

概述
LLM 支持的最强大的应用之一是复杂的问答(Q&A)聊天机器人。这些应用能够回答关于特定来源信息的问题。它们使用一种称为检索增强生成(Retrieval Augmented Generation,简称 RAG)的技术。 本教程将展示如何构建一个简单的问答应用,用于处理非结构化文本数据源。我们将演示:概念
我们将涵盖以下概念:- 索引:从数据源摄取数据并对其进行索引的管道。这通常在一个单独的过程中发生。
- 检索和生成:实际的 RAG 过程,它在运行时获取用户查询,从索引中检索相关数据,然后将其传递给模型。
预览
在本指南中,我们将构建一个回答网站内容问题的应用。我们将使用的特定网站是 Lilian Weng 的LLM 驱动的自主代理博客文章,这使我们能够就文章内容提问。 我们可以创建一个简单的索引管道和 RAG 链来完成此操作,大约需要 40 行代码。完整代码片段如下:展开查看完整代码片段
展开查看完整代码片段
设置
安装
本教程需要以下 langchain 依赖项:LangSmith
你使用 LangChain 构建的许多应用将包含多个步骤,并多次调用 LLM。随着这些应用变得越来越复杂,能够检查链或代理内部到底发生了什么变得至关重要。最好的方法是使用 LangSmith。 在上面的链接注册后,请确保设置环境变量以开始记录跟踪:组件
我们需要从 LangChain 的集成套件中选择三个组件。 选择一个聊天模型:- OpenAI
- Anthropic
- Azure
- Google Gemini
- AWS Bedrock
- HuggingFace
- OpenRouter
- OpenAI
- Azure
- Google Gemini
- Google Vertex
- AWS
- HuggingFace
- Ollama
- Cohere
- MistralAI
- Nomic
- NVIDIA
- Voyage AI
- IBM watsonx
- Fake
- Isaacus
- 内存中
- Amazon OpenSearch
- AstraDB
- Chroma
- FAISS
- Milvus
- MongoDB
- PGVector
- PGVectorStore
- Pinecone
- Qdrant
1. 索引
索引通常按以下方式工作:- 加载:首先我们需要加载数据。这通过文档加载器完成。
- 分割:文本分割器将大型
Document分割成更小的块。这对于索引数据和将其传递给模型都很有用,因为大块数据更难搜索,并且无法放入模型有限的上下文窗口中。 - 存储:我们需要一个地方来存储和索引我们的分块,以便稍后可以进行搜索。这通常使用向量存储和嵌入模型来完成。
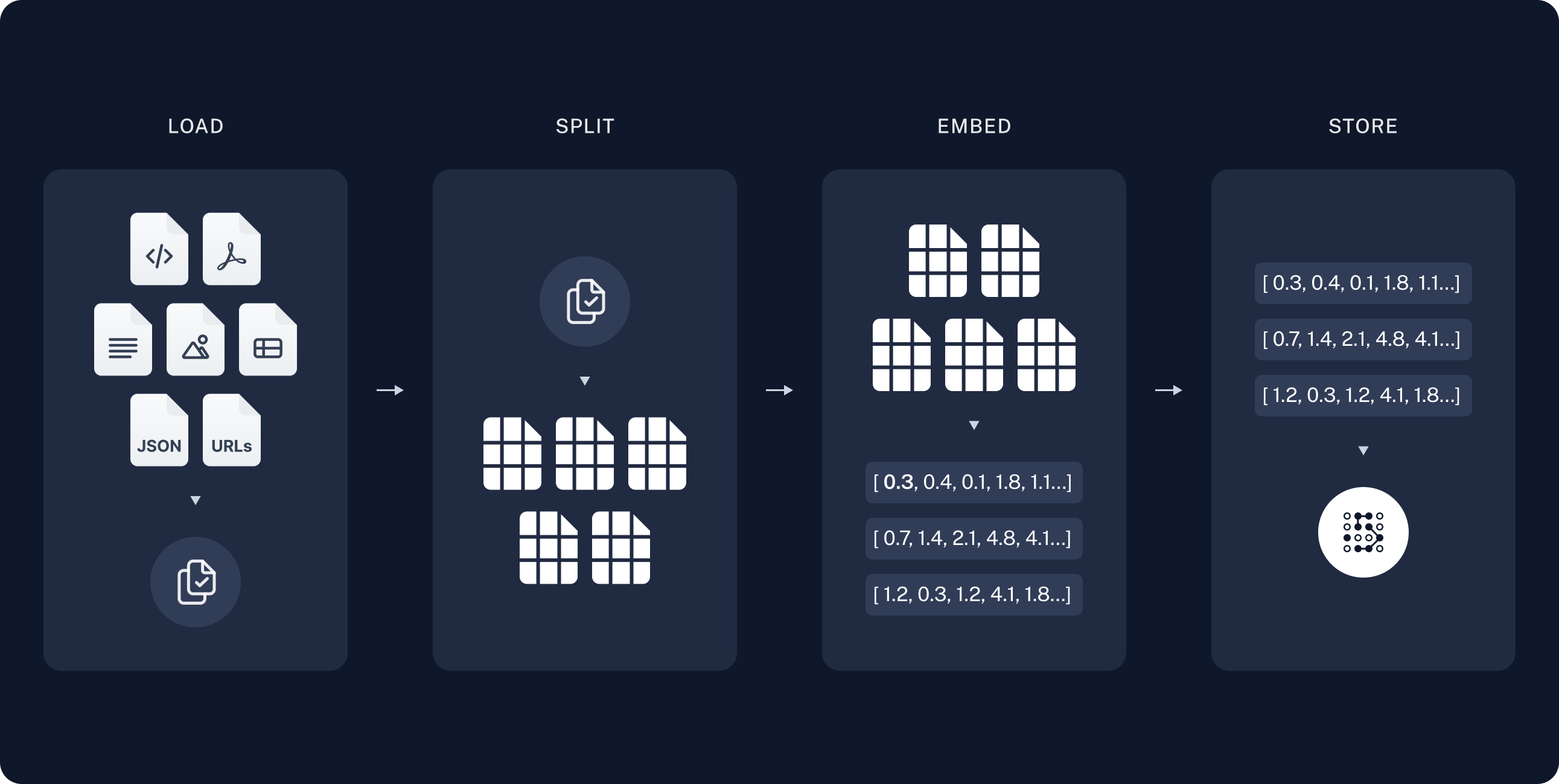
加载文档
我们需要首先加载博客文章内容。我们可以使用 DocumentLoaders 来完成,这些对象从数据源加载数据并返回一个 Document 对象列表。 在这种情况下,我们将使用WebBaseLoader,它使用 urllib 从网页 URL 加载 HTML,并使用 BeautifulSoup 将其解析为文本。我们可以通过 bs_kwargs 向 BeautifulSoup 解析器传递参数来自定义 HTML -> 文本解析(参见 BeautifulSoup 文档)。在这种情况下,只有 class 为 “post-content”、“post-title” 或 “post-header” 的 HTML 标签是相关的,因此我们将删除所有其他标签。
DocumentLoader:从数据源加载数据并作为 Documents 列表返回的对象。
- 集成:160 多个集成可供选择。
BaseLoader:基础接口的 API 参考。
分割文档
我们加载的文档超过 42k 个字符,太长而无法放入许多模型的上下文窗口中。即使对于那些可以将整篇文章放入其上下文窗口的模型,模型也可能难以在非常长的输入中找到信息。 为了处理这个问题,我们将把Document 分割成块,以便进行嵌入和向量存储。这应该有助于我们在运行时仅检索博客文章中最相关的部分。
与语义搜索教程一样,我们使用 RecursiveCharacterTextSplitter,它将使用常见的分隔符(如换行符)递归地分割文档,直到每个块达到适当的大小。这是通用文本用例的推荐文本分割器。
TextSplitter:将 Document 对象列表分割成更小块的对象,用于存储和检索。
存储文档
现在我们需要索引我们的 66 个文本块,以便在运行时可以对它们进行搜索。遵循语义搜索教程,我们的方法是嵌入每个文档分割的内容,并将这些嵌入插入到向量存储中。给定一个输入查询,我们可以使用向量搜索来检索相关文档。 我们可以使用在教程开始选择的向量存储和嵌入模型,通过单个命令嵌入和存储所有文档分割。Embeddings:文本嵌入模型的包装器,用于将文本转换为嵌入。
VectorStore:向量数据库的包装器,用于存储和查询嵌入。
这完成了管道的索引部分。此时,我们拥有一个可查询的向量存储,其中包含博客文章的分块内容。给定一个用户问题,我们理想情况下应该能够返回回答该问题的博客文章片段。
2. 检索和生成
RAG 应用通常按以下方式工作: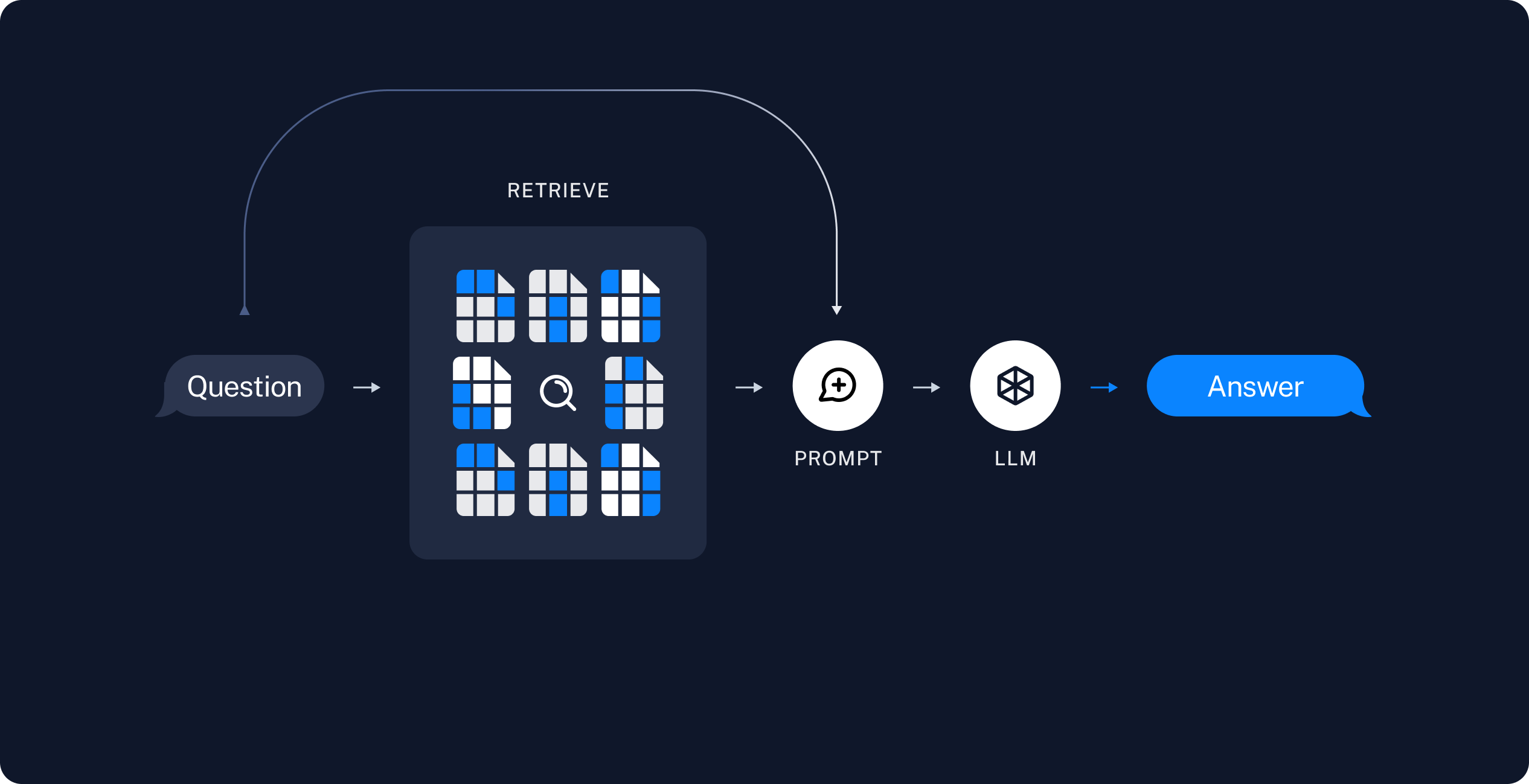
RAG 代理
RAG 应用的一种表述形式是一个简单的代理,带有一个检索信息的工具。我们可以通过实现一个包装我们向量存储的工具来组装一个最小的 RAG 代理:- 生成一个查询来搜索任务分解的标准方法;
- 收到答案后,生成第二个查询来搜索其常见扩展;
- 收到所有必要的上下文后,回答问题。
RAG 链
在上面的代理式 RAG 表述中,我们允许 LLM 自行决定生成工具调用以帮助回答用户查询。这是一个良好的通用解决方案,但也存在一些权衡:
另一种常见的方法是两步链,其中我们始终运行一次搜索(可能使用原始用户查询),并将结果作为单个 LLM 查询的上下文。这导致每次查询只有一次推理调用,以牺牲灵活性为代价换取更低的延迟。
在这种方法中,我们不再循环调用模型,而是进行单次传递。
我们可以通过从代理中移除工具,并将检索步骤合并到自定义提示中来实现此链:
返回源文档
返回源文档
安全:间接提示注入
为了缓解这个问题:- 使用防御性提示:明确指示模型将检索到的上下文仅视为数据,并忽略其中的任何指令。本教程中的提示包含此类指令。
- 用分隔符包裹上下文:使用清晰的结构标记(例如,像
<context>...</context>这样的 XML 标签)将检索到的数据与指令分开,使模型更容易区分它们。 - 验证响应:检查模型的输出是否符合预期格式(例如,纯文本),并优雅地处理意外格式。
后续步骤
现在我们已经通过create_agent 实现了一个简单的 RAG 应用,我们可以轻松地添加新功能并深入探索:
- 流式传输令牌和其他信息,以提供响应式的用户体验
- 添加对话记忆以支持多轮交互
- 添加长期记忆以支持跨对话线程的记忆
- 添加结构化响应
- 使用 LangSmith 部署部署你的应用
将这些文档通过 MCP 连接到 Claude、VSCode 等,以获取实时答案。