

概述
构建智能体(或任何 LLM 应用程序)的难点在于使其足够可靠。虽然它们可能适用于原型,但在实际用例中常常失败。智能体为何会失败?
当智能体失败时,通常是因为智能体内部的 LLM 调用采取了错误的操作/未执行我们预期的任务。LLM 失败的原因有两个:- 底层 LLM 能力不足
- 未向 LLM 传递“正确”的上下文
智能体循环
典型的智能体循环包含两个主要步骤:- 模型调用 - 使用提示词和可用工具调用 LLM,返回响应或执行工具的请求
- 工具执行 - 执行 LLM 请求的工具,返回工具结果
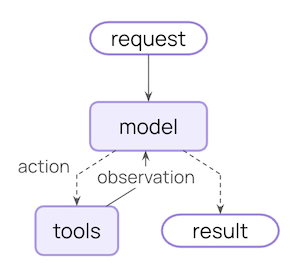
可控制的内容
要构建可靠的智能体,您需要控制智能体循环每个步骤中发生的事情,以及步骤之间发生的事情。临时上下文
LLM 在单次调用中看到的内容。您可以修改消息、工具或提示词,而无需更改保存在状态中的内容。
持久上下文
跨轮次保存在状态中的内容。生命周期钩子和工具写入会永久修改此内容。
数据源
在此过程中,您的智能体访问(读/写)不同的数据源:工作原理
LangChain 中间件是底层机制,使上下文工程对使用 LangChain 的开发者变得实用。 中间件允许您钩入智能体生命周期中的任何步骤,并:- 更新上下文
- 跳转到智能体生命周期中的不同步骤
模型上下文
控制进入每次模型调用的内容 - 指令、可用工具、使用哪个模型以及输出格式。这些决策直接影响可靠性和成本。系统提示词
开发者向 LLM 提供的基础指令。
消息
发送给 LLM 的完整消息列表(对话历史)。
工具
智能体可用于执行操作的实用程序。
模型
要调用的实际模型(包括配置)。
响应格式
模型最终响应的模式规范。
系统提示词
系统提示词设置 LLM 的行为和能力。不同的用户、上下文或对话阶段需要不同的指令。成功的智能体利用记忆、偏好和配置,为对话的当前状态提供正确的指令。- 状态
- 存储
- 运行时上下文
从状态访问消息计数或对话上下文:
消息
消息构成了发送给 LLM 的提示词。 管理消息的内容至关重要,以确保 LLM 拥有正确的信息来做出良好响应。- 状态
- 存储
- 运行时上下文
当与当前查询相关时,从状态注入上传的文件上下文:
工具
工具使模型能够与数据库、API 和外部系统交互。您定义和选择工具的方式直接影响模型能否有效完成任务。定义工具
每个工具都需要一个清晰的名称、描述、参数名称和参数描述。这些不仅仅是元数据——它们指导模型关于何时以及如何使用该工具的推理。选择工具
并非每个工具都适用于每种情况。工具太多可能会使模型不堪重负(上下文过载)并增加错误;工具太少则会限制能力。动态工具选择根据身份验证状态、用户权限、功能标志或对话阶段调整可用工具集。- 状态
- 存储
- 运行时上下文
仅在达到某些对话里程碑后启用高级工具:
模型
不同的模型具有不同的优势、成本和上下文窗口。为手头的任务选择合适的模型,这可能在智能体运行期间发生变化。- 状态
- 存储
- 运行时上下文
根据状态中的对话长度使用不同的模型:
响应格式
结构化输出将非结构化文本转换为经过验证的结构化数据。当提取特定字段或为下游系统返回数据时,自由格式文本是不够的。 工作原理: 当您提供模式作为响应格式时,模型的最终响应保证符合该模式。智能体运行模型/工具调用循环,直到模型完成调用工具,然后最终响应被强制转换为提供的格式。定义格式
模式定义指导模型。字段名称、类型和描述精确指定输出应遵循的格式。选择格式
动态响应格式选择根据用户偏好、对话阶段或角色调整模式——在早期返回简单格式,随着复杂性增加返回详细格式。- 状态
- 存储
- 运行时上下文
根据对话状态配置结构化输出:
工具上下文
工具的特殊之处在于它们既读取又写入上下文。 在最基本的情况下,当工具执行时,它接收 LLM 的请求参数并返回一条工具消息。工具执行其工作并产生结果。 工具还可以为模型获取重要信息,使其能够执行和完成任务。读取
大多数现实世界的工具需要的不仅仅是 LLM 的参数。它们需要用于数据库查询的用户 ID、用于外部服务的 API 密钥,或用于决策的当前会话状态。工具从状态、存储和运行时上下文读取以访问此信息。- 状态
- 存储
- 运行时上下文
从状态读取以检查当前会话信息:
写入
工具结果可用于帮助智能体完成给定任务。工具既可以将结果直接返回给模型,也可以更新智能体的记忆,以便为后续步骤提供重要的上下文。- 状态
- 存储
使用 Command 写入状态以跟踪特定于会话的信息:
生命周期上下文
控制核心智能体步骤之间发生的事情 - 拦截数据流以实现横切关注点,如摘要、防护栏和日志记录。 正如您在模型上下文和工具上下文中所看到的,中间件是使上下文工程变得实用的机制。中间件允许您钩入智能体生命周期中的任何步骤,并:- 更新上下文 - 修改状态和存储以持久化更改、更新对话历史或保存见解
- 在生命周期中跳转 - 根据上下文移动到智能体周期中的不同步骤(例如,如果满足条件则跳过工具执行,使用修改后的上下文重复模型调用)
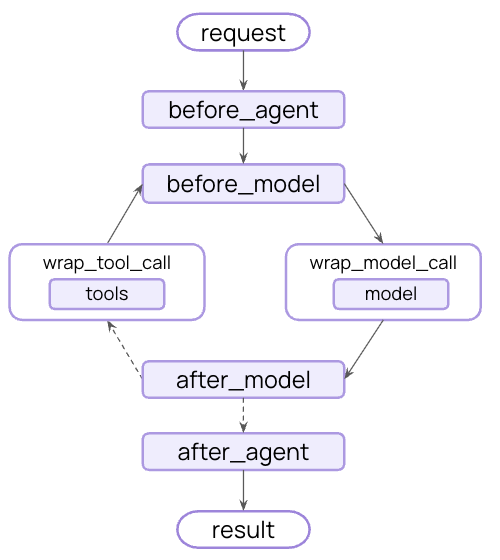
示例:摘要
最常见的生命周期模式之一是在对话历史过长时自动压缩。与模型上下文中显示的临时消息修剪不同,摘要持久地更新状态 - 用保存供所有未来轮次使用的摘要永久替换旧消息。 LangChain 提供了内置的中间件来实现此功能:SummarizationMiddleware 会自动:
- 使用单独的 LLM 调用总结较旧的消息
- 在状态中用摘要消息替换它们(永久)
- 保留最近的消息以保持上下文
有关内置中间件的完整列表、可用钩子以及如何创建自定义中间件,请参阅中间件文档。
最佳实践
- 从简单开始 - 从静态提示词和工具开始,仅在需要时添加动态内容
- 增量测试 - 一次添加一个上下文工程功能
- 监控性能 - 跟踪模型调用、令牌使用情况和延迟
- 使用内置中间件 - 利用
SummarizationMiddleware、LLMToolSelectorMiddleware等。 - 记录您的上下文策略 - 明确传递了什么上下文以及为什么传递
- 理解临时与持久:模型上下文更改是临时的(每次调用),而生命周期上下文更改会持久化到状态
相关资源
将这些文档通过 MCP 连接到 Claude、VSCode 等,以获取实时答案。