

Agent Server 自动处理检查点保存
当使用 Agent Server 时,您无需手动实现或配置检查点保存器。服务器会在后台为您处理所有持久化基础设施。
为什么使用持久化
以下功能需要持久化:- 人机交互:检查点保存器通过允许人类检查、中断和批准图步骤来促进人机交互工作流。这些工作流需要检查点保存器,因为人员必须能够在任何时间点查看图的状态,并且图必须能够在人员对状态进行任何更新后恢复执行。有关示例,请参阅中断。
- 记忆:检查点保存器允许在交互之间存在”记忆”。在重复的人类交互(如对话)的情况下,任何后续消息都可以发送到该线程,该线程将保留其对先前交互的记忆。有关如何使用检查点保存器添加和管理对话记忆的信息,请参阅添加记忆。
- 时间旅行:检查点保存器允许”时间旅行”,允许用户重放先前的图执行以审查和/或调试特定的图步骤。此外,检查点保存器使得可以在任意检查点处分叉图状态,以探索替代轨迹。
- 容错性:检查点保存提供了容错性和错误恢复:如果一个或多个节点在给定的超级步骤中失败,您可以从最后一个成功的步骤重新启动图。
- 待处理写入:当图节点在给定的超级步骤中执行失败时,LangGraph 会存储在该超级步骤中成功完成的任何其他节点的待处理检查点写入。当您从该超级步骤恢复图执行时,您不会重新运行成功的节点。
核心概念
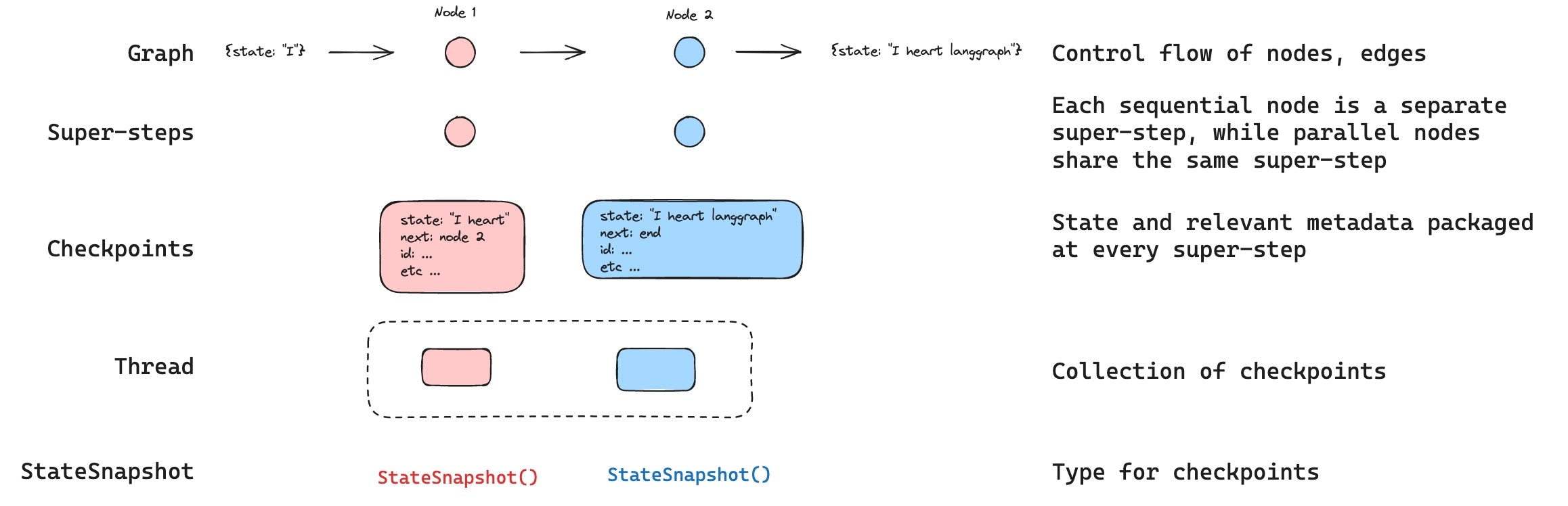
线程
线程是分配给检查点保存器保存的每个检查点的唯一 ID 或线程标识符。它包含一系列运行的累积状态。当运行执行时,助手底层图的状态将被持久化到线程中。 当使用检查点保存器调用图时,您必须在配置的configurable 部分指定 thread_id:
thread_id 作为存储和检索检查点的主键。没有它,检查点保存器无法保存状态或在中断后恢复执行,因为检查点保存器使用 thread_id 来加载保存的状态。
检查点
线程在特定时间点的状态称为检查点。检查点是在每个超级步骤保存的图状态快照,由StateSnapshot 对象表示(有关完整字段参考,请参阅 StateSnapshot 字段)。
超级步骤
LangGraph 在每个超级步骤边界创建一个检查点。超级步骤是图的一个单独“滴答”,其中为该步骤调度的所有节点执行(可能并行执行)。对于像START -> A -> B -> END 这样的顺序图,输入、节点 A 和节点 B 有单独的超级步骤——在每个之后产生一个检查点。理解超级步骤边界对于时间旅行很重要,因为您只能从检查点(即超级步骤边界)恢复执行。
检查点被持久化,可用于在以后恢复线程的状态。
让我们看看当以如下方式调用简单图时保存了哪些检查点:
- 空检查点,下一个要执行的节点是
START - 包含用户输入
{'foo': '', 'bar': []}的检查点,下一个要执行的节点是node_a - 包含
node_a输出{'foo': 'a', 'bar': ['a']}的检查点,下一个要执行的节点是node_b - 包含
node_b输出{'foo': 'b', 'bar': ['a', 'b']}的检查点,没有下一个要执行的节点
bar 通道值包含来自两个节点的输出,因为我们为 bar 通道定义了一个归约器。
检查点命名空间
每个检查点都有一个checkpoint_ns(检查点命名空间)字段,用于标识它属于哪个图或子图:
""(空字符串):检查点属于父(根)图。"node_name:uuid":检查点属于作为给定节点调用的子图。对于嵌套子图,命名空间使用|分隔符连接(例如,"outer_node:uuid|inner_node:uuid")。
获取和更新状态
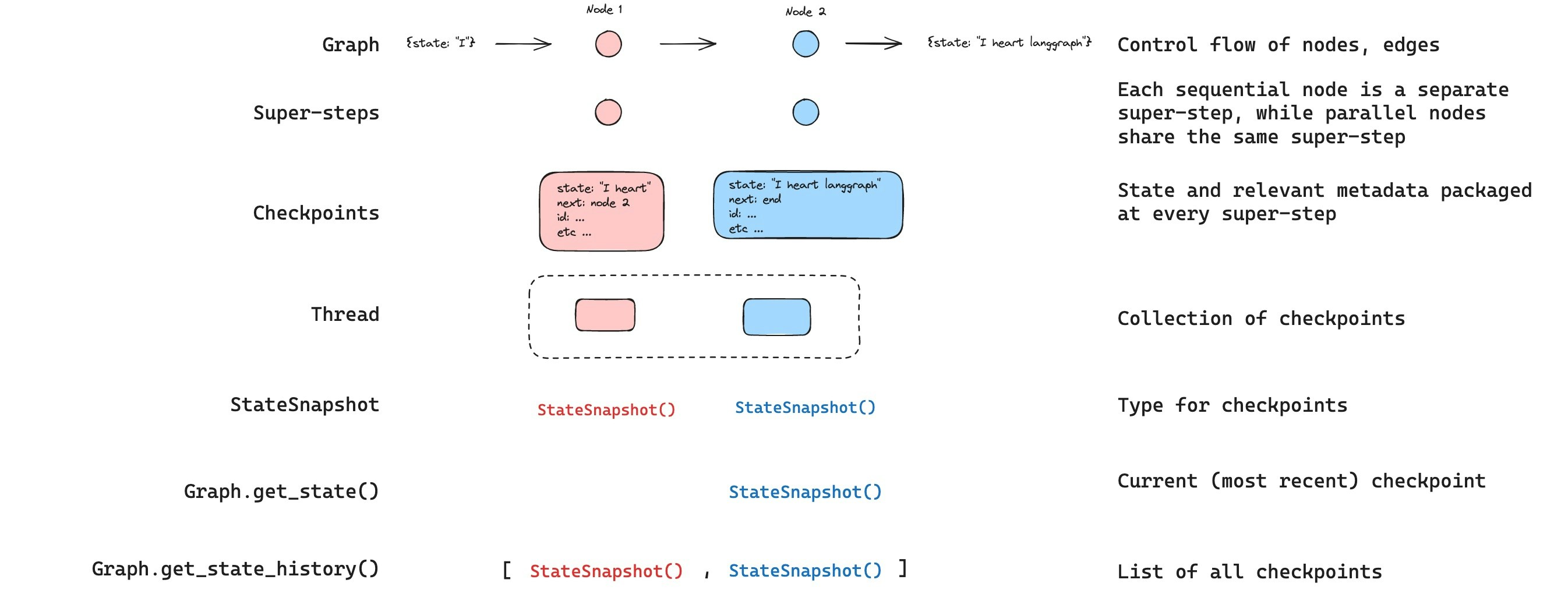
获取状态
与保存的图状态交互时,您必须指定线程标识符。您可以通过调用graph.get_state(config) 来查看图的_最新_状态。这将返回一个 StateSnapshot 对象,该对象对应于与配置中提供的线程 ID 关联的最新检查点,或者如果提供了检查点 ID,则对应于与该线程关联的检查点 ID 的检查点。
get_state 的输出将如下所示:
StateSnapshot 字段
获取状态历史记录
您可以通过调用graph.get_state_history(config) 来获取给定线程的完整图执行历史记录。这将返回与配置中提供的线程 ID 关联的 StateSnapshot 对象列表。重要的是,检查点将按时间顺序排列,最新的检查点/StateSnapshot 是列表中的第一个。
get_state_history 的输出将如下所示:
查找特定检查点
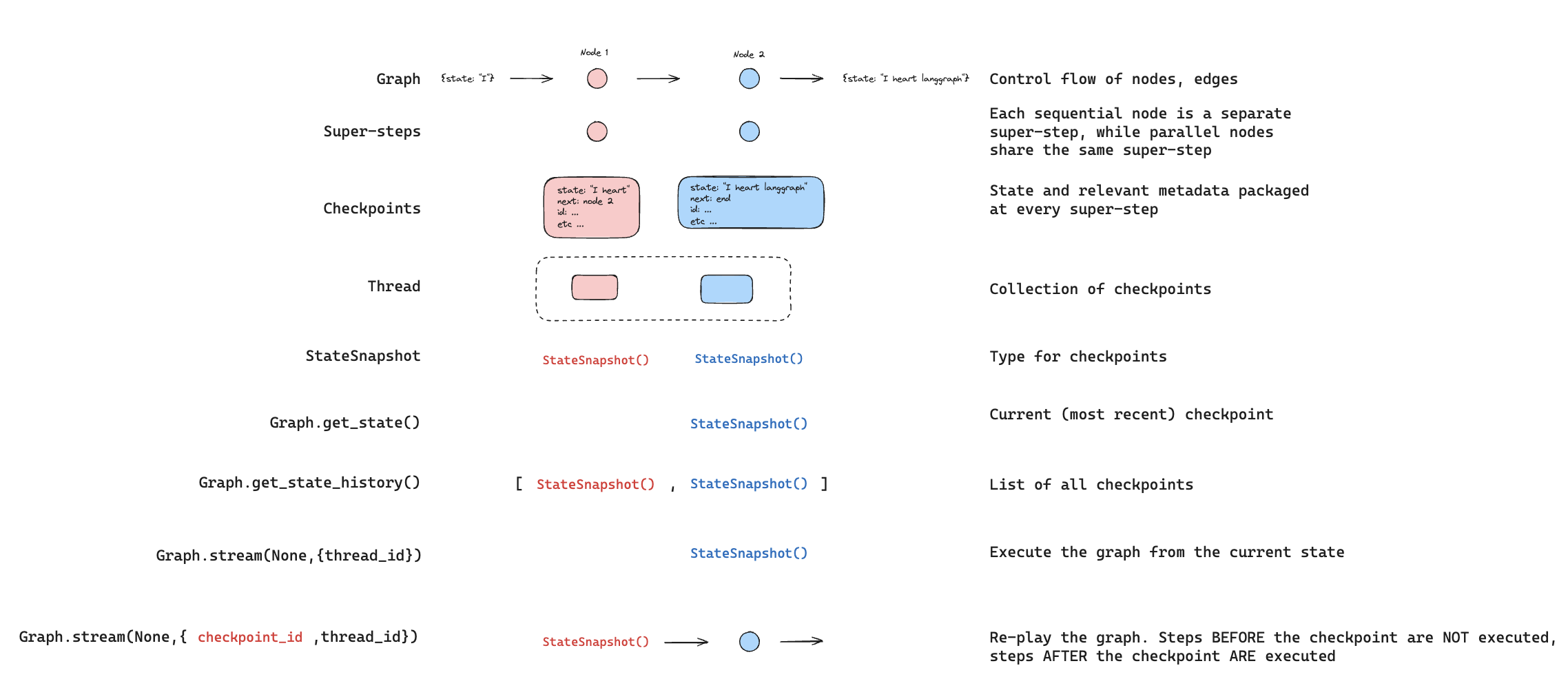
您可以过滤状态历史记录以查找符合特定条件的检查点:重放
重放会重新执行来自先前检查点的步骤。使用先前的checkpoint_id 调用图,以重新运行该检查点之后的节点。检查点之前的节点被跳过(它们的结果已保存)。检查点之后的节点重新执行,包括任何 LLM 调用、API 请求或中断——在重放期间总是会重新触发。
有关重放过去执行的完整详细信息和代码示例,请参阅时间旅行。
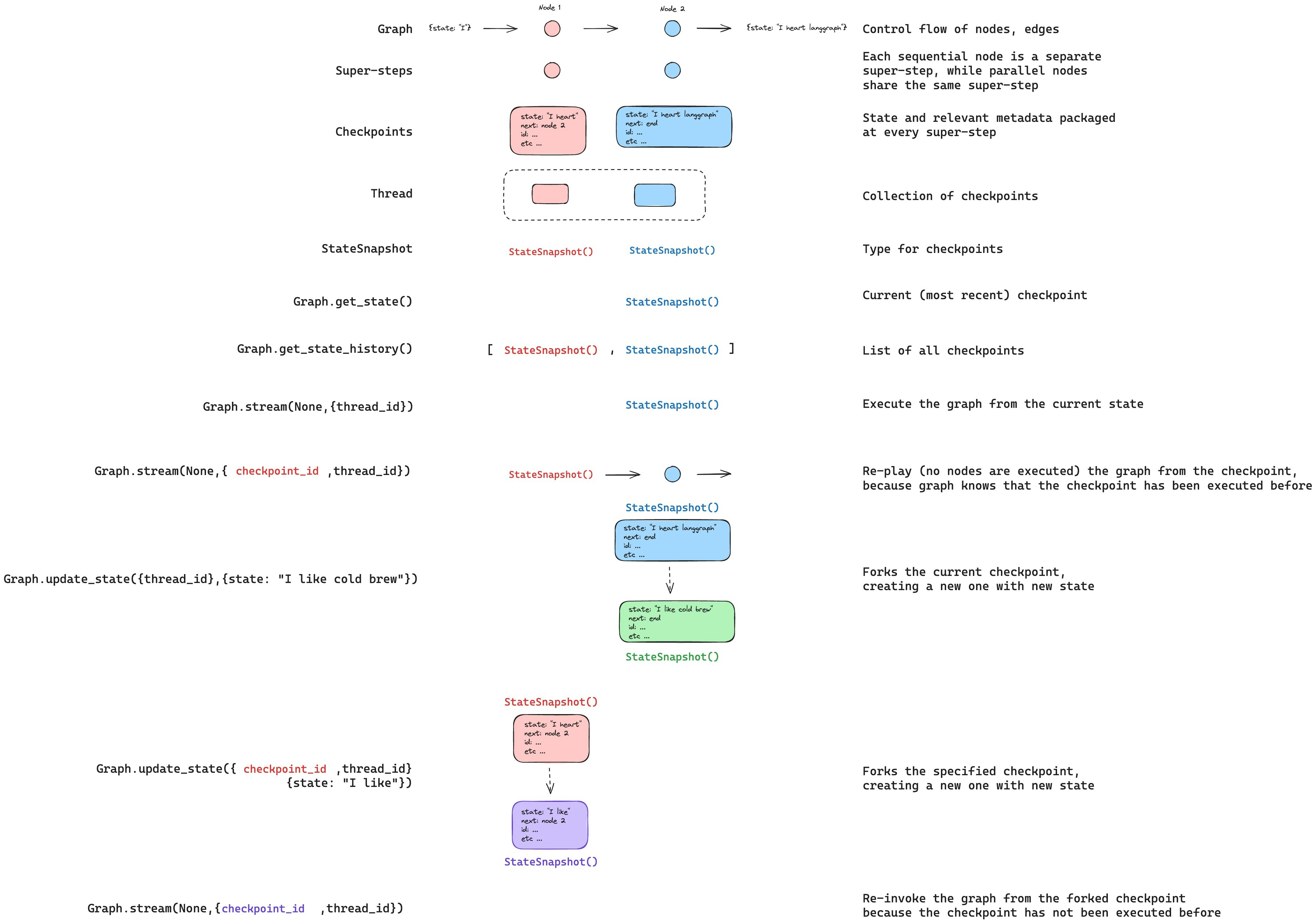
更新状态
您可以使用update_state 编辑图状态。这会创建一个具有更新值的新检查点——它不会修改原始检查点。更新的处理方式与节点更新相同:当定义了归约器函数时,值会通过归约器函数传递,因此带有归约器的通道会_累积_值而不是覆盖它们。
您可以选择指定 as_node 来控制更新被视为来自哪个节点,这会影响接下来执行哪个节点。有关详细信息,请参阅时间旅行:as_node。
存储
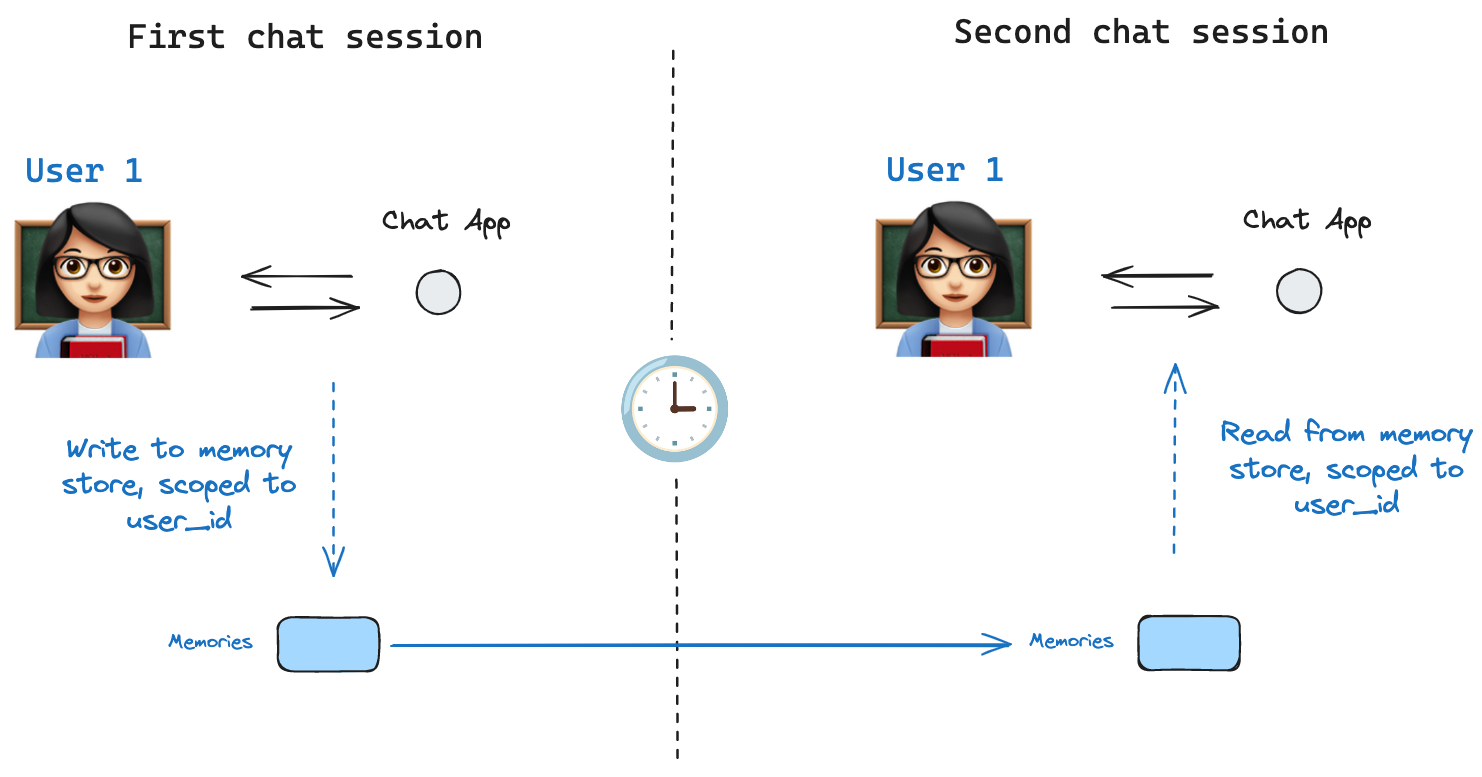
Store 接口。作为说明,我们可以定义一个 InMemoryStore 来跨线程存储关于用户的信息。我们只需像以前一样使用检查点保存器编译图,并传递存储。
LangGraph API 自动处理存储
当使用 LangGraph API 时,您无需手动实现或配置存储。API 会在后台为您处理所有存储基础设施。
InMemoryStore 适用于开发和测试。对于生产环境,请使用持久化存储,如
PostgresStore、MongoDBStore 或 RedisStore。所有实现都扩展了 BaseStore,这是在节点函数签名中使用的类型注解。基本用法
首先,让我们在不使用 LangGraph 的情况下单独展示这一点。tuple 进行命名空间划分,在此特定示例中将是 (<user_id>, "memories")。命名空间可以是任意长度并表示任何内容,不一定是特定于用户的。
store.put 方法将记忆保存到存储中的命名空间。执行此操作时,我们指定如上定义的命名空间,以及记忆的键值对:键只是记忆的唯一标识符(memory_id),值(字典)是记忆本身。
store.search 方法读取命名空间中的记忆,该方法将返回给定用户的所有记忆作为列表。最近的记忆是列表中的最后一个。
Item),具有某些属性。我们可以通过如上所述的 .dict 转换将其作为字典访问。
它具有的属性有:
-
value:此记忆的值(本身是一个字典) -
key:此记忆在此命名空间中的唯一键 -
namespace:字符串元组,此记忆类型的命名空间虽然类型是tuple[str, ...],但在转换为 JSON 时可能会序列化为列表(例如,['1', 'memories'])。 -
created_at:此记忆创建时的时间戳 -
updated_at:此记忆更新时的时间戳
语义搜索
除了简单的检索,存储还支持语义搜索,允许您根据含义而不是精确匹配来查找记忆。为此,请使用嵌入模型配置存储:fields 参数或在存储记忆时指定 index 参数来控制记忆的哪些部分被嵌入:
在 LangGraph 中使用
所有这些就绪后,我们在 LangGraph 中使用存储。存储与检查点保存器协同工作:检查点保存器将状态保存到线程,如上所述,而存储允许我们存储任意信息以供_跨_线程访问。我们如下使用检查点保存器和存储编译图。thread_id 调用图,同时也使用 user_id,我们将使用它将记忆命名空间划分到这个特定用户,如上所示。
Runtime 对象在_任何节点_中访问存储和 user_id。当您将 Runtime 添加为节点函数的参数时,LangGraph 会自动注入它。以下是如何使用它来保存记忆的示例:
store.search 方法获取记忆。请记住,记忆作为对象列表返回,可以转换为字典。
user_id 相同,我们仍然可以访问相同的记忆。
langgraph.json 文件中配置索引设置。例如:
优化检查点存储
默认情况下,LangGraph 检查点在每个超级步骤写入每个状态通道的完整值。对于具有大量累积的长时间运行的线程——例如多轮对话——这可能会随时间产生显著的存储增长。DeltaChannel 仅存储增量差异,而不是完整的累积值,从而显著减少追加密集型通道的检查点大小。有关用法和存储与延迟的权衡,请参阅 DeltaChannel。
检查点保存器库
在底层,检查点保存由符合BaseCheckpointSaver 接口的检查点保存器对象提供支持。LangGraph 提供了多种检查点保存器实现,所有实现都通过独立的、可安装的库实现。
有关可用提供者,请参阅检查点保存器集成。
langgraph-checkpoint:检查点保存器保存器的基础接口(BaseCheckpointSaver)和序列化/反序列化接口(SerializerProtocol)。包括用于实验的内存检查点保存器实现(InMemorySaver)。LangGraph 自带langgraph-checkpoint。langgraph-checkpoint-sqlite:使用 SQLite 数据库的 LangGraph 检查点保存器实现(SqliteSaver/AsyncSqliteSaver)。适用于实验和本地工作流。需要单独安装。langgraph-checkpoint-postgres:使用 Postgres 数据库的高级检查点保存器(PostgresSaver/AsyncPostgresSaver),在 LangSmith 中使用。适用于生产环境。需要单独安装。langchain-azure-cosmosdb:使用 Azure Cosmos DB for NoSQL 的 LangGraph 检查点保存器实现(CosmosDBSaverSync/CosmosDBSaver)。适用于在 Azure 上生产使用。支持同步和异步操作,使用 Microsoft Entra ID 身份验证。需要单独安装。
检查点保存器接口
每个检查点保存器都符合BaseCheckpointSaver 接口,并实现以下方法:
.put- 存储检查点及其配置和元数据。.put_writes- 存储链接到检查点的中间写入(即待处理写入)。.get_tuple- 使用给定配置(thread_id和checkpoint_id)获取检查点元组。这用于填充graph.get_state()中的StateSnapshot。.list- 列出与给定配置和过滤条件匹配的检查点。这用于填充graph.get_state_history()中的状态历史记录。
.ainvoke、.astream、.abatch 执行图),则将使用上述方法的异步版本(.aput、.aput_writes、.aget_tuple、.alist)。
要异步运行图,您可以使用
InMemorySaver,或 Sqlite/Postgres 检查点保存器的异步版本——AsyncSqliteSaver / AsyncPostgresSaver 检查点保存器。序列化器
当检查点保存器保存图状态时,它们需要序列化状态中的通道值。这是使用序列化器对象完成的。langgraph_checkpoint 定义了实现序列化器的协议,并提供了一个默认实现(JsonPlusSerializer),可以处理多种类型,包括 LangChain 和 LangGraph 原语、日期时间、枚举等。
使用 pickle 进行序列化
默认序列化器 JsonPlusSerializer 在底层使用 ormsgpack 和 JSON,这并不适合所有类型的对象。
如果您希望对我们 msgpack 编码器当前不支持的对象(如 Pandas 数据帧)回退到 pickle,您可以使用 JsonPlusSerializer 的 pickle_fallback 参数:
加密
检查点保存器可以选择加密所有持久化的状态。要启用此功能,请将EncryptedSerializer 的实例传递给任何 BaseCheckpointSaver 实现的 serde 参数。创建加密序列化器的最简单方法是通过 from_pycryptodome_aes,它从 LANGGRAPH_AES_KEY 环境变量读取 AES 密钥(或接受 key 参数):
LANGGRAPH_AES_KEY,加密就会自动启用,因此您只需提供环境变量。可以通过实现 CipherProtocol 并将其提供给 EncryptedSerializer 来使用其他加密方案。
将这些文档连接到 Claude、VSCode 等,通过 MCP 获取实时答案。