

subagents 参数中指定自定义子代理。子代理对于上下文隔离(保持主代理的上下文整洁)和提供专门指令非常有用。
本页介绍同步子代理,即主管家会阻塞直到子代理完成。对于长时间运行的任务、并行工作流,或需要中途调整和取消的情况,请参阅异步子代理。
为什么使用子代理?
子代理解决了上下文膨胀问题。当代理使用具有大量输出的工具(网络搜索、文件读取、数据库查询)时,上下文窗口会很快被中间结果填满。子代理隔离了这些详细工作——主代理只接收最终结果,而不是产生它的数十个工具调用。 何时使用子代理:- ✅ 会弄乱主代理上下文的多步骤任务
- ✅ 需要自定义指令或工具的专业领域
- ✅ 需要不同模型能力的任务
- ✅ 当你希望主代理专注于高层协调时
- ❌ 简单的单步任务
- ❌ 当你需要维护中间上下文时
- ❌ 当开销大于收益时
配置
subagents 应该是一个字典列表或 CompiledSubAgent 对象。有两种类型:
默认子代理
深度代理会自动添加一个同步的general-purpose 子代理,除非你已经提供了一个同名的同步子代理。
- 要替换它,请传递你自己的名为
general-purpose的子代理。 - 要重命名或重新提示自动添加的版本,请在活动的配置文件上设置
general_purpose_subagent=GeneralPurposeSubagentProfile(...)。 - 要禁用它,请参阅下面的不使用子代理运行。
不使用子代理运行
要运行一个没有task 工具的代理,请做两件事:
- 在活动的配置文件上设置
general_purpose_subagent=GeneralPurposeSubagentProfile(enabled=False)。 - 在
create_deep_agent上通过subagents=不传递任何同步子代理。
SubAgentMiddleware(和 task 工具)。如果没有默认的也没有调用者提供的,代理将在没有委派的情况下运行。
异步子代理不受影响——它们通过自己的中间件和工具运行,详见异步子代理。
SubAgent(基于字典)
对于大多数用例,将子代理定义为与SubAgent 规范匹配的字典,包含以下字段:
CompiledSubAgent
对于复杂工作流,使用预构建的 LangGraph 图作为CompiledSubAgent:
使用 SubAgent
使用 CompiledSubAgent
对于更复杂的用例,你可以使用CompiledSubAgent 提供自定义子代理。
你可以使用 LangChain 的 create_agent 或使用 graph API 创建自定义 LangGraph 图来创建自定义子代理。
如果你正在创建自定义 LangGraph 图,请确保图有一个名为 "messages" 的状态键:
流式传输
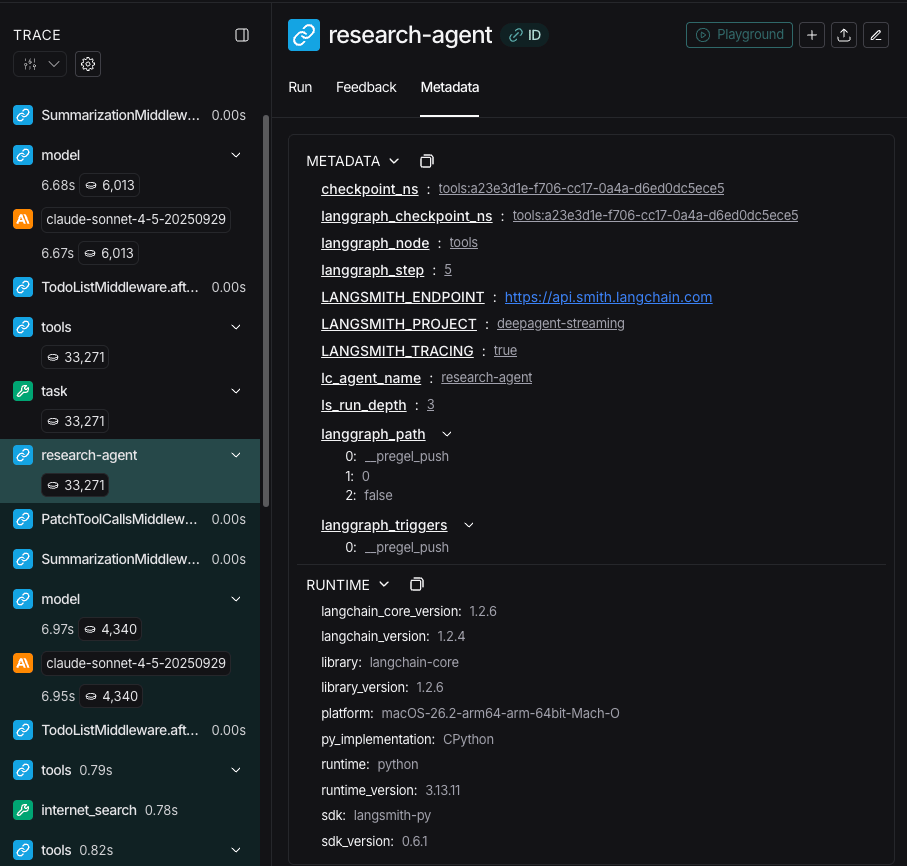
流式传输跟踪信息时,代理名称在元数据中作为lc_agent_name 可用。
查看跟踪信息时,你可以使用此元数据来区分数据来自哪个代理。
以下示例创建一个名为 main-agent 的深度代理和一个名为 research-agent 的子代理:
"research-agent" 的子代理将在任何相关的代理运行元数据中包含 {'lc_agent_name': 'research-agent'}:
结构化输出
子代理支持结构化输出,因此父代理接收可预测、可解析的 JSON,而不是自由格式的文本。子代理的结构化输出需要
deepagents>=0.5.3。response_format。当子代理完成时,其结构化响应被 JSON 序列化并作为 ToolMessage 内容返回给父代理。模式接受 create_agent 支持的任何内容:Pydantic 模型、ToolStrategy(...)、ProviderStrategy(...) 或原始模式类型。
response_format 时,父代理原样接收子代理的最后一条消息文本。有了它,父代理总是获得符合模式的有效 JSON,这在父代理需要以编程方式处理结果或将其传递给下游工具时很有用。
有关模式类型和策略(工具调用与提供者原生)的完整详细信息,请参阅结构化输出。
通用子代理
除了任何用户定义的子代理外,每个深度代理始终可以访问一个general-purpose 子代理。此子代理:
- 具有与主代理相同的系统提示
- 可以访问所有相同的工具
- 使用相同的模型(除非被覆盖)
- 从主代理继承技能(当配置了技能时)
覆盖通用子代理
在你的subagents 列表中包含一个 name="general-purpose" 的子代理以替换默认值。使用此方法为通用子代理配置不同的模型、工具或系统提示:
enabled 标志设置为 False。
何时使用它
通用子代理非常适合没有专门行为的上下文隔离。主代理可以将复杂的多步骤任务委派给此子代理,并获得简洁的结果,而不会因中间工具调用而膨胀。示例
与其让主代理进行 10
次网络搜索并用结果填充其上下文,不如委派给通用子代理:
task(name="general-purpose", task="Research quantum computing trends")。子代理在内部执行所有搜索,只返回摘要。技能继承
使用create_deep_agent 配置技能时:
- 通用子代理:自动从主代理继承技能
- 自定义子代理:默认不继承技能——使用
skills参数为它们提供自己的技能
只有配置了技能的子代理才会获得
SkillsMiddleware 实例——没有 skills
参数的自定义子代理不会。存在时,技能状态在两个方向上完全隔离:父代理的技能对子代理不可见,子代理的技能也不会传播回父代理。最佳实践
编写清晰的描述
主代理使用描述来决定调用哪个子代理。要具体: ✅ 好:"分析财务数据并生成带有置信度分数的投资见解"
❌ 坏: "处理财务事务"
保持系统提示详细
包括关于如何使用工具和格式化输出的具体指导:最小化工具集
只给子代理它们需要的工具。这提高了专注度和安全性:根据任务选择模型
不同的模型擅长不同的任务:返回简洁结果
指示子代理返回摘要,而不是原始数据:常见模式
多个专门子代理
为不同领域创建专门子代理:- 主代理创建高层计划
- 将数据收集委派给 data-collector
- 将结果传递给 data-analyzer
- 将见解发送给 report-writer
- 编译最终输出
上下文管理
当你使用运行时上下文调用父代理时,该上下文会自动传播到所有子代理。每个子代理运行都接收你在父invoke / ainvoke 调用上传递的相同运行时上下文。
这意味着在任何子代理内运行的工具都可以访问你提供给父代理的相同上下文值:
每个子代理的上下文
所有子代理接收相同的父上下文。要传递特定于某个子代理的配置,请使用命名空间键(在扁平context 映射中以子代理名称为前缀,例如 researcher:max_depth),或者将这些设置建模为上下文类型上的单独字段:
识别哪个子代理调用了工具
当同一个工具在父代理和多个子代理之间共享时,你可以使用lc_agent_name 元数据(与流式传输中使用的值相同)来确定哪个代理发起了调用:
runtime.context 读取代理特定的设置,并在分支工具行为时从 runtime.config 元数据读取 lc_agent_name。
故障排除
子代理未被调用
问题:主代理试图自己完成工作,而不是委派。 解决方案:-
使描述更具体:
-
指示主代理委派:
上下文仍然膨胀
问题:尽管使用了子代理,上下文仍然填满。 解决方案:-
指示子代理返回简洁结果:
-
对大数据使用文件系统:
选择了错误的子代理
问题:主代理为任务调用了不合适的子代理。 解决方案:在描述中清晰区分子代理:将这些文档连接到 Claude、VSCode 等,通过 MCP
获取实时答案。