 调用增强后的 LLM
output = structured_llm.invoke("钙 CT 评分与高胆固醇有何关系?")
# 定义一个工具
def multiply(a: int, b: int) -> int:
return a * b
# 使用工具增强 LLM
llm_with_tools = llm.bind_tools([multiply])
# 调用 LLM,输入触发工具调用
msg = llm_with_tools.invoke("2 乘以 3 是多少?")
# 获取工具调用
msg.tool_calls
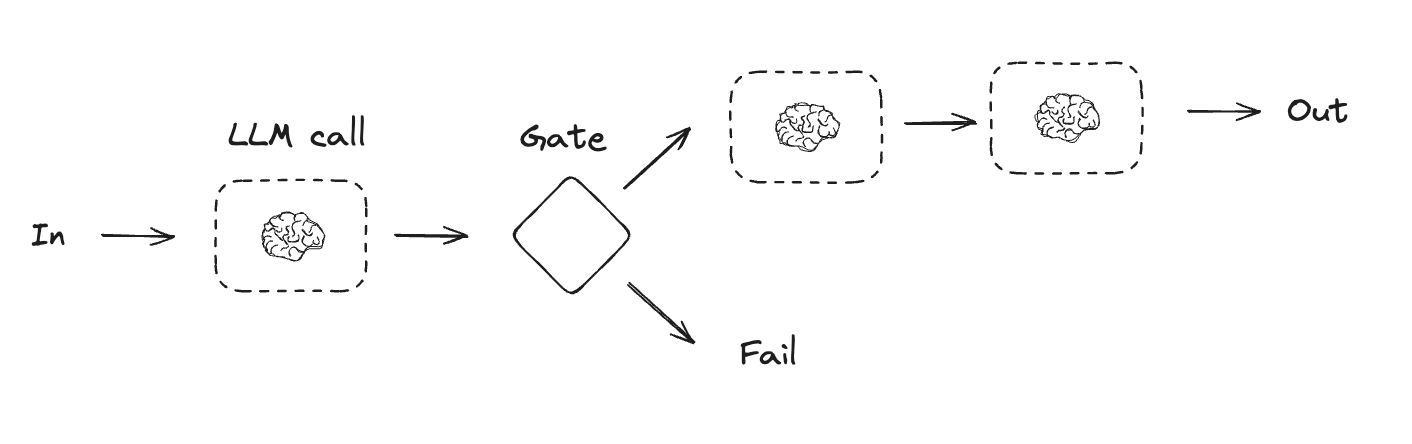
提示链
提示链是指每次 LLM 调用处理前一次调用的输出。它通常用于执行可以分解为更小、可验证步骤的明确任务。一些示例包括:- 将文档翻译成不同语言
- 验证生成内容的一致性
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
# 图状态
class State(TypedDict):
topic: str
joke: str
improved_joke: str
final_joke: str
# 节点
def generate_joke(state: State):
"""第一次 LLM 调用,生成初始笑话"""
msg = llm.invoke(f"写一个关于 {state['topic']} 的简短笑话")
return {"joke": msg.content}
def check_punchline(state: State):
"""检查笑话是否有笑点的门控函数"""
# 简单检查 - 笑话是否包含 "?" 或 "!"
if "?" in state["joke"] or "!" in state["joke"]:
return "Pass"
return "Fail"
def improve_joke(state: State):
"""第二次 LLM 调用,改进笑话"""
msg = llm.invoke(f"通过添加文字游戏让这个笑话更有趣:{state['joke']}")
return {"improved_joke": msg.content}
def polish_joke(state: State):
"""第三次 LLM 调用,最终润色"""
msg = llm.invoke(f"为这个笑话添加一个出人意料的转折:{state['improved_joke']}")
return {"final_joke": msg.content}
# 构建工作流
workflow = StateGraph(State)
# 添加节点
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke)
workflow.add_node("polish_joke", polish_joke)
# 添加边以连接节点
workflow.add_edge(START, "generate_joke")
workflow.add_conditional_edges(
"generate_joke", check_punchline, {"Fail": "improve_joke", "Pass": END}
)
workflow.add_edge("improve_joke", "polish_joke")
workflow.add_edge("polish_joke", END)
# 编译
chain = workflow.compile()
# 显示工作流
display(Image(chain.get_graph().draw_mermaid_png()))
# 调用
state = chain.invoke({"topic": "猫"})
print("初始笑话:")
print(state["joke"])
print("\n--- --- ---\n")
if "improved_joke" in state:
print("改进后的笑话:")
print(state["improved_joke"])
print("\n--- --- ---\n")
print("最终笑话:")
print(state["final_joke"])
else:
print("最终笑话:")
print(state["joke"])
from langgraph.func import entrypoint, task
# 任务
@task
def generate_joke(topic: str):
"""第一次 LLM 调用,生成初始笑话"""
msg = llm.invoke(f"写一个关于 {topic} 的简短笑话")
return msg.content
def check_punchline(joke: str):
"""检查笑话是否有笑点的门控函数"""
# 简单检查 - 笑话是否包含 "?" 或 "!"
if "?" in joke or "!" in joke:
return "Fail"
return "Pass"
@task
def improve_joke(joke: str):
"""第二次 LLM 调用,改进笑话"""
msg = llm.invoke(f"通过添加文字游戏让这个笑话更有趣:{joke}")
return msg.content
@task
def polish_joke(joke: str):
"""第三次 LLM 调用,最终润色"""
msg = llm.invoke(f"为这个笑话添加一个出人意料的转折:{joke}")
return msg.content
@entrypoint()
def prompt_chaining_workflow(topic: str):
original_joke = generate_joke(topic).result()
if check_punchline(original_joke) == "Pass":
return original_joke
improved_joke = improve_joke(original_joke).result()
return polish_joke(improved_joke).result()
# 调用
for step in prompt_chaining_workflow.stream("cats", stream_mode="updates"):
print(step)
print("\n")
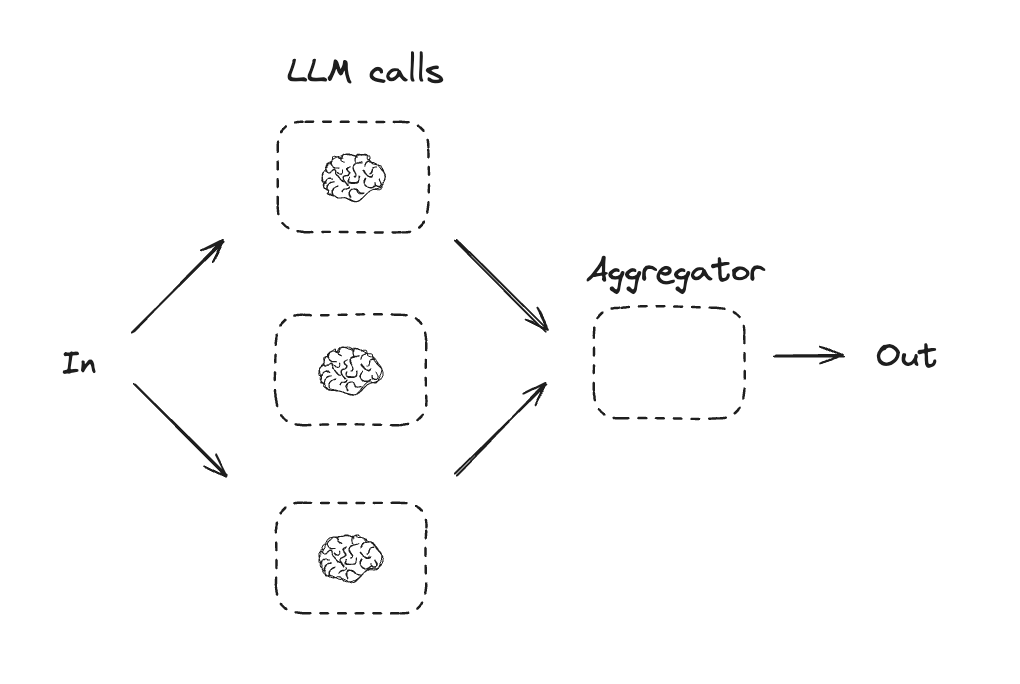
并行化
通过并行化,LLM 同时处理一个任务。这可以通过同时运行多个独立的子任务,或多次运行同一任务以检查不同的输出来实现。并行化通常用于:- 分割子任务并并行运行,从而提高速度
- 多次运行任务以检查不同的输出,从而提高置信度
- 运行一个处理文档关键词的子任务,以及第二个检查格式错误的子任务
- 多次运行一个任务,根据不同的标准(如引用数量、使用的来源数量以及来源质量)对文档的准确性进行评分
# 图状态
class State(TypedDict):
topic: str
joke: str
story: str
poem: str
combined_output: str
# 节点
def call_llm_1(state: State):
"""第一次 LLM 调用,生成初始笑话"""
msg = llm.invoke(f"写一个关于 {state['topic']} 的笑话")
return {"joke": msg.content}
def call_llm_2(state: State):
"""第二次 LLM 调用,生成故事"""
msg = llm.invoke(f"写一个关于 {state['topic']} 的故事")
return {"story": msg.content}
def call_llm_3(state: State):
"""第三次 LLM 调用,生成诗歌"""
msg = llm.invoke(f"写一首关于 {state['topic']} 的诗")
return {"poem": msg.content}
def aggregator(state: State):
"""将笑话、故事和诗歌组合成单个输出"""
combined = f"这是一个关于 {state['topic']} 的故事、笑话和诗歌!\n\n"
combined += f"故事:\n{state['story']}\n\n"
combined += f"笑话:\n{state['joke']}\n\n"
combined += f"诗歌:\n{state['poem']}"
return {"combined_output": combined}
# 构建工作流
parallel_builder = StateGraph(State)
# 添加节点
parallel_builder.add_node("call_llm_1", call_llm_1)
parallel_builder.add_node("call_llm_2", call_llm_2)
parallel_builder.add_node("call_llm_3", call_llm_3)
parallel_builder.add_node("aggregator", aggregator)
# 添加边以连接节点
parallel_builder.add_edge(START, "call_llm_1")
parallel_builder.add_edge(START, "call_llm_2")
parallel_builder.add_edge(START, "call_llm_3")
parallel_builder.add_edge("call_llm_1", "aggregator")
parallel_builder.add_edge("call_llm_2", "aggregator")
parallel_builder.add_edge("call_llm_3", "aggregator")
parallel_builder.add_edge("aggregator", END)
parallel_workflow = parallel_builder.compile()
# 显示工作流
display(Image(parallel_workflow.get_graph().draw_mermaid_png()))
# 调用
state = parallel_workflow.invoke({"topic": "cats"})
print(state["combined_output"])
@task
def call_llm_1(topic: str):
"""第一次 LLM 调用,生成初始笑话"""
msg = llm.invoke(f"写一个关于 {topic} 的笑话")
return msg.content
@task
def call_llm_2(topic: str):
"""第二次 LLM 调用,生成故事"""
msg = llm.invoke(f"写一个关于 {topic} 的故事")
return msg.content
@task
def call_llm_3(topic):
"""第三次 LLM 调用,生成诗歌"""
msg = llm.invoke(f"写一首关于 {topic} 的诗")
return msg.content
@task
def aggregator(topic, joke, story, poem):
"""将笑话和故事组合成单个输出"""
combined = f"这是一个关于 {topic} 的故事、笑话和诗歌!\n\n"
combined += f"故事:\n{story}\n\n"
combined += f"笑话:\n{joke}\n\n"
combined += f"诗歌:\n{poem}"
return combined
# 构建工作流
@entrypoint()
def parallel_workflow(topic: str):
joke_fut = call_llm_1(topic)
story_fut = call_llm_2(topic)
poem_fut = call_llm_3(topic)
return aggregator(
topic, joke_fut.result(), story_fut.result(), poem_fut.result()
).result()
# 调用
for step in parallel_workflow.stream("cats", stream_mode="updates"):
print(step)
print("\n")
路由
路由工作流处理输入,然后将其定向到特定上下文的任务。这允许您为复杂任务定义专门的流程。例如,一个为回答产品相关问题而构建的工作流可能会先处理问题类型,然后将请求路由到定价、退款、退货等特定流程。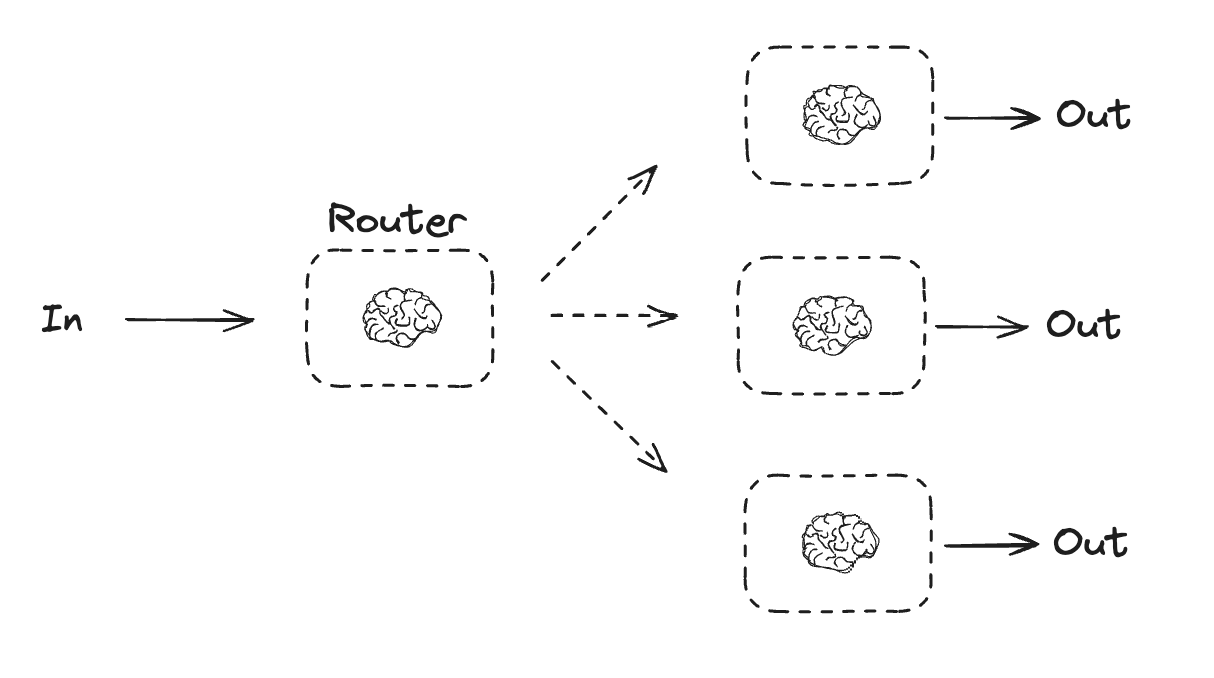
from typing_extensions import Literal
from langchain.messages import HumanMessage, SystemMessage
# 用作路由逻辑的结构化输出模式
class Route(BaseModel):
step: Literal["poem", "story", "joke"] = Field(
None, description="路由过程中的下一步"
)
# 使用结构化输出模式增强 LLM
router = llm.with_structured_output(Route)
# 状态
class State(TypedDict):
input: str
decision: str
output: str
# 节点
def llm_call_1(state: State):
"""写一个故事"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_2(state: State):
"""写一个笑话"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_3(state: State):
"""写一首诗"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_router(state: State):
"""将输入路由到适当的节点"""
# 运行具有结构化输出的增强 LLM 作为路由逻辑
decision = router.invoke(
[
SystemMessage(
content="根据用户的请求将输入路由到故事、笑话或诗歌。"
),
HumanMessage(content=state["input"]),
]
)
return {"decision": decision.step}
# 条件边函数,路由到适当的节点
def route_decision(state: State): # 返回您接下来要访问的节点名称
if state["decision"] == "story":
return "llm_call_1"
elif state["decision"] == "joke":
return "llm_call_2"
elif state["decision"] == "poem":
return "llm_call_3"
# 构建工作流
router_builder = StateGraph(State)
# 添加节点
router_builder.add_node("llm_call_1", llm_call_1)
router_builder.add_node("llm_call_2", llm_call_2)
router_builder.add_node("llm_call_3", llm_call_3)
router_builder.add_node("llm_call_router", llm_call_router)
# 添加边以连接节点
router_builder.add_edge(START, "llm_call_router")
router_builder.add_conditional_edges(
"llm_call_router",
route_decision,
{ # route_decision 返回的名称 : 下一个要访问的节点名称
"llm_call_1": "llm_call_1",
"llm_call_2": "llm_call_2",
"llm_call_3": "llm_call_3",
},
)
router_builder.add_edge("llm_call_1", END)
router_builder.add_edge("llm_call_2", END)
router_builder.add_edge("llm_call_3", END)
# 编译工作流
router_workflow = router_builder.compile()
# 显示工作流
display(Image(router_workflow.get_graph().draw_mermaid_png()))
# 调用
state = router_workflow.invoke({"input": "给我写一个关于猫的笑话"})
print(state["output"])
from typing_extensions import Literal
from pydantic import BaseModel
from langchain.messages import HumanMessage, SystemMessage
# 用作路由逻辑的结构化输出模式
class Route(BaseModel):
step: Literal["poem", "story", "joke"] = Field(
None, description="路由过程中的下一步"
)
# 使用结构化输出模式增强 LLM
router = llm.with_structured_output(Route)
@task
def llm_call_1(input_: str):
"""写一个故事"""
result = llm.invoke(input_)
return result.content
@task
def llm_call_2(input_: str):
"""写一个笑话"""
result = llm.invoke(input_)
return result.content
@task
def llm_call_3(input_: str):
"""写一首诗"""
result = llm.invoke(input_)
return result.content
def llm_call_router(input_: str):
"""将输入路由到适当的节点"""
# 运行具有结构化输出的增强 LLM 作为路由逻辑
decision = router.invoke(
[
SystemMessage(
content="根据用户的请求将输入路由到故事、笑话或诗歌。"
),
HumanMessage(content=input_),
]
)
return decision.step
# 创建工作流
@entrypoint()
def router_workflow(input_: str):
next_step = llm_call_router(input_)
if next_step == "story":
llm_call = llm_call_1
elif next_step == "joke":
llm_call = llm_call_2
elif next_step == "poem":
llm_call = llm_call_3
return llm_call(input_).result()
# 调用
for step in router_workflow.stream("给我写一个关于猫的笑话", stream_mode="updates"):
print(step)
print("\n")
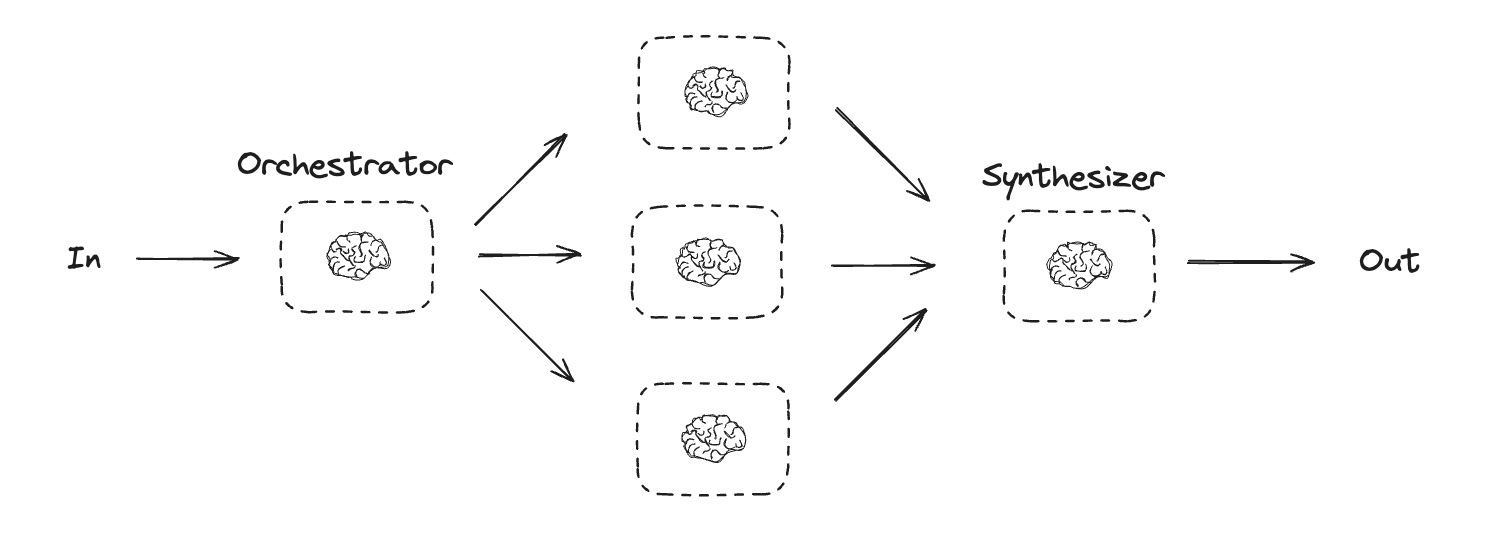
编排器-工作者
在编排器-工作者配置中,编排器:- 将任务分解为子任务
- 将子任务委派给工作者
- 将工作者的输出合成为最终结果
from typing import Annotated, List
import operator
# 用于规划的结构化输出模式
class Section(BaseModel):
name: str = Field(
description="报告此部分的名称。",
)
description: str = Field(
description="本节涵盖的主要主题和概念的简要概述。",
)
class Sections(BaseModel):
sections: List[Section] = Field(
description="报告的各个部分。",
)
# 使用结构化输出模式增强 LLM
planner = llm.with_structured_output(Sections)
from typing import List
# 用于规划的结构化输出模式
class Section(BaseModel):
name: str = Field(
description="报告此部分的名称。",
)
description: str = Field(
description="本节涵盖的主要主题和概念的简要概述。",
)
class Sections(BaseModel):
sections: List[Section] = Field(
description="报告的各个部分。",
)
# 使用结构化输出模式增强 LLM
planner = llm.with_structured_output(Sections)
@task
def orchestrator(topic: str):
"""生成报告计划的编排器"""
# 生成查询
report_sections = planner.invoke(
[
SystemMessage(content="生成报告计划。"),
HumanMessage(content=f"以下是报告主题:{topic}"),
]
)
return report_sections.sections
@task
def llm_call(section: Section):
"""工作者撰写报告的一部分"""
# 生成部分
result = llm.invoke(
[
SystemMessage(content="撰写报告部分。"),
HumanMessage(
content=f"以下是部分名称:{section.name} 和描述:{section.description}"
),
]
)
# 将更新后的部分写入已完成的部分
return result.content
@task
def synthesizer(completed_sections: list[str]):
"""从各部分合成完整报告"""
final_report = "\n\n---\n\n".join(completed_sections)
return final_report
@entrypoint()
def orchestrator_worker(topic: str):
sections = orchestrator(topic).result()
section_futures = [llm_call(section) for section in sections]
final_report = synthesizer(
[section_fut.result() for section_fut in section_futures]
).result()
return final_report
# 调用
report = orchestrator_worker.invoke("创建一份关于 LLM 扩展定律的报告")
from IPython.display import Markdown
Markdown(report)
在 LangGraph 中创建工作者
编排器-工作者工作流很常见,LangGraph 对其提供了内置支持。Send API 允许您动态创建工作者节点并向其发送特定输入。每个工作者都有自己的状态,所有工作者的输出都写入一个共享状态键,该键可由编排器图访问。这使编排器可以访问所有工作者的输出,并将其合成为最终输出。下面的示例遍历一个部分列表,并使用 Send API 将每个部分发送给一个工作者。
from langgraph.types import Send
# 图状态
class State(TypedDict):
topic: str # 报告主题
sections: list[Section] # 报告部分列表
completed_sections: Annotated[
list, operator.add
] # 所有工作者并行写入此键
final_report: str # 最终报告
# 工作者状态
class WorkerState(TypedDict):
section: Section
completed_sections: Annotated[list, operator.add]
# 节点
def orchestrator(state: State):
"""生成报告计划的编排器"""
# 生成查询
report_sections = planner.invoke(
[
SystemMessage(content="生成报告计划。"),
HumanMessage(content=f"以下是报告主题:{state['topic']}"),
]
)
return {"sections": report_sections.sections}
def llm_call(state: WorkerState):
"""工作者撰写报告的一部分"""
# 生成部分
section = llm.invoke(
[
SystemMessage(
content="按照提供的名称和描述撰写报告部分。每个部分不包含前言。使用 markdown 格式。"
),
HumanMessage(
content=f"以下是部分名称:{state['section'].name} 和描述:{state['section'].description}"
),
]
)
# 将更新后的部分写入已完成的部分
return {"completed_sections": [section.content]}
def synthesizer(state: State):
"""从各部分合成完整报告"""
# 已完成部分列表
completed_sections = state["completed_sections"]
# 将已完成的部分格式化为字符串,用作最终部分的上下文
completed_report_sections = "\n\n---\n\n".join(completed_sections)
return {"final_report": completed_report_sections}
# 条件边函数,创建每个撰写报告一部分的 llm_call 工作者
def assign_workers(state: State):
"""为计划中的每个部分分配一个工作者"""
# 通过 Send() API 并行启动部分撰写
return [Send("llm_call", {"section": s}) for s in state["sections"]]
# 构建工作流
orchestrator_worker_builder = StateGraph(State)
# 添加节点
orchestrator_worker_builder.add_node("orchestrator", orchestrator)
orchestrator_worker_builder.add_node("llm_call", llm_call)
orchestrator_worker_builder.add_node("synthesizer", synthesizer)
# 添加边以连接节点
orchestrator_worker_builder.add_edge(START, "orchestrator")
orchestrator_worker_builder.add_conditional_edges(
"orchestrator", assign_workers, ["llm_call"]
)
orchestrator_worker_builder.add_edge("llm_call", "synthesizer")
orchestrator_worker_builder.add_edge("synthesizer", END)
# 编译工作流
orchestrator_worker = orchestrator_worker_builder.compile()
# 显示工作流
display(Image(orchestrator_worker.get_graph().draw_mermaid_png()))
# 调用
state = orchestrator_worker.invoke({"topic": "创建一份关于 LLM 扩展定律的报告"})
from IPython.display import Markdown
Markdown(state["final_report"])
评估器-优化器
在评估器-优化器工作流中,一次 LLM 调用创建响应,另一次调用评估该响应。如果评估器或Human in the Loop确定响应需要改进,则会提供反馈并重新创建响应。此循环持续进行,直到生成可接受的响应。 评估器-优化器工作流通常在任务有特定成功标准但需要迭代才能满足该标准时使用。例如,在两种语言之间翻译文本时,并不总是有完美的匹配。可能需要几次迭代才能生成在两种语言中具有相同含义的翻译。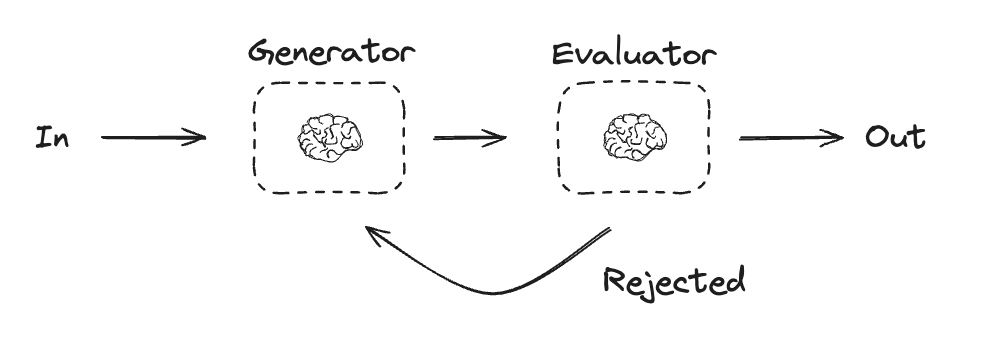
# 图状态
class State(TypedDict):
joke: str
topic: str
feedback: str
funny_or_not: str
# 用于评估的结构化输出模式
class Feedback(BaseModel):
grade: Literal["funny", "not funny"] = Field(
description="判断笑话是否有趣。",
)
feedback: str = Field(
description="如果笑话不有趣,请提供如何改进的反馈。",
)
# 使用结构化输出模式增强 LLM
evaluator = llm.with_structured_output(Feedback)
# 节点
def llm_call_generator(state: State):
"""LLM 生成一个笑话"""
if state.get("feedback"):
msg = llm.invoke(
f"写一个关于 {state['topic']} 的笑话,但要考虑反馈:{state['feedback']}"
)
else:
msg = llm.invoke(f"写一个关于 {state['topic']} 的笑话")
return {"joke": msg.content}
def llm_call_evaluator(state: State):
"""LLM 评估笑话"""
grade = evaluator.invoke(f"为笑话评分 {state['joke']}")
return {"funny_or_not": grade.grade, "feedback": grade.feedback}
# 条件边函数,根据评估器的反馈路由回笑话生成器或结束
def route_joke(state: State):
"""根据评估器的反馈路由回笑话生成器或结束"""
if state["funny_or_not"] == "funny":
return "Accepted"
elif state["funny_or_not"] == "not funny":
return "Rejected + Feedback"
# 构建工作流
optimizer_builder = StateGraph(State)
# 添加节点
optimizer_builder.add_node("llm_call_generator", llm_call_generator)
optimizer_builder.add_node("llm_call_evaluator", llm_call_evaluator)
# 添加边以连接节点
optimizer_builder.add_edge(START, "llm_call_generator")
optimizer_builder.add_edge("llm_call_generator", "llm_call_evaluator")
optimizer_builder.add_conditional_edges(
"llm_call_evaluator",
route_joke,
{ # route_joke 返回的名称 : 下一个要访问的节点名称
"Accepted": END,
"Rejected + Feedback": "llm_call_generator",
},
)
# 编译工作流
optimizer_workflow = optimizer_builder.compile()
# 显示工作流
display(Image(optimizer_workflow.get_graph().draw_mermaid_png()))
# 调用
state = optimizer_workflow.invoke({"topic": "猫"})
print(state["joke"])
# 用于评估的结构化输出模式
class Feedback(BaseModel):
grade: Literal["funny", "not funny"] = Field(
description="判断笑话是否有趣。",
)
feedback: str = Field(
description="如果笑话不有趣,请提供如何改进的反馈。",
)
# 使用结构化输出模式增强 LLM
evaluator = llm.with_structured_output(Feedback)
# 节点
@task
def llm_call_generator(topic: str, feedback: Feedback):
"""LLM 生成一个笑话"""
if feedback:
msg = llm.invoke(
f"写一个关于 {topic} 的笑话,但要考虑反馈:{feedback}"
)
else:
msg = llm.invoke(f"写一个关于 {topic} 的笑话")
return msg.content
@task
def llm_call_evaluator(joke: str):
"""LLM 评估笑话"""
feedback = evaluator.invoke(f"为笑话评分 {joke}")
return feedback
@entrypoint()
def optimizer_workflow(topic: str):
feedback = None
while True:
joke = llm_call_generator(topic, feedback).result()
feedback = llm_call_evaluator(joke).result()
if feedback.grade == "funny":
break
return joke
# 调用
for step in optimizer_workflow.stream("Cats", stream_mode="updates"):
print(step)
print("\n")
代理
代理通常实现为使用工具执行操作的 LLM。它们在持续的反馈循环中运行,用于问题和解决方案不可预测的情况。代理比工作流具有更多的自主权,可以决定使用哪些工具以及如何解决问题。您仍然可以定义可用的工具集和代理行为准则。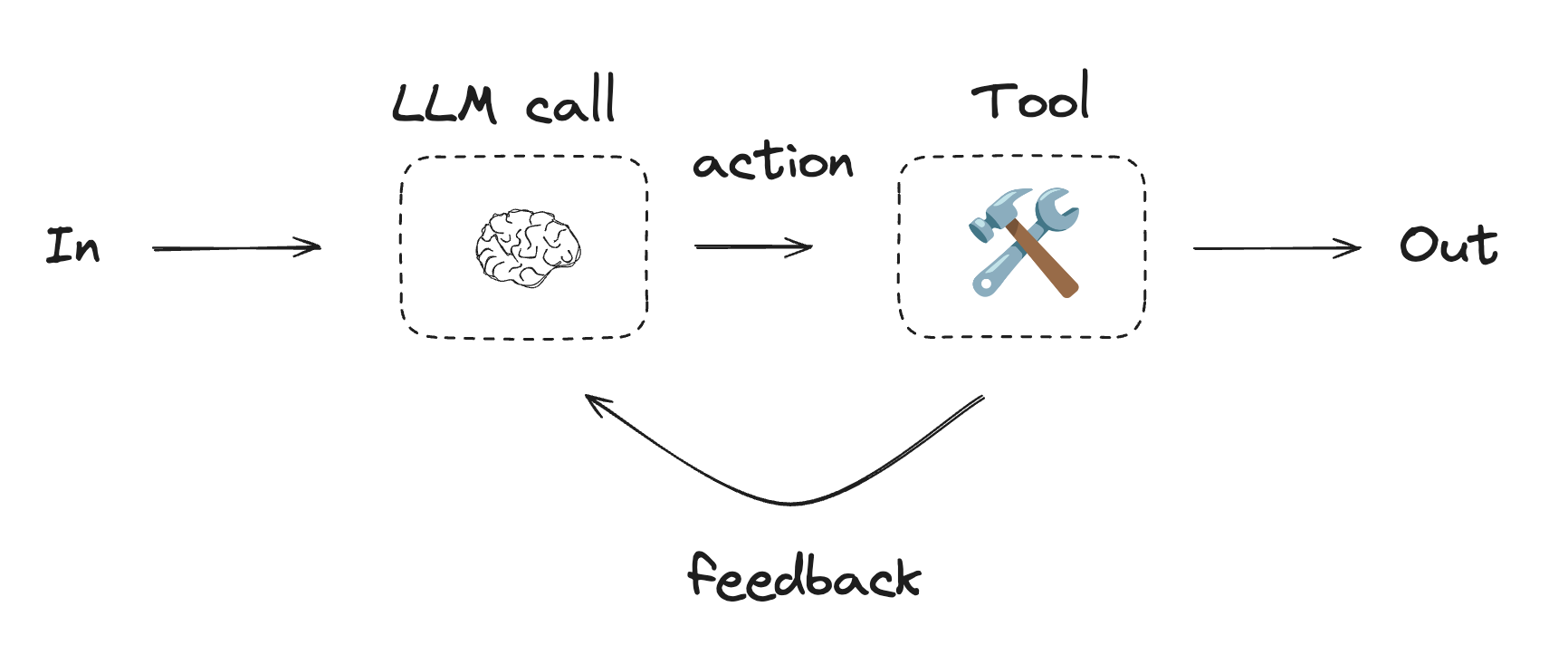
使用工具
from langchain.tools import tool
# 定义工具
@tool
def multiply(a: int, b: int) -> int:
"""将 `a` 和 `b` 相乘。
参数:
a: 第一个整数
b: 第二个整数
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""将 `a` 和 `b` 相加。
参数:
a: 第一个整数
b: 第二个整数
"""
return a + b
@tool
def divide(a: int, b: int) -> float:
"""将 `a` 除以 `b`。
参数:
a: 第一个整数
b: 第二个整数
"""
return a / b
# 使用工具增强 LLM
tools = [add, multiply, divide]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)
from langgraph.graph import MessagesState
from langchain.messages import SystemMessage, HumanMessage, ToolMessage
# 节点
def llm_call(state: MessagesState):
"""LLM 决定是否调用工具"""
return {
"messages": [
llm_with_tools.invoke(
[
SystemMessage(
content="你是一个有用的助手,负责对一组输入执行算术运算。"
)
]
+ state["messages"]
)
]
}
def tool_node(state: dict):
"""执行工具调用"""
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))
return {"messages": result}
# 条件边函数,根据 LLM 是否进行工具调用路由到工具节点或结束
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
"""根据 LLM 是否进行工具调用决定是继续循环还是停止"""
messages = state["messages"]
last_message = messages[-1]
# 如果 LLM 进行工具调用,则执行操作
if last_message.tool_calls:
return "tool_node"
# 否则,我们停止(回复用户)
return END
# 构建工作流
agent_builder = StateGraph(MessagesState)
# 添加节点
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("tool_node", tool_node)
# 添加边以连接节点
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
["tool_node", END]
)
agent_builder.add_edge("tool_node", "llm_call")
# 编译代理
agent = agent_builder.compile()
# 显示代理
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
# 调用
messages = [HumanMessage(content="将 3 和 4 相加。")]
messages = agent.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()
from langgraph.graph import add_messages
from langchain.messages import (
SystemMessage,
HumanMessage,
ToolCall,
)
from langchain_core.messages import BaseMessage
@task
def call_llm(messages: list[BaseMessage]):
"""LLM 决定是否调用工具"""
return llm_with_tools.invoke(
[
SystemMessage(
content="你是一个有用的助手,负责对一组输入执行算术运算。"
)
]
+ messages
)
@task
def call_tool(tool_call: ToolCall):
"""执行工具调用"""
tool = tools_by_name[tool_call["name"]]
return tool.invoke(tool_call)
@entrypoint()
def agent(messages: list[BaseMessage]):
llm_response = call_llm(messages).result()
while True:
if not llm_response.tool_calls:
break
# 执行工具
tool_result_futures = [
call_tool(tool_call) for tool_call in llm_response.tool_calls
]
tool_results = [fut.result() for fut in tool_result_futures]
messages = add_messages(messages, [llm_response, *tool_results])
llm_response = call_llm(messages).result()
messages = add_messages(messages, llm_response)
return messages
# 调用
messages = [HumanMessage(content="将 3 和 4 相加。")]
for chunk in agent.stream(messages, stream_mode="updates"):
print(chunk)
print("\n")
将这些文档连接到 Claude、VSCode 等,通过 MCP
获取实时答案。