

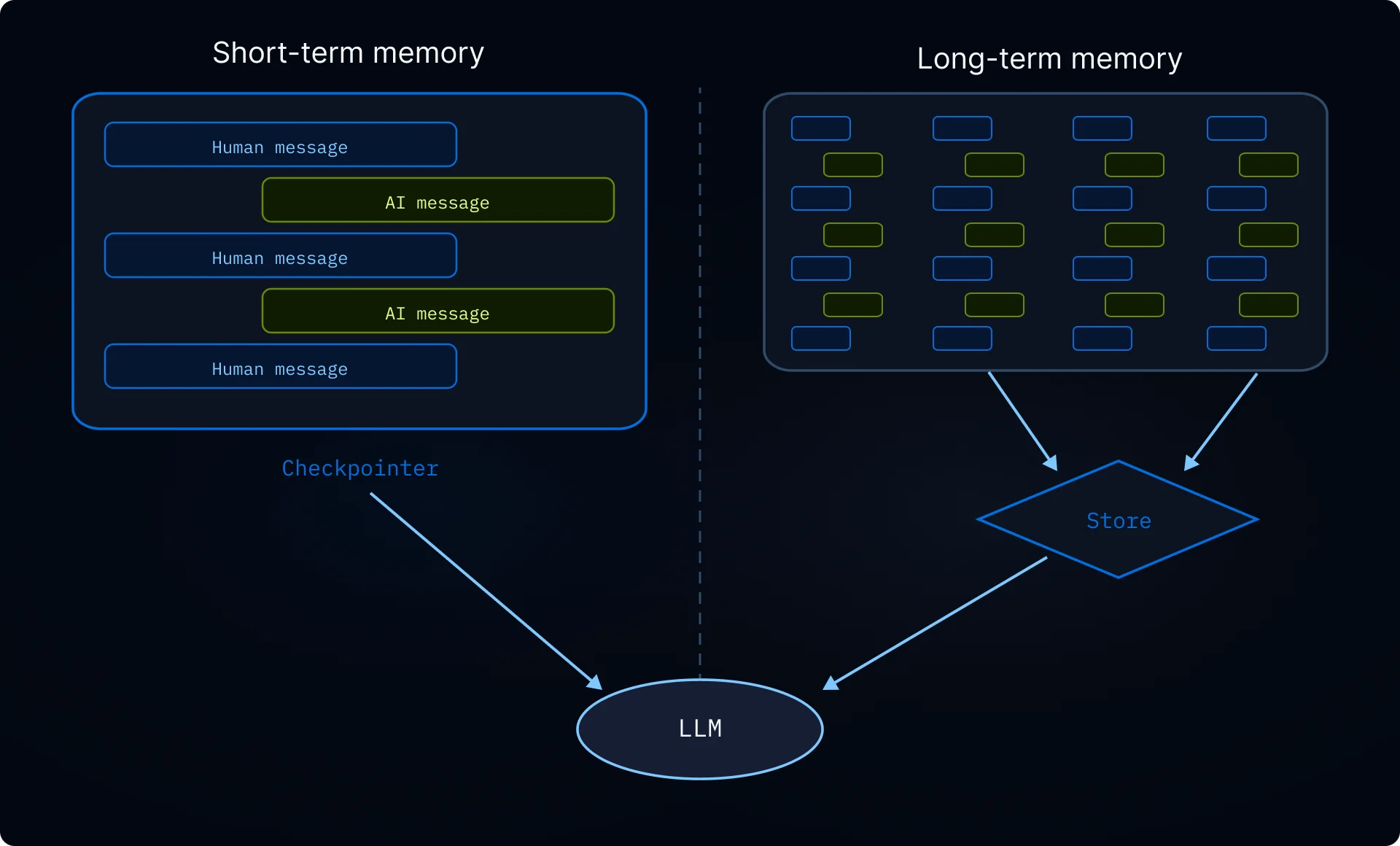
记忆的工作原理
- 将智能体指向记忆文件。 创建智能体时通过
memory=传递文件路径。你也可以通过skills=传递技能作为程序性记忆(告诉智能体如何执行任务的可重用指令)。后端控制文件的存储位置和访问权限。 - 智能体读取记忆。 智能体可以在启动时将记忆文件加载到系统提示中,或在对话过程中按需读取。例如,技能使用按需加载:智能体在启动时只读取技能描述,仅在匹配任务时才读取完整的技能文件。这使上下文保持精简,直到需要特定能力。
- 智能体更新记忆(可选)。 当智能体学到新信息时,可以使用内置的
edit_file工具更新记忆文件。更新可以在对话过程中(默认)或通过后台整合在对话之间后台进行。更改会被持久化并在下次对话中可用。并非所有记忆都是可写的:开发者定义的技能和组织策略通常是只读的。详情请参阅只读与可写记忆。
范围记忆
智能体记忆可以设置范围,使相同的记忆文件可被所有使用该智能体的用户访问,或者记忆文件可以为每个用户单独设置。智能体范围记忆
赋予智能体一个随时间演进的持久身份。智能体范围记忆在所有用户间共享,因此智能体通过每次对话积累自己的人格、知识和学习到的偏好。在与用户交互时,它会发展专业知识、完善方法并记住有效的方式。当拥有写入权限时,它还可以学习和更新技能。 关键是后端命名空间:将其设置为(assistant_id,) 意味着该智能体的每次对话都读写相同的记忆文件。
访问
rt.serverInfo 需要 deepagents>=1.9.0。在旧版本中,请从 getConfig().metadata.assistantId 读取助手 ID。完整示例:种子记忆和调用
完整示例:种子记忆和调用
用初始记忆填充存储,然后在两个线程中调用智能体,观察它如何记住并更新所学内容。
用户范围记忆
为每个用户提供自己的记忆文件。智能体记住每个用户的偏好、上下文和历史记录,同时核心智能体指令保持固定。如果存储在用户范围的后端中,用户也可以拥有各自的技能。 命名空间使用(user_id,),因此每个用户获得记忆文件的隔离副本。用户 A 的偏好永远不会泄露到用户 B 的对话中。
完整示例:跨用户的隔离记忆
完整示例:跨用户的隔离记忆
为每个用户设置种子记忆,并以两个不同用户身份调用智能体。每个用户只能看到自己的偏好。
高级用法
除了记忆路径和范围的基本配置选项外,你还可以为记忆配置更高级的参数:情景性记忆
情景性记忆存储过去经历的记录:发生了什么、按什么顺序发生以及结果如何。与语义性记忆(存储在AGENTS.md 等文件中的事实和偏好)不同,情景性记忆保留完整的对话上下文,使智能体能够回忆起问题如何被解决,而不仅仅是学到了什么。
Deep Agents 已经使用检查点,这是支持情景性记忆的机制:每次对话都作为检查点线程持久化。
为了使过去的对话可搜索,将线程搜索包装在一个工具中。user_id 从运行时上下文获取,而不是作为参数传递:
组织级记忆
组织级记忆遵循与用户范围记忆相同的模式,但使用组织范围的命名空间而不是每个用户的命名空间。用于应适用于组织中所有用户和智能体的策略或知识。 组织记忆通常是只读的,以防止通过共享状态进行提示注入。详情请参阅只读与可写记忆。后台整合
默认情况下,智能体在对话期间写入记忆(热路径)。另一种选择是在对话之间作为后台任务处理记忆,有时称为睡眠时间计算。一个单独的深度智能体审查最近的对话,提取关键事实,并将其与现有记忆合并。
对于大多数应用程序,热路径就足够了。当你需要减少延迟或提高跨多个对话的记忆质量时,添加后台整合。
推荐的模式是在主智能体旁边部署一个整合智能体——一个读取最近对话历史、提取关键事实并将其合并到记忆存储中的深度智能体——并按定时计划触发它。选择一个反映用户实际与智能体交互频率的节奏:具有稳定日常流量的聊天产品可能每几小时整合一次,而每周只使用几次的工具只需要每晚或每周运行一次。比用户对话频率高得多的整合只会浪费令牌在无操作运行上。
整合智能体
整合智能体读取最近的对话历史,并将关键事实合并到记忆存储中。在langgraph.json 中将其与主智能体一起注册:
src/consolidation-agent.ts
langgraph.json
定时任务
定时任务按固定计划运行整合智能体。智能体搜索最近的对话并将其综合到记忆中。使计划与使用模式匹配,以便整合运行大致跟踪实际活动。 使用定时任务安排整合智能体:所有定时计划均以 UTC
时间解释。有关管理和删除定时任务的详细信息,请参阅定时任务。
只读与可写记忆
默认情况下,智能体可以读写记忆文件。对于组织策略或合规规则等共享状态,你可能希望使记忆只读,以便智能体可以引用但不能修改它。这可以防止通过共享记忆进行提示注入,并确保只有你的应用程序代码控制文件中的内容。
安全考虑: 如果一个用户可以写入另一个用户读取的记忆,恶意用户可能会将指令注入共享状态。为缓解此问题:
- 默认使用用户范围
(user_id),除非你有特定原因需要共享 - 对共享策略使用只读记忆(通过应用程序代码填充,而不是智能体)
- 在智能体写入共享记忆之前添加Human in the Loop验证。使用中断要求对敏感路径的写入进行人工批准。
并发写入
多个线程可以并行写入记忆,但对同一文件的并发写入可能导致最后写入者获胜的冲突。对于用户范围记忆,这种情况很少见,因为用户通常一次只有一个活动对话。对于智能体范围或组织范围记忆,考虑使用后台整合来序列化写入,或将记忆结构化为每个主题的单独文件以减少争用。 实际上,如果写入因冲突而失败,LLM 通常足够智能可以重试或优雅恢复,因此单个丢失的写入不是灾难性的。同一部署中的多个智能体
要在共享部署中为每个智能体提供自己的记忆,请将assistant_id 添加到命名空间:
assistant_id。
将这些文档连接到 Claude、VSCode 等,通过 MCP
获取实时答案。